概要
2017/11/30 AWSで文字起こしのPaaSが発表された。
https://aws.amazon.com/jp/blogs/news/amazon-transcribe-scalable-and-accurate-automatic-speech-recognition/
招待制ということでさっそく申し込んだが、いつになってもAWSから承認が降りず、すっかり忘れ去った2018/2/13にAWSからPreview使っていいよ。というメールをもらった。

ちなみにGCPでは似たようなサービスが既にあり、この点においてはGCPがAWSをリードしている。
使い方
S3に音声ファイルを置く。
Amazon Transcribeがそれを読む。
自動で文字起こしされる。これだけ。
Amazon Transcribeの入力項目
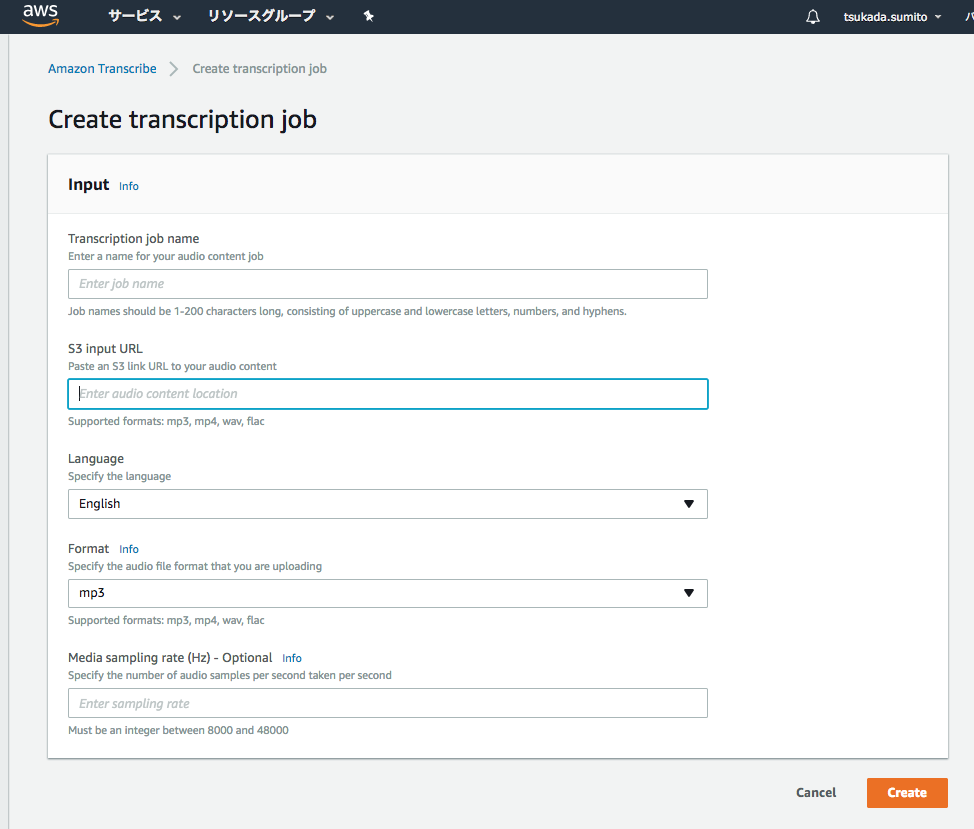
- ジョブ名を決める。
- S3のパスを入れる
- 変換元の言語を選択
- 音声フォーマットを選択
- レートを入力(必須ではない)
Amazon Transcribeの注意するところ
S3にバケットを掘る際、東京リージョンは対象外である。とりあえず米国東部(バージニア)にした。
変換元の音声は現時点で英語,スペイン語の文字起こししか対応していない。日本語は対象外。
音声ファイルはmp3,mp4,wav,flacファイルでなければならない。m4aは対象外。無理やりやってもエラーになるw
Amazon Transcribeから読めるようパーミッションを適宜設定する。
変換時間
約25分のmp3データを文字起こしするのに約25分かかった。
Output
Json形式で出力される。