
はじめに
この記事では、OpenAIのWhisperAPIを使用して音声ファイルをテキストに変換し、さらにそのテキストを処理する「音声解析アプリ」の作成方法についてステップバイステップで説明します。PythonとStreamlitを用いて、ユーザーフレンドリーなウェブアプリを構築します。
ステップ1: 開発環境の準備
まずは、必要なPythonパッケージをインストールします。これにはstreamlit、python-dotenv、openaiが含まれます。
pip install streamlit python-dotenv openai
これらのライブラリにより、ウェブアプリの構築、環境変数の管理、OpenAI APIの呼び出しが可能になります。
ステップ2: .envファイルの設定
安全にAPIキーを管理するために、プロジェクトのルートに.envファイルを作成し、OpenAI APIキーを以下の形式で保存します。
OPENAI_API_KEY=APIキー
ステップ3: アプリケーションの基本設定
Streamlitを使用して、アプリケーションの基本的なフレームワークを設定します。まずはアプリのタイトルとAPIキーの入力を設定します。
import streamlit as st
from dotenv import load_dotenv
import os
# 環境変数を読み込む
load_dotenv()
# アプリのタイトルを設定
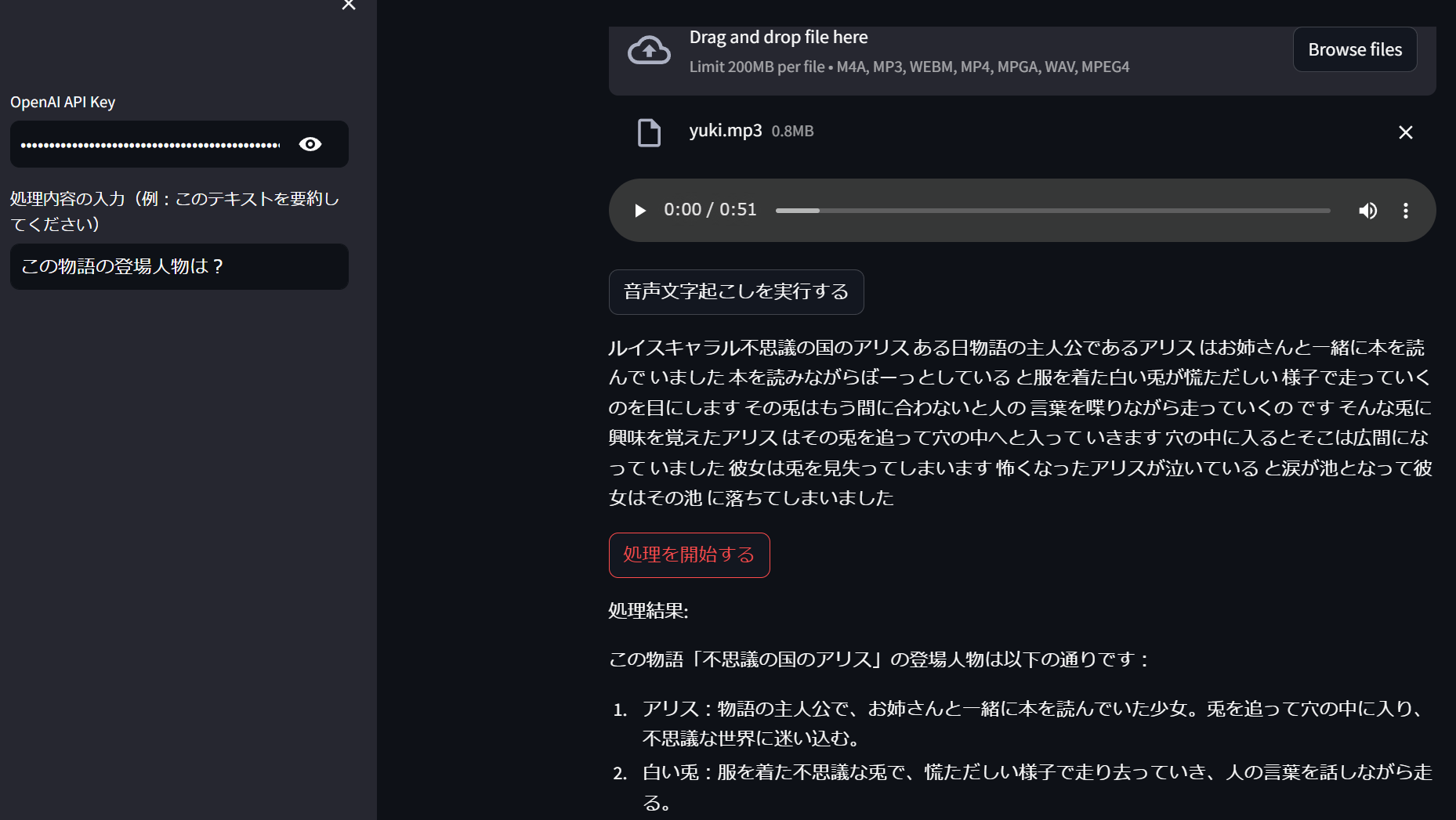
st.title("音声解析アプリ")
# APIキーの入力欄をサイドバーに設置
api_key = st.sidebar.text_input("OpenAI API Key", type="password", value=os.getenv("OPENAI_API_KEY") or "")
if not api_key:
st.error("サイドバーからAPIキーを入力してください。")
st.stop()
ステップ4: 音声ファイルのアップロード
ユーザーが音声ファイルをアップロードできるように設定します。対応するファイル形式を指定して、ファイルアップローダーを追加します。
# 音声ファイルのアップロード
audio_file = st.file_uploader("音声ファイルをアップロードしてください", type=["m4a", "mp3", "webm", "mp4", "mpga", "wav"])
ステップ5: 音声ファイルの文字起こし
WhisperAPIを使用して、アップロードされた音声ファイルをテキストに変換します。このステップでは、OpenAIライブラリを用いてAPI呼び出しを行います。
from openai import OpenAI
# OpenAIクライアントの初期化
client = OpenAI(api_key=api_key)
# 音声ファイルがアップロードされた場合
if audio_file is not None:
if st.button("音声文字起こしを実行する"):
with st.spinner("音声文字起こしを実行中です..."):
# WhisperAPIを使って音声をテキストに変換
transcript = client.audio.transcriptions.create(
model="whisper-1", file
audio_file, response_format="text"
)
# 変換結果を表示
st.success("音声文字起こしが完了しました!")
st.text(transcript["text"]) # 文字起こし結果をテキストとして表示
このコードスニペットは、ユーザーがアップロードした音声ファイルを受け取り、OpenAIクライアントを使用してWhisperAPIに送信し、テキストに変換します。変換が完了すると、結果がアプリケーションに表示されます。
ステップ6: テキストの処理と分析
文字起こしされたテキストに対して、ユーザーが指定した処理を実行します。例えば、テキストの要約や感情分析などです。ここでは、GPTを使ったテキスト処理の例を示します。
# テキスト処理の指示をユーザーから受け取る
process_instruction = st.sidebar.text_input("処理内容の入力(例:このテキストを要約してください)")
# 処理を開始するボタン
if st.button("処理を開始する"):
if transcript: # 文字起こし結果が存在する場合
with st.spinner("テキスト処理を実行中です..."):
# GPTを使ってテキスト処理
response = client.chat.completions.create(
model="gpt-3.5-turbo",
messages=[
{"role": "system", "content": "ユーザーのプロンプトに基づき回答を生成してください"},
{"role": "user", "content": process_instruction + transcript["text"]}
]
)
processed_text = response.choices[0].message.content
# 処理結果を表示
st.write("処理結果:")
st.write(processed_text)
else:
st.warning("音声文字起こしの結果がありません。先に音声文字起こしを行ってください。")
このコードは、サイドバーに指示を入力するテキストボックスを追加し、ユーザーが「処理を開始する」ボタンをクリックしたときに、文字起こし結果に対して指定された処理を実行します。処理が完了すると、その結果がアプリケーションに表示されます。
まとめ
この記事では、OpenAIのWhisperAPIを活用して音声ファイルをテキストに変換し、そのテキストをさらに処理する「音声解析アプリ」の作成方法を紹介しました。Streamlitを使用してウェブアプリケーションを構築し、ユーザーが簡単に音声ファイルをアップロードして処理結果を得られるようにしました。この基本的なフレームワークをもとに、さまざまな応用が可能です。例えば、特定のテーマに関する情報抽出、言語学習アプリケーションへの応用など、想像力次第で幅広い用途に利用できます。