前書き
巷には様々なデータセットが公開されておりますが、ちょっとした手法や視覚化の実験などでデータセットが必要になった時に、自分が欲しいデータセットが見つからなくて困る時があります。そんな時のために自分で好きなようにデータセットを生成する方法を説明します。
scikit-learn make_classification
make_classificationを使うと特徴数、サンプル数、ラベル数などを指定して分類データセットを生成できます。scikit-learn make_classification(公式サイト)
- n_samples -> サンプル数
- n_features -> 特徴数
- n_classes -> クラス(ラベル)数
- n_informative -> 有益な特徴の数(ラベルの数値決定に使用される特徴の数)
from sklearn.datasets import make_classification
data = make_classification(n_samples = 100,n_features = 5,n_informative=3,n_classes=3)
**data[0]**でデータにアクセスできます。
data[0][0:5]
array([[ 1.25171094, -0.30019005, 2.00806351, -1.47329273, -1.67471559],
[ 0.31008017, 0.63222138, 1.23102902, 0.00867144, -1.32069461],
[ 1.90703337, -3.09054185, -0.09613603, -1.76358775, 1.48529172],
[-0.74437558, -0.36960086, -1.28849546, -1.52271631, 0.95437931],
[ 0.07446709, -0.38235836, -0.43047044, 0.48153833, 0.63651724]])
**data[1]**でラベルにアクセスできます。
data[1][0:5]
array([0, 0, 0, 2, 1])
pandasのデータフレームに変換します。
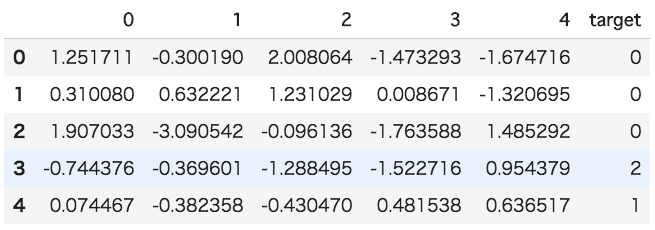
df = pd.DataFrame(data[0])
df['target'] = data[1]
df.head()
scikit-learn make_regression
make_regressionを使うと特徴数、サンプル数などを指定して回帰データセットを生成できます。scikit-learn make_regression(公式サイト)
- n_samples -> サンプル数
- n_features -> 特徴数
- n_informative -> 有益な特徴の数(ラベルの数値決定に使用される特徴の数)
**注意:**n_classesをn_informativeより小さく設定することはできません
from sklearn.datasets import make_regression
data = make_regression(n_samples = 100,n_features = 5,n_informative=3)
pandasデータフレーム化します。
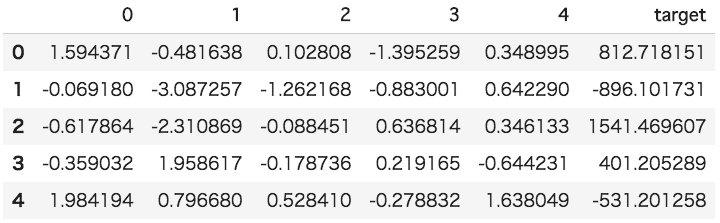
df = pd.DataFrame(data[0])
df['target'] = data[1]
df.head()
numpyでデータセットを生成する
numpyでデータセットを生成すると、ターゲット変数の値と特徴の値に関連を持たせることができず、データセット全体の値がランダムになります。numpy randn+randint
import pandas as pd
import numpy as np
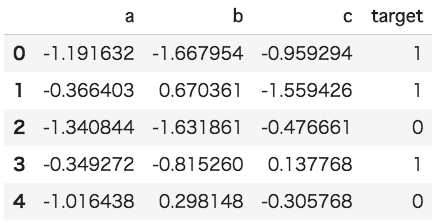
df = pd.DataFrame({'a': np.random.randn(100),
'b': np.random.randn(100),
'c': np.random.randn(100),
'target':np.random.randint(2, size=100)})
df.head()
- np.random.randn(100) -> ランダムな数値を100個生成します
- np.random.randint(2, size=100) -> 0から1までの数値をランダムに100個生成します
すべてをnp.random.randnで生成すれば回帰問題のためのデータセットを生成できます。
df = pd.DataFrame({'a': np.random.randn(100),
'b': np.random.randn(100),
'c': np.random.randn(100),
'target':np.random.randn(100)})
df.head()