
はじめに
2023年12月14日、Googleは生成AIモデルであるGeminiのAPI利用を開始しました。このAPIを活用することで、テキスト生成や画像解釈のタスクを自動化し、さまざまなアプリケーションでAIの力を活かすことができます。この記事を通して、Gemini APIの使い方について紹介し、新しい創造的なプロジェクトやアイデアの実現に向けて一歩踏み出すお手伝いができればと思います。
ステップ1: Geminiの準備
まず、Geminiを使えるように準備します。以下のコードで必要なパッケージのインストール、設定、お義を行います。
!pip install -q -U google-generativeai
import pathlib
import textwrap
import google.generativeai as genai
from google.colab import userdata
from IPython.display import display
from IPython.display import Markdown
def to_markdown(text):
text = text.replace('•', ' *')
return Markdown(textwrap.indent(text, '> ', predicate=lambda _: True))
次にAPIキーの設定を行います。

Google AI Studio(https://ai.google.dev/?hl=ja)
からAPIキーを取得し以下のように貼り付けます。
your_api_key の部分をご自身のAPIキーに置き換えてください。
genai.configure(api_key="your_api_key")
ステップ2: テキストの生成
次に、Geminiを使ってテキストを生成するステップを行います。以下のコードは、Geminiのテキスト生成モデルを用意し、指定したテキストに対する応答を生成する例です。
# モデルを準備
model = genai.GenerativeModel('gemini-pro')
response = model.generate_content("あなたはGemini?あなたにできることを5つ教えて?")
to_markdown(response.text)
上記のコードを実行すると、Geminiが指定したテキストに対して生成した応答がMarkdown形式で表示されます。
出力

ステップ3: Visionの使用
Geminiを使って画像解釈を行うステップを実行します。以下のコードは、GeminiのVisionモデルを用意し、指定した画像から情報を抽出する例です。
# モデルを準備
model = genai.GenerativeModel('gemini-pro-vision')
今回は例として、適当に作成した売り上げ推移グラフをインポートして、グラフの概要を抽出してみます。
import PIL.Image
#インポートした画像を読み込み
img = PIL.Image.open('/content/画像のパス')
img
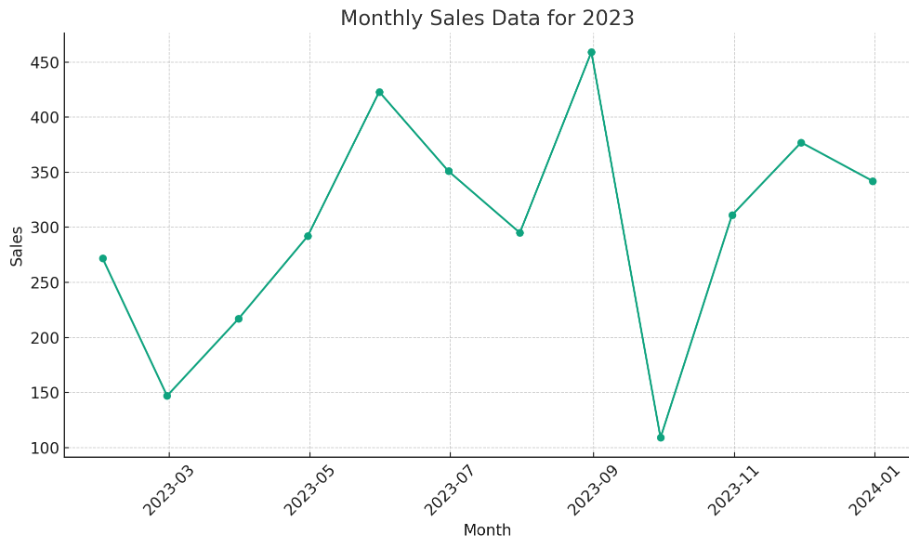
response = model.generate_content([
"このグラフからサマリーを抽出して",
img
], stream=True)
response.resolve()
to_markdown(response.text)
出力

最後に
この記事を通じて、Geminiの準備、テキストの生成、Visionの使用についての基本的な手順を紹介しました。Geminiは強力なツールであり、さまざまな応用が可能です。ぜひこの記事を参考にして、Geminiを活用してテキスト生成と画像解釈を実践してみてください。