はじめに
データサイエンスと機械学習において、データの前処理は非常に重要なステップです。特に、データのスケーリング(正規化と標準化)は、アルゴリズムのパフォーマンスに大きな影響を与えることがあります。ここでは、例としてtransactions.csv というデータセットを使用して、正規化と標準化の違いを具体的に説明します。
データセット
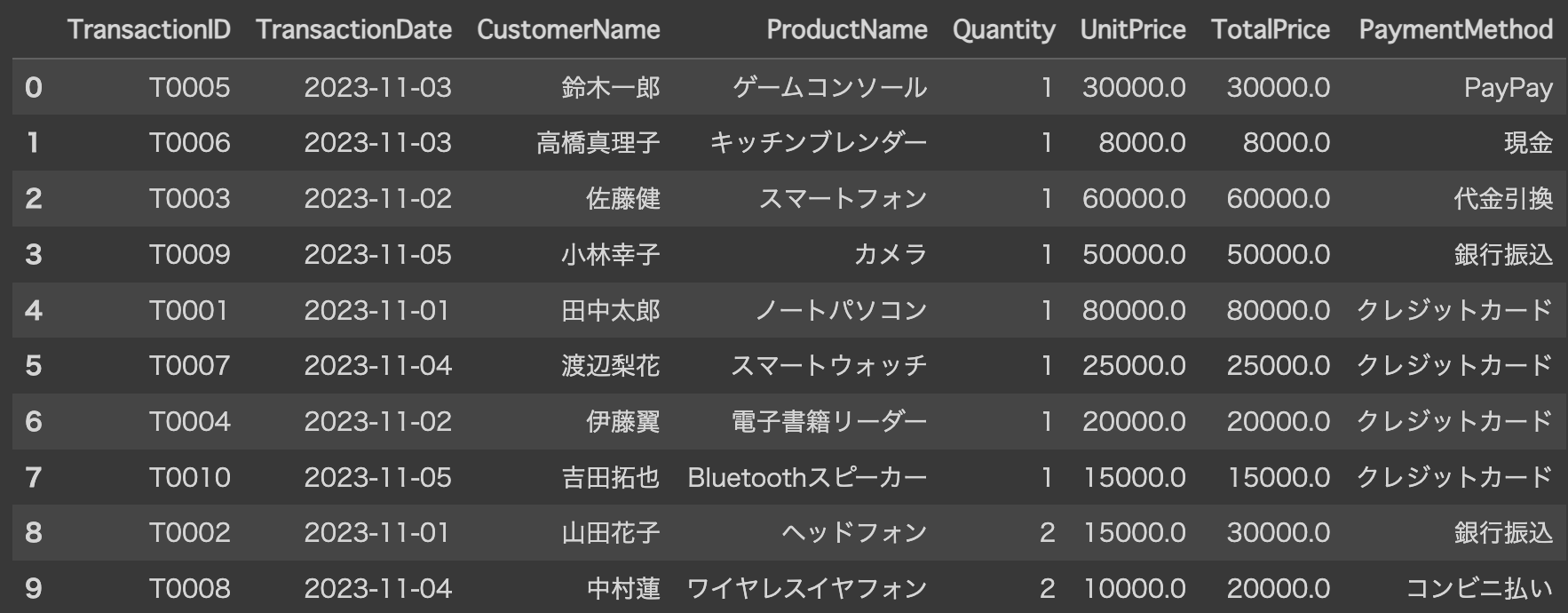
transactions.csv は、以下のような列を持つトランザクションデータです。
TransactionID: トランザクションID
TransactionDate: トランザクションの日付
CustomerName: 顧客の名前
ProductName: 商品名
Quantity: 数量
UnitPrice: 単価
TotalPrice: 合計価格
PaymentMethod: 支払い方法
正規化と標準化
正規化 (Normalization)
正規化は、データを0と1の間にスケーリングするプロセスです。これにより、異なるスケールを持つ変数間の比較を容易にします。例えば、0が最小値、1が最大値となるようにデータを変換します。一般的な正規化の式は次の通りです:
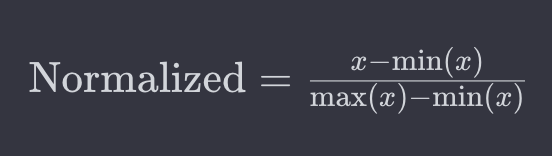
標準化 (Standardization)
標準化は、データの平均を0、標準偏差を1に変換するプロセスです。これにより、データは正規分布に近い形になります。標準化の一般的な式は以下です:

ここで μ は平均、σ は標準偏差です。
Pythonでの実装
以下のPythonコードは、Quantity と UnitPrice 列に対して正規化と標準化を実行します。
import pandas as pd
from sklearn.preprocessing import MinMaxScaler, StandardScaler
transactions_data = pd.read_csv('transactions.csv')
# 正規化と標準化のためのスケーラーの初期化
min_max_scaler = MinMaxScaler()
standard_scaler = StandardScaler()
# 正規化
transactions_data['Normalized_Quantity'] = min_max_scaler.fit_transform(transactions_data[['Quantity']])
transactions_data['Normalized_UnitPrice'] = min_max_scaler.fit_transform(transactions_data[['UnitPrice']])
# 標準化
transactions_data['Standardized_Quantity'] = standard_scaler.fit_transform(transactions_data[['Quantity']])
transactions_data['Standardized_UnitPrice'] = standard_scaler.fit_transform(transactions_data[['UnitPrice']])
このコードでは、データセット内の Quantity と UnitPrice 列をそれぞれ正規化および標準化します。MinMaxScaler と StandardScaler は、それぞれ正規化と標準化を行うためのscikit-learnライブラリのクラスです。
出力例
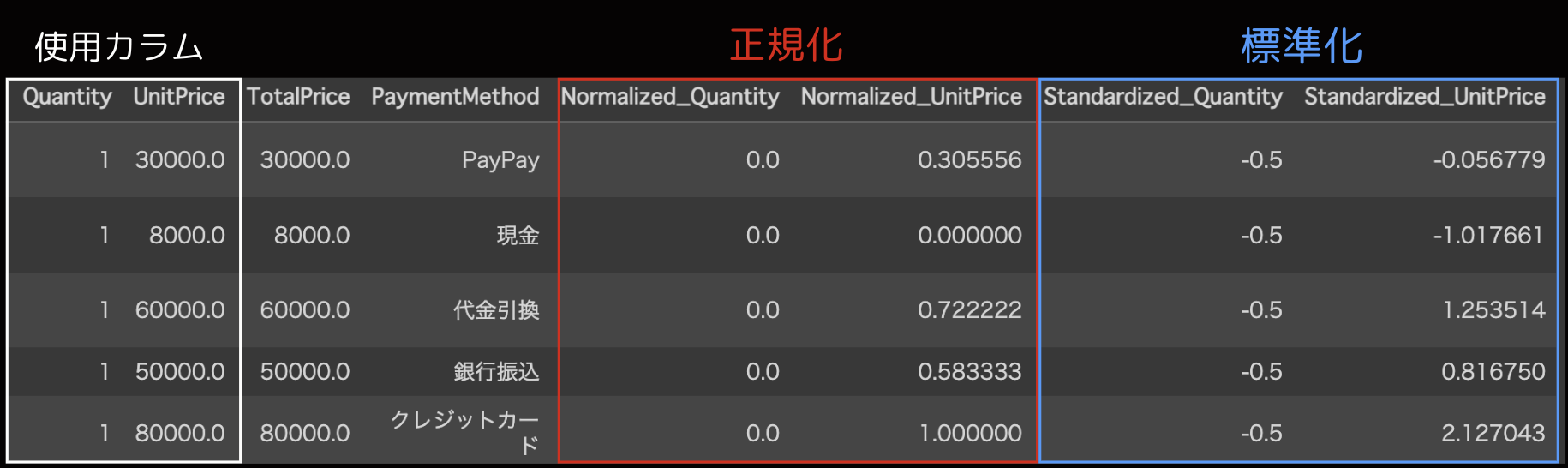
Normalized_Quantity と Normalized_UnitPrice 列は、それぞれ正規化された Quantity と UnitPrice の値を示しています。このデータでは Quantity 列のすべての値が同じため、正規化後の値もすべて0になっています。
またStandardized_Quantity とStandardized_UnitPrice 列は、それぞれ標準化された Quantity と UnitPrice の値を示しています。
標準化では、データの平均が0、標準偏差が1になるように変換されます。
このデータでは Quantity 列の平均が1に近く、標準偏差が小さいため、標準化後の値はほぼ -0.5 になっています。
まとめ
正規化と標準化は、データを異なる尺度に変換することで、機械学習アルゴリズムのパフォーマンスを向上させることができます。どちらの手法を使用するかは、データの特性と使用するアルゴリズムによって異なります。この記事が、これらの重要な前処理ステップの違いを理解するのに役立つことを願っています。