Deep image priorを音声でやってみる
Deep image priorという論文が昨年11月に発表され、注目を浴びているようです。
この論文はCNNの構造自体が画像らしさを表現するのに適しているため,
適当なランダムノイズだけの画像1枚からノイズが付加された画像1枚を出力させるようにCNNを学習すると、
最終的にノイズが取れた綺麗な画像が出力されるようになるというものでした。
特に面白い点が実験的結果なれど、CNNが画像らしさを表現する関数だといえたことだと思います。
所変わって音響信号処理でもDeep Learningとの融合は非常によく図られており、音声強調、つまるところNoisyな音声のDenoisingに関する応用もよく研究されています。(音響的に外乱はノイズだけじゃないですが)
今回、Deep image priorのようなDenoisingが音声の場合でもできれば、音声強調DNNに対して何か新しい知見が得られるのではないかと思ってとりあえずでやってみることにしました。
遊んでねーで自分の仕事しろよ
setup
やることは大したことがありません。
論文中のモデルを画像を音声に置き換えただけです
-モデル
論文中と同じUNetのようなモデルを用いました。
2次元畳み込みを1次元畳み込みにしたものを用いました。
フィルタタップ長は128と長めに取りました。
-音源
音源信号はNIIで有償配布されている音素バランス文の一つを用いました。
有償配布データなので、こちらで音として流すことはできません…。あしからず。
サンプリングレートは16kHzです。
-付与ノイズ
ノイズはピンクノイズを付与しました。
SN比は適当ですが多分6dBくらいのような気がします。
-入力ノイズ
ガウス乱数です。
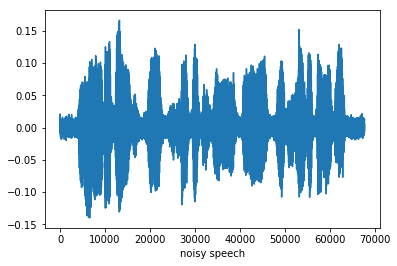
図1.ノイズが付与された音声信号
わかりづらいですが帯状に現れているのがノイズ、包絡が増減しているのが音声です。
約5秒程度の長さの音声を丸ごと出力ベクトルとして学習させます。
入力ノイズも出力と同じ長さになるようにします。
結果
学習結果の出力信号です
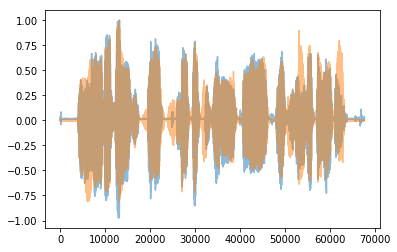
図3.紺が出力信号、オレンジがクリーン信号 オレンジを生成することが今回の目標
(学習し直してしまったので上のものに比べてややノイズが残っています)
なんだかところどころ丸ごと削っていますね…。
聞いた感じはもうものすごい低域しか聞こえず、かつ歪んでいて、クリーン信号を事前に聞かないと何を言ってるのかすらわかりませんでした。
スペクトログラムで確認して見ます。
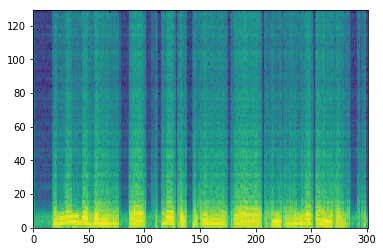
図4.出力信号のスペクトログラム
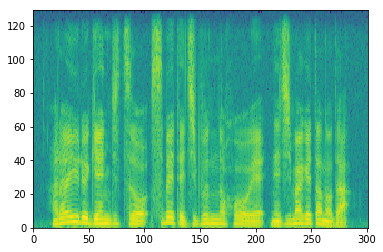
図5.クリーン信号のスペクトログラム
横軸が時間に相当するフレームインデックス、縦が周波数ビン、濃淡が強さを表していて、黄色いほど、その時間、その周波数の音が強いことになります。
出力信号は低域ばかり再現していて、高域は全く再現できていませんね。
このあと信号を帯域分割して高域のみ再現させようとしてもノイズが付加されたままの信号や、全く関係ない信号が出力されるのみでした。
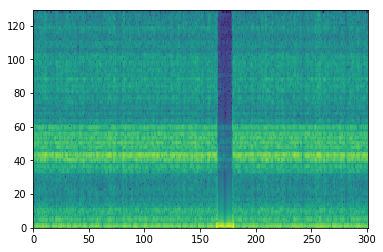
図6.高域信号のみで学習した時の出力信号のスペクトログラム
考察
察するにUNetのダウンサンプリングが悪影響しているように思います。
サンプリング定理からいって、ダウンサンプリングしてしまうと元の信号の高域成分はどんどん消えていってしまいます。
CNNの中身でサンプリング定理が通用するかは謎ですが、ダウンサンプリングしすぎることに影響があるような気がします。
ただUNetはスキップコネクションをして、ダウンサンプリング前の特徴も残す構造をしているので実際どうなんでしょう…。
まとめ
Deep image priorの要領で音声強調を試しました。
結果としてノイズは取れたようにみえますが低域ばかり強調され、音も歪むなど音声強調できたとは言い難い結果でした。
信号を帯域分割して高域のみの音声強調を試した所、全くノイズを取ることができませんでいした。
この結果から構造自体が高域を再現できない可能性が考えられます。
所感
もしかしたらDeep image priorはDenoisingを目的にするより、考えたネットワーク構造が目的となる信号を適切に出力できるかのテストができるかもしれません。
まともに実験してないのでなんともいえませんが。
というか図の表記もめっちゃいい加減・・・・・・・・
詳細なパラメータを記述するのがめんどいからコードをgithubにあげたいので整理しつつ、ついでにダウンサンプリングを減らすなど試して見ます。
今日はここまで。明日から日本音響学会ですね。3/12現在。