はじめに
社内の勉強会で使用するため、久しぶりに Open Images Dataset を覗きました
昔見たときは V3 とか V4 だったのが、もう V6 になっている
光陰矢の如し、、、
感傷に浸りつつ、データを取ってこようとダウンロードのページに行くと
Download and Visualize using FiftyOne
という項目が
昔はこんなのなかったぞ、、、
しかし、読んでみると、どうも FiftyOne なるものを使った方が早く楽にデータが使えそうです
というわけで、FiftyOne を使ってみました
データセットが簡単にダウンロードできるだけでなく、
ブラウザ上ですぐに確認できたり、他の形式への変換までできる優れものです
実行例は GitHub に載せています
Google Colab 用のノートブックはこちら
下のバッジから直接 Google Colab で開きます
![]()
実行環境
- ローカル
- Windows 10 Pro
- Python 3.9.6
- Google Colab
FiftyOne のインストール
Python パッケージなので pip でインストールできます
pip install fiftyone
Google Colab などのノートブック上では先頭に ! を付けてください
!pip install fiftyone
データセットの取得
FiftyOne のデータセットZOOから、以下のように書くだけで簡単に画像、アノテーションデータをダウンロードできます
import fiftyone.zoo as foz
dataset = foz.load_zoo_dataset(
"open-images-v6",
split="validation",
label_types=["detections"],
classes=["Cat", "Dog"],
max_samples=100,
only_matching=True,
)
# 名前を付けて
dataset.name = "open-images-v6-cat-dog"
# 永続化する
dataset.persistent = True
指定している引数は以下のとおり
-
データセットの種類
coco-2017 や open-images-v6 など
種類の一覧は
foz.list_zoo_datasets()で取得可能全量はこちら
https://voxel51.com/docs/fiftyone/user_guide/dataset_zoo/datasets.html
-
split: データセットの中の分類
train や validation 、 test など
指定しなければデータセットに含まれるすべての split が取得されます
train は特に大きいためリソースを消費し、ダウンロードにも時間がかかるため、
少し試す場合は validation を指定すると良いです -
Open Image Dataset の場合
-
label_types: アノテーションデータの種類
detections や segmentations など、データの種類を指定します
-
classes: クラス名
取得する画像に含まれるクラス
Cat や Dog など
-
max_samples: サンプル数上限
取得する画像の最大枚数
split を指定していない場合、 split 毎の上限になります
(train、valodation、test があれば 3 倍取得されるので注意) -
only_matching: 一致したラベルだけを取得する(指定しなければ False)
True にしないと、同じ画像内に含まれる別クラスの物体もラベルが付きます
-
実装時の注意
Windows だからか、上記のように直接動かすと以下のようなエラーが出ます
The "freeze_support()" line can be omitted if the program The "freeze_support()" line can be omitted if the program.
以下のように関数を経由すると解消します
import fiftyone.zoo as foz
def main():
dataset = foz.load_zoo_dataset(
"open-images-v6",
split="validation",
label_types=["detections"],
classes=["Cat", "Dog"],
max_samples=100,
only_matching=True,
)
# 名前を付けて
dataset.name = "open-images-v6-cat-dog"
# 永続化する
dataset.persistent = True
if __name__ == "__main__":
main()
ブラウザでのデータ表示
ローカルでWEBサーバーを起動し、ブラウザからデータセットの中を見ることができます
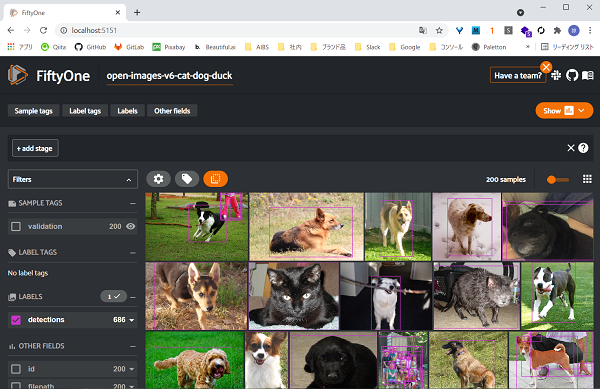
これが非常に見やすく、どういうデータが入っているのか、アノテーションはどう付いているのか、簡単に確認できます
スクリプトから起動する場合、 session.wait() で起動したままにする必要があります
import fiftyone as fo
session = fo.launch_app(dataset, port=80)
session.wait()
port でポート番号が指定可能です(指定しなければ 5151)
Jupyter notebook の場合、起動すると出力結果に表示され、そこから直接操作できます
session = fo.launch_app(dataset)
データのエクスポート
各種パッケージやモデルの学習に使えるよう、様々な形式でエクスポートできます
これも非常に便利な機能です
今までは各データセット毎に変換処理を用意したりしていたのが、何も考えずにすぐに使えてしまいます
画像分類
dataset_type に ImageClassificationDirectoryTree を指定すると、画像がクラス毎にディレクトリーに仕分けて配置されます
dataset.export(
export_dir=f"~/classification",
dataset_type=fo.types.ImageClassificationDirectoryTree,
)
いわゆる画像分類でよく使われる形式ですね
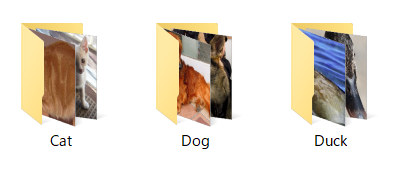
これですぐに Inception や EfficientNet の学習が実行できます
入力画像から当該クラスの部分を切り取って画像分類用の入力とするため、
入力となるデータセットのラベルタイプは classifications ではなく、
detections である必要があります
VOC
VOC 形式の場合は VOCDetectionDataset です
COCO なども同じように dataset_type を変えるだけで出力可能です
dataset.export(
export_dir=f"~/voc",
dataset_type=fo.types.VOCDetectionDataset,
)
YOLO V5
更に、 YOLO V4 や YOLO V5 の形式にもエクスポート可能です
classes を指定しないと全クラスが使用されてしまうため、必ずクラスを指定しましょう
学習データ、評価データ、テストデータに分割してそれぞれ出力し、
学習用のデータ定義を配置すれば YOLO V5 もすぐに学習できます
classes = ["Cat", "Dog", "Duck"]
train_dataset = dataset[:700]
val_dataset = dataset[700:800]
test_dataset = dataset[800:]
# YOLO V5 形式でエクスポート
train_dataset.export(
export_dir=f"/content/data/train",
dataset_type=fo.types.YOLOv5Dataset,
split="train",
classes=classes,
)
val_dataset.export(
export_dir=f"/content/data/val",
dataset_type=fo.types.YOLOv5Dataset,
split="val",
classes=classes,
)
test_dataset.export(
export_dir=f"/content/data/test",
dataset_type=fo.types.YOLOv5Dataset,
split="test",
classes=classes,
)
学習用データ定義
train: /content/data/train/images/train
val: /content/data/val/images/val
test: /content/data/test/images/test
nc: 3
names:
- Cat
- Dog
- Duck
おわりに
月日は百代の過客にして行きかふ年もまた旅人なり
FiftyOne は COCO データセットを扱う推奨ツールになっており、
先述の通り、 Open Images Dataset でも使用を勧められています
AI 関連をやっているといつも思うのですが、
ほんの少し目を離した隙に新しいライブラリ、ツール、モデル、サービスが次々出てきて、
ちょっと前に実装したものがもう古くなってしまいます
これからも業務の合間に新技術を見るようにしなければ