
はじめに
データオーケストレーションは、現代のデータエコシステムにおいて中核的な役割を担っています。中でもDagsterは複雑なデータワークフローの管理を容易にし、dbtはデータウェアハウスでのデータ変換を効率的に行います。この二つのツールをDocker環境下で組み合わせることで、データウェアハウス上でのデータ処理を効果的にオーケストレートし、データの整合性を保ちます。
本記事では、Dagsterとdbtを組み合わせてデータパイプラインのオーケストレーションを行う方法について解説します。
dbt coreの環境構築
VSCode上でターミナルを開き任意のディレクトリを作成します。
mkdir docker_dbt_dag
以下のディレクトリ構成を作成します。
docker_dbt_dag
|-- Dockerfile
|-- docker-compose.yml
Dockerfileに以下の内容を入れます。必要なパッケージなどはここでインストールします。
FROM python:3.12.0
USER root
# Install system
RUN apt-get update && \
apt-get -y install locales vim less && \
localedef -f UTF-8 -i ja_JP ja_JP.UTF-8
# Set locale environment
ENV LANG ja_JP.UTF-8
ENV LANGUAGE ja_JP:ja
ENV LC_ALL ja_JP.UTF-8
ENV TERM xterm
# Upgrade pip and setuptools
RUN pip install --upgrade pip setuptools
# Install dbt-bigquery and dagster-dbt
RUN pip install dbt-bigquery
RUN pip install dagster-dbt dagster-webserver
docker-compose.ymlに以下の内容を入れます。
version: '3'
services:
dbt-core:
restart: always
build: .
container_name: 'docker_dbt'
working_dir: '/root/'
tty: true
コンテナの作成と起動
下記コマンドを実行しコンテナを起動します。
docker compose up -d --build
コンテナ起動後、リモートエクスプローラー(📺><)から、アタッチボタン(→)をクリックしてコンテナに入ります。

⬇︎
コンテナに無事入れたらdbtコマンドの確認をしておきます。
dbt --version
以下のように表示されていれば成功です。
Core:
- installed: 1.7.13
- latest: 1.7.13 - Up to date!
Plugins:
- bigquery: 1.7.7 - Up to date!
次にdbt coreからBigQueyを操作するためのサービスアカウントを作成します。
詳細はこちらから:GoogleCloudで秘密鍵を作成してみよう
GoogleCloudのコンソール画面へ移動
↓
「APIとサービス」へ移動
↓
「認証情報」から「認証情報を作成」をクリック
↓
サービスアカウントをクリック
↓
サービスアカウントの詳細を入力後、作成して続行をクリック
↓
ロールを選択する。「BigQueryに必要な権限を付与」
↓
作成されたサービスアカウントをクリックして「キー」タブ選択し、「鍵を追加」から「新しい鍵を作成」をクリックしJSON形式で保存。
dbtプロジェクトの初期化
dbtの初期化は、新しいプロジェクトのセットアップを開始する最初のステップです。以下のコマンドを実行することで、指定した名前のディレクトリ内にdbtプロジェクトが生成されます。
dbt init dbt_core
またプロジェクトを削除する必要がある場合は、次のコマンドを使用することで安全に削除できます。
rm -rf dbt_core
BigQueryとの接続設定
dbtプロジェクトの初期化後、BigQueryとの接続を設定するための一連の質問に回答します。これには、プロジェクトID、データセット名、認証方法などが含まれます。設定が完了した後でも、「.dbt」ディレクトリ下の 「profiles.yml」ファイルを編集することで、接続設定をカスタマイズすることが可能です。今回は以下のように設定しています。
dbt_core:
outputs:
dev:
dataset: dbt_dag
job_execution_timeout_seconds: 300
job_retries: 1
#今回サービスアカウントキーのjsonファイルはdbt_core(dbtプロジェクト)配下に置いています。
keyfile: /root/dbt_core/data-sandbox.json
location: asia-northeast1
method: service-account
priority: interactive
project: data-sandbox
threads: 1
type: bigquery
target: dev
dbt debugコマンドで正しくBiqQueryと接続されているか確認することができます。
dbt debug
以下のように返ってくれば問題ありません。

❄️Snowflakeの場合(profiles.yml)
dbt_core:
outputs:
dev:
account: 'アカウント情報'
database: '使用するデータベース'
password: 'パスワード'
role: '使用するロール'
schema: '使用するスキーマ'
threads: 1 # 同時実行するスレッド数
type: snowflake
user: 'Snowflakeユーザー'
warehouse: '使用するウェアハウス'
target: dev
アカウント情報はアカウントURLからhttps://().snowflakecomputing.com を抜いた ()内 の情報です。

Dagsterプロジェクトの作成
dbtプロジェクト内でDagsterプロジェクトを設定することで、データパイプラインのオーケストレーションが可能になります。次のコマンドでdbtのプロジェクトに移動しDagsterプロジェクトを作成します。
cd dbt_core
dagster-dbt project scaffold --project-name dbt_dagster
この手順により、Dagsterの構成とdbtの設定が組み合わされます。
サンプルデータの作成
プロジェクトの構成と接続設定が完了した後、実際のデータモデリングを始める前に、サンプルとして使用する架空のトランザクションデータをBigQuery上で作成します。
CREATE TABLE `プロジェクトID.データセット名.test_transactions` (
TransactionID STRING,
TransactionDate DATE,
CustomerName STRING,
ProductName STRING,
Quantity INT64,
UnitPrice NUMERIC,
TotalPrice NUMERIC,
PaymentMethod STRING
);
INSERT INTO `プロジェクトID.データセット名.test_transactions` (TransactionID, TransactionDate, CustomerName, ProductName, Quantity, UnitPrice, TotalPrice, PaymentMethod) VALUES
('T0005', '2023-11-03', '鈴木一郎', 'ゲームコンソール', 1, 30000.0, 30000.0, 'PayPay'),
('T0006', '2023-11-03', '高橋真理子', 'キッチンブレンダー', 1, 8000.0, 8000.0, '現金'),
('T0003', '2023-11-02', '佐藤健', 'スマートフォン', 1, 60000.0, 60000.0, '代金引換'),
('T0009', '2023-11-05', '小林幸子', 'カメラ', 1, 50000.0, 50000.0, '銀行振込'),
('T0001', '2023-11-01', '田中太郎', 'ノートパソコン', 1, 80000.0, 80000.0, 'クレジットカード'),
('T0007', '2023-11-04', '渡辺梨花', 'スマートウォッチ', 1, 25000.0, 25000.0, 'クレジットカード'),
('T0004', '2023-11-02', '伊藤翼', '電子書籍リーダー', 1, 20000.0, 20000.0, 'クレジットカード'),
('T0010', '2023-11-05', '吉田拓也', 'Bluetoothスピーカー', 1, 15000.0, 15000.0, 'クレジットカード'),
('T0002', '2023-11-01', '山田花子', 'ヘッドフォン', 2, 15000.0, 30000.0, '銀行振込'),
('T0008', '2023-11-04', '中村蓮', 'ワイヤレスイヤフォン', 2, 10000.0, 20000.0, 'コンビニ払い');
BigQuery内で正しくテーブルが作成されたことを確認します。
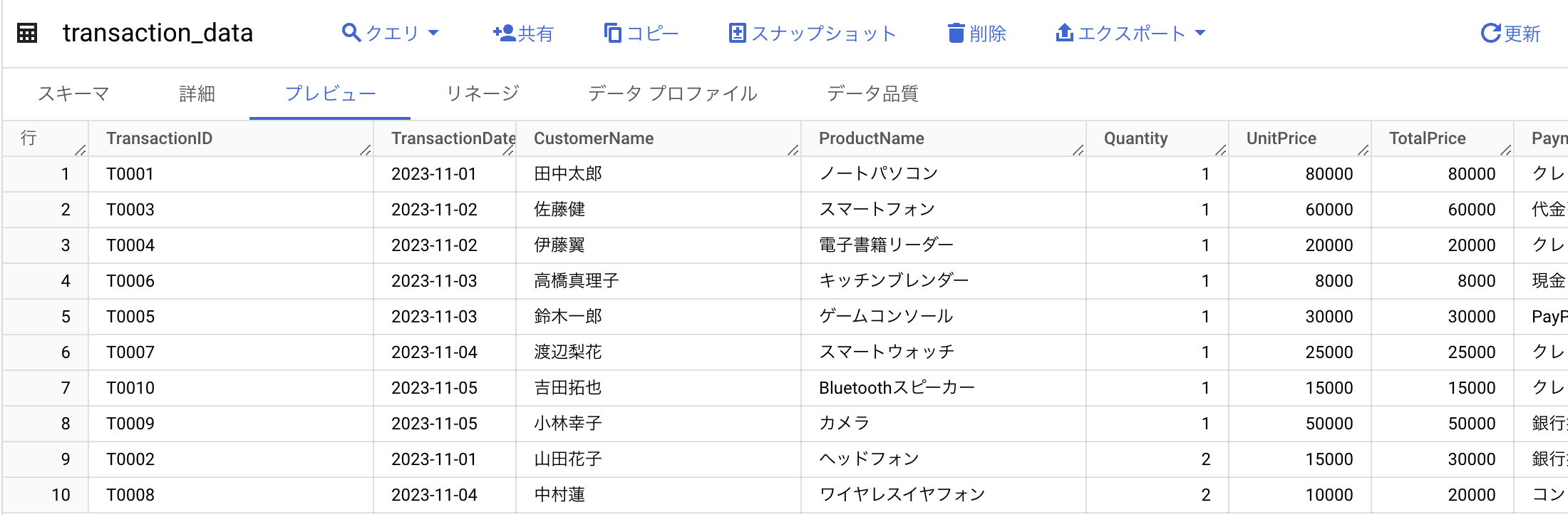
SQLファイルの作成
次に、dbtで使用する簡単なSQLファイル(dbtモデル)を作成します。
通常、dbtプロジェクトでは、データの変換プロセスに応じて raw, staging, intermediate, mart など複数のディレクトリに分けて管理します。これにより、各ステージのデータ変換の役割を明確にし、データの流れを容易に追跡できます。
ですが、今回の目的はdbtを使用して簡単に依存関係を確認することであるため、複雑なディレクトリ構造を省略し、SQLファイルのみで簡単なディメンショナルモデリングを行います。以下のSQLファイルをmodels配下に作成していきます。
また各モデルに対して schema.yml ファイルを作成し、その中でモデルのカラムや関連するテストを定義します。
顧客ディメンションモデル(dim_customers.sql)
{{ config(materialized='table') }}
with source_data as (
select distinct CustomerName as customer_name
from `dbt_dag.transaction_data`
)
select
row_number() over (order by customer_name) as customer_id,
customer_name
from source_data
対応する customers.yml
version: 2
models:
- name: dim_customers
description: "顧客ディメンションモデル。顧客の一意の識別子と名前を提供します。"
columns:
- name: customer_id
description: "一意の顧客ID。"
tests:
- unique
- not_null
- name: customer_name
description: "顧客の名前。"
tests:
- not_null
製品ディメンションモデル(dim_products.sql)
{{ config(materialized='table') }}
with source_data as (
select distinct ProductName as product_name, UnitPrice as unit_price
from `dbt_dag.transaction_data`
)
select
row_number() over (order by product_name) as product_id,
product_name,
unit_price
from source_data
対応する products.yml
version: 2
models:
- name: dim_products
description: "製品ディメンションモデル。製品の一意の識別子、名前、および単価を提供します。"
columns:
- name: product_id
description: "一意の製品ID。"
tests:
- unique
- not_null
- name: product_name
description: "製品名。"
tests:
- not_null
- name: unit_price
description: "製品の単価。"
tests:
- not_null
売上ファクトモデル(fact_sales.sql)
{{ config(materialized='table') }}
with customer_dimension as (
select * from {{ ref('dim_customers') }}
),
product_dimension as (
select * from {{ ref('dim_products') }}
),
source_data as (
select
TransactionID as transaction_id,
TransactionDate as transaction_date,
CustomerName,
ProductName,
Quantity as quantity,
TotalPrice as total_price
from `dbt_dag.transaction_data`
)
select
sd.transaction_id,
sd.transaction_date,
cd.customer_id,
pd.product_id,
sd.quantity,
sd.total_price
from source_data sd
join customer_dimension cd on sd.CustomerName = cd.customer_name
join product_dimension pd on sd.ProductName = pd.product_name
対応する sales.yml
version: 2
models:
- name: fact_sales
description: "売上ファクトモデル。取引の詳細と顧客、製品の関連情報を提供します。"
columns:
- name: transaction_id
description: "取引ID。"
tests:
- unique
- not_null
- name: transaction_date
description: "取引日。"
tests:
- not_null
- name: quantity
description: "取引数量。"
tests:
- not_null
- name: total_price
description: "総取引価格。
モデルの実行について
dbt runですべてのモデルの実行が可能になりますが、--models 後に実行したいSQLを入れることで特定のモデル実行が可能になります。
dbt run --models <model_name>
ここで、model_name は実行したいモデルの名前です。例えば、dim_products.sql という名前のモデルを実行する場合は次のようになります。
dbt run --models dim_products
また、特定のファイルパスを指定してモデルを実行する場合は以下のようにします。
dbt run --models <path_to_model_file>
例えば、models/example/dim_products.sqlというパスにあるモデルを実行する場合は次のようになります。
dbt run --models example.dim_products
成功時の出力

失敗時の出力(PASS=0、ERROR=4となっている)

dbt testについて
dbt test コマンドは、DBTモデルに対して定義されたテストを実行します。これには、データの品質や一貫性を検証するためのテストが含まれます。DBTには2種類のテストがあります:
Schema Tests: スキーマファイル(schema.yml)に定義されたテストで、例えばユニーク制約やNULLチェックなどがあります。
Data Tests: testsディレクトリに定義されたカスタムテストSQLファイルで、より複雑なロジックを検証します。
特定のモデルに関連するテストを実行するには、次のように指定します:
dbt test --models example.dim_products
Dagsterを使ったdbtの実行
まず作成したDagsterプロジェクトディレクトリdbt_dagsterに移動します。
cd dbt_dagster
Dagsterがdbtプロジェクトを開始時にすべての設定を解析し、ロードするために、DAGSTER_DBT_PARSE_PROJECT_ON_LOAD環境変数を設定します。
export DAGSTER_DBT_PARSE_PROJECT_ON_LOAD=1
環境変数を設定した後、以下のコマンドを実行してDagsterを開発モードで起動します。このモードでは、Dagsterのウェブインターフェースが有効になり、プロジェクトの監視や管理が行えます。
dagster dev
Dagster UIに入った後、画面右上のMaterialize all ボタンをクリックして、dbtプロジェクトの全てのモデルを一度にビルドしマテリアライズします。この操作により、dbtが背後で dbt run コマンドを実行し、すべてのモデルがデータウェアハウスに適用されます。
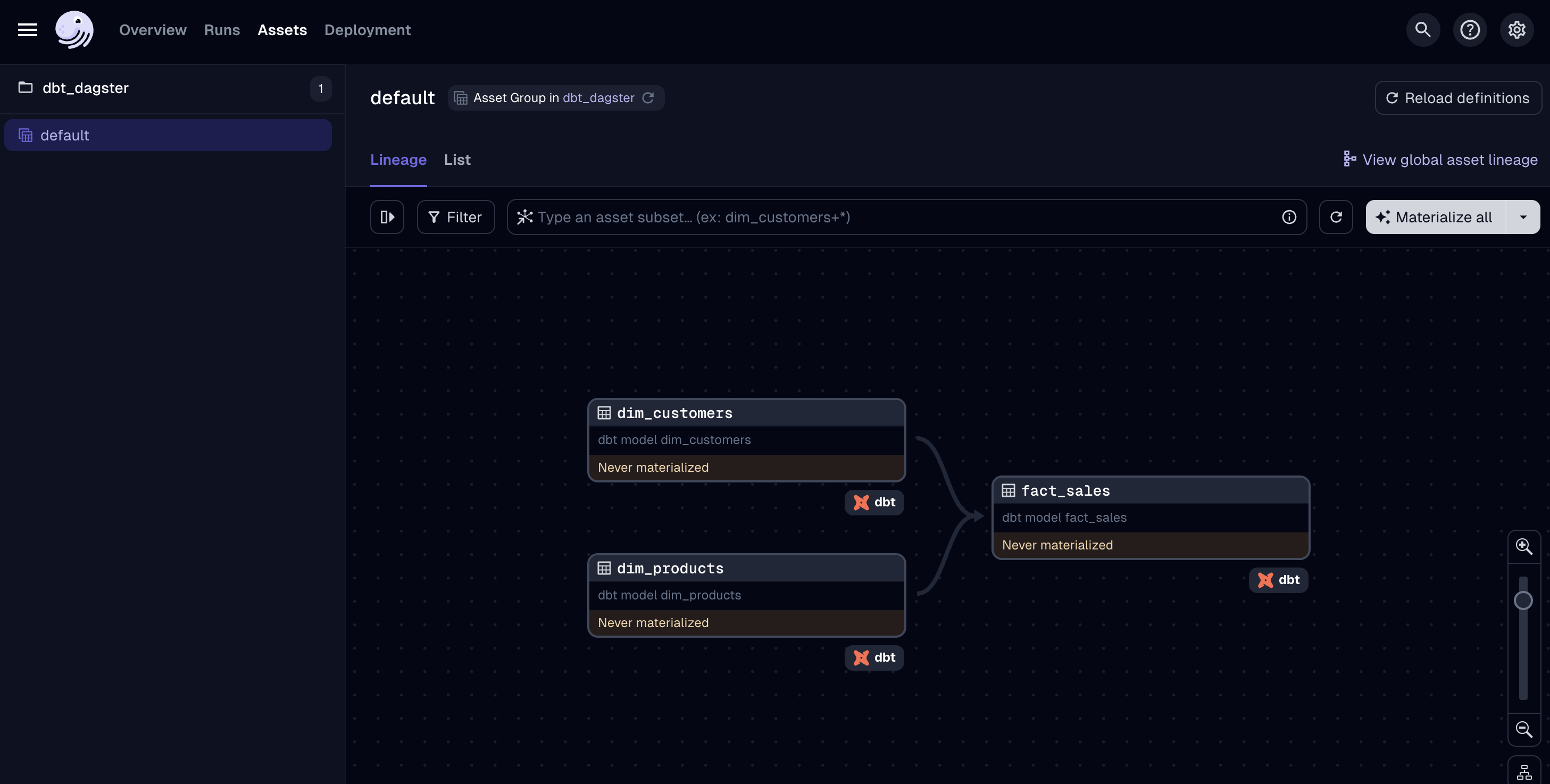
Materialize all をクリック後、プロセスの実行状況をUIで確認できます。この段階では、各モデルのビルド状況やエラー情報がリアルタイムで提供され、プロジェクトの進捗を追跡できます。
また、以下のようにMaterialize selectedを使用することでモデルごとの実行も可能です。

BigQueryでの実行確認
dbtモデルがマテリアライズされた後、Google Cloud Consoleを使用してBigQueryにログインし、実行されたモデルが正しくデータを反映しているかを確認します。

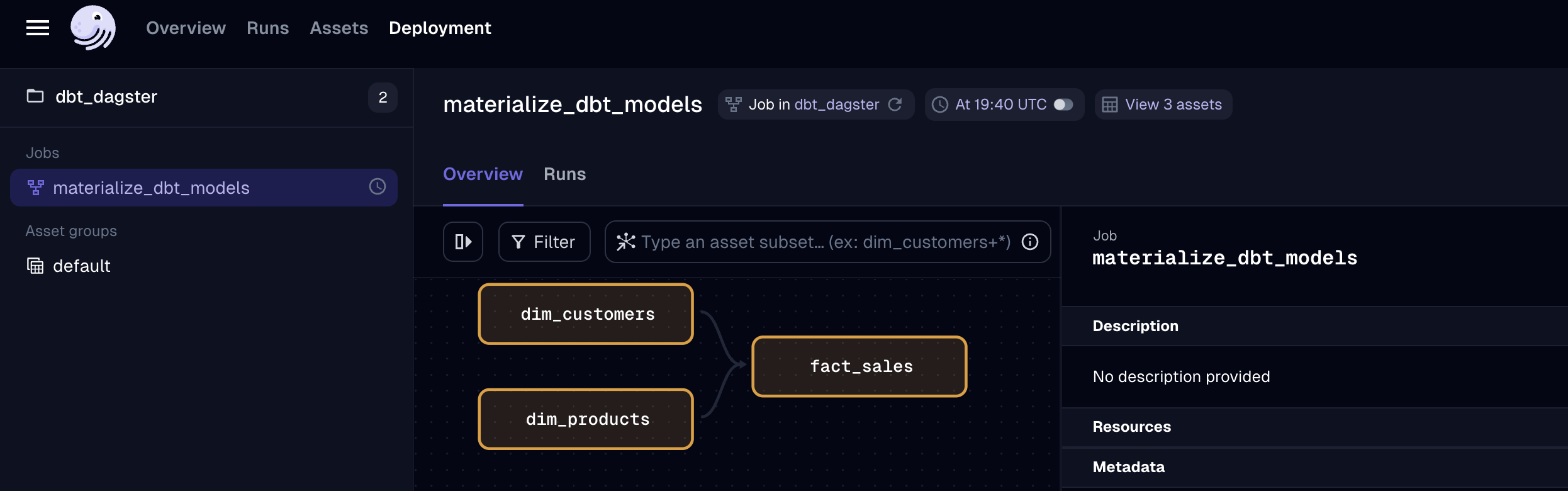
定期実行の設定
Dagsterでは定期実行のスケジュールを設定することできます。スケジュール設定用のPythonスクリプトを作成し、それをDagsterのプロジェクトディレクトリ内に保存します。通常、このスクリプトは schedules ディレクトリ内に配置されることが推奨されます。以下はスケジュールを設定するためのコード例です。
from dagster_dbt import build_schedule_from_dbt_selection
from .assets import dbt_core_dbt_assets
schedules = [
build_schedule_from_dbt_selection(
[dbt_core_dbt_assets],
job_name="materialize_dbt_models",
cron_schedule="40 19 * * *",
dbt_select="fqn:*",
),
]
このスクリプトは、毎日UTCで毎日19時40分に dbt_pipeline を実行するようにスケジュールを設定します。Dagsterはこのスケジュールに従って自動的にdbtモデルを実行し、データの更新を行います。

最後に
今回は、Dagsterとdbtを使用したデータオーケストレーションの基本を説明しました。これらのツールの組み合わせにより、データモデリングと変換プロセスの管理が大幅に簡素化され、データチームはより一層効果的に作業を進めることができます。特に、BigQueryでのモデルの正確なマテリアライズを通じて、データの整合性とアクセスの容易さが確保されます。Dagsterでの実行監視はプロジェクトの進捗を可視化し、実行の正確性を向上させるのに役立ちます。データパイプラインのオーケストレーションを適切に管理することで、データエンジニアはデータ駆動の洞察をより迅速かつ確実に提供できるようになります。