はじめに
2022 年 7 月 に公開された YOLOv7
YOLO シリーズもついに v7 まで来たか
今回は YOLOv7 を OpenCV で動かすまでに苦労した話です
素直に PyTorch で動かせばいいのですが、
過去の YOLOv3 や YOLOv4 を OpenCV で動かしたコードを、
YOLOv7 にも流用したかったのです
実行環境
- macOS Monterey 12.5.1
- Python 3.10.5
- opencv-python 4.6.0.66
PyTorch で動かす
まずは公式で出ている、 PyTorch で動かす方法です
と言っても、ほぼ README に従うだけです
まずはリポジトリーをクローンしてきてディレクトリー内に移動します
git clone https://github.com/WongKinYiu/yolov7.git \
&& cd yolov7
requirements.txt があるので、これを使って依存パッケージをインストールします
pip install -r requirements.txt
公式の Testing にあるリンクから yolov7.pt をダウンロードしてきます
検出を実行します
$ python detect.py --weights yolov7.pt --conf 0.25 --img-size 640 --source inference/images/horses.jpg
...
5 horses, Done. (1179.9ms) Inference, (6.5ms) NMS
The image with the result is saved in: runs/detect/exp13/horses.jpg
Done. (1.231s)
標準出力に表示される runs/detect/exp<連番>/<クラス名>.jpg に、
検出された物体に枠が付与された画像が出力されています

ここまでは特に何も考える必要がありませんでした
Darknet で動かす
機械学習モデルを OpenCV で動かすためには、 dnn.readNet で読み込める形式であることが前提です
読み込めるのは以下の形式です
- *.caffemodel (Caffe, http://caffe.berkeleyvision.org/)
- *.pb (TensorFlow, https://www.tensorflow.org/)
- *.t7 | *.net (Torch, http://torch.ch/)
- *.weights (Darknet, https://pjreddie.com/darknet/)
- *.bin (DLDT, https://software.intel.com/openvino-toolkit)
- *.onnx (ONNX, https://onnx.ai/)
以前、 YOLOv3 や YOLOv4 を動かすときには Darknet の .weights を使っていました
Darknet の YOLO リポジトリーを見てみると、、、
YOLOv7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors
YOLOv7 is more accurate and faster than YOLOv5 by 120% FPS, than YOLOX by 180% FPS, than Dual-Swin-T by 1200% FPS, than ConvNext by 550% FPS, than SWIN-L by 500% FPS, than PPYOLOE-X by 150% FPS.
YOLOv7 を紹介していました
YOLOv7 用の .cfg ファイルも置いてあります
間違いなく動かせますね
となると、 Darknet 用の yolov7.weights がどこかにあるはずです
ちょっと探すのに手間取りましたが、 YOLOv7 リポジトリーの Releases にありました
ここの yolov7.weights をダウンロードして、 Darknet に読ませます
まず、 Darknet のリポジトリーをクローンしてディレクトリーに移動します
git clone https://github.com/AlexeyAB/darknet.git \
&& cd darknet
Python から動かす場合には libdarknet.so が必要になるので、 Makefile を編集します
先頭の方にある LIBSO を 0 から 1 に変更してください
GPU=0
CUDNN=0
CUDNN_HALF=0
OPENCV=0
AVX=0
OPENMP=0
- LIBSO=0
+ LIBSO=1
ZED_CAMERA=0
ZED_CAMERA_v2_8=0
...
そして make を実行すると、以下のファイルがビルドされます
- darknet
- libdarknet.dylib
- libdarknet.so
エラーが出る場合はビルドに必要なものが揃ってないので、適宜入れてください(本筋ではないのでぶん投げる)
YOLOv7 リポジトリーからダウンロードした yolov7.weights を darknet ディレクトリーの直下に置きます
以下のコマンドを実行すると、 inference というウィンドウに検出結果が表示されます
$ python darknet_images.py --input data/horses.jpg --weights yolov7.weights --config_file ./cfg/yolov7.cfg
...
Objects:
horse: 88.02%
horse: 88.52%
horse: 92.87%
horse: 95.65%
horse: 97.09%
FPS: 0
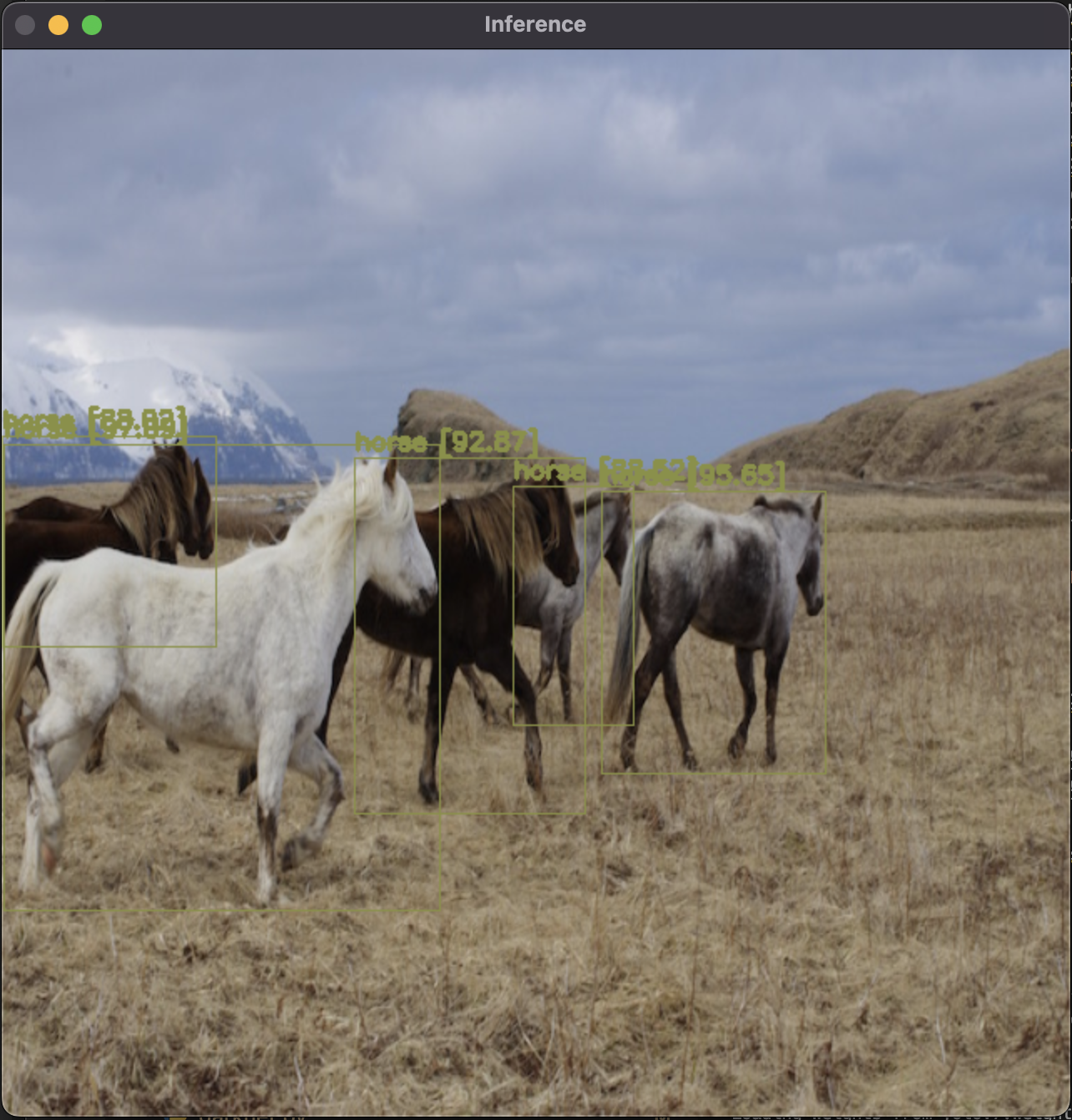
正方形に変形してますが、 PyTorch のときと同じような結果が出ましたね
検出結果を十分に堪能したら Q キーを押してウィンドウを閉じてください
OpenCV で動かす
ようやく本題です
OpenCV で動かす場合、以下のようにモデルを読み込みます
net = cv2.dnn.readNetFromDarknet(cfg_path, weights_path)
変数にはそれぞれ以下のように値を設定します
- cfg_path: yolov7.cfg のパス
- weights_path: yolov7.weights のパス
推論実行は以下のようにします
# 0 〜 255 -> 0 〜 1 に変換
# yolov7.cfg に書いてあるサイズにリサイズ
# BGR -> RGB 変換
blob = cv2.dnn.blobFromImage(
img, 1 / 255, (640, 640), 0, True, crop=False
)
net.setInput(blob)
# 出力層を指定して推論を実行
layers_names = net.getLayerNames()
outputs_names = [layers_names[i - 1] for i in net.getUnconnectedOutLayers()]
outs = net.forward(outputs_names)
outs には3つの出力層の結果が入っており、それぞれ以下のような形をしています
(19200, 85)
(4800, 85)
(1200, 85)
19200 や 4800 、 1200 は各出力層の検出したバウンディングボックスの数です
85 は X座標、Y座標、幅、高さ、検出スコアの5種類の数値 + 80クラスそれぞれに対する分類スコアになっています
これを処理していけば OpenCV でも YOLOv7 の検出結果が取れるはずです
(ここの部分の実装は他所でよく書かれているので割愛します)
Python で実装して実行してみると、、、

全く検出されていません、、、
weights も cfg も Darknet と同じものを使っているのに、、、
Python 実装は YOLOv3 や YOLOv4 で動作実績があるので、間違っていないはず、、、
デバッグしていくと、検出スコアが閾値以上の検出結果について、
「80クラスそれぞれに対する分類スコア」の部分が以下のようになっていることが判明しました
[0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.
0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.
0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.
0. 0. 0. 0. 0. 0. 0. 0.]
[0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.
0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.
0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.
0. 0. 0. 0. 0. 0. 0. 0.]
全部 0 でした
しかも全ての検出結果で
おそらく OpenCV の未実装かバグか何かで、 まだ YOLOv7 が正常に処理できていないようです
色々調べた結果、怪しそうなのは yolov7.cfg の以下の部分
...
[convolutional]
size=1
stride=1
pad=1
filters=255
#activation=linear # ここが怪しい
activation=logistic # ここが怪しい
[yolo]
mask = 6,7,8
anchors = 12,16, 19,36, 40,28, 36,75, 76,55, 72,146, 142,110, 192,243, 459,401
classes=80
num=9
jitter=.1
scale_x_y = 2.0
objectness_smooth=1
ignore_thresh = .7
truth_thresh = 1
#random=1
resize=1.5
iou_thresh=0.2
iou_normalizer=0.05
cls_normalizer=0.5
obj_normalizer=1.0
iou_loss=ciou
nms_kind=diounms
beta_nms=0.6
new_coords=1 # ここが怪しい
max_delta=2
わざわざ activation を linear から logistic に変えていたり、
new_coords という耳慣れない設定があります
ここを変えてみましょう
※出力層は3つあるので、同じような箇所が3回繰り返されています
...
[convolutional]
size=1
stride=1
pad=1
filters=255
- #activation=linear
- activation=logistic
+ activation=linear
+ #activation=logistic
[yolo]
mask = 6,7,8
anchors = 12,16, 19,36, 40,28, 36,75, 76,55, 72,146, 142,110, 192,243, 459,401
classes=80
num=9
jitter=.1
scale_x_y = 2.0
objectness_smooth=1
ignore_thresh = .7
truth_thresh = 1
#random=1
resize=1.5
iou_thresh=0.2
iou_normalizer=0.05
cls_normalizer=0.5
obj_normalizer=1.0
iou_loss=ciou
nms_kind=diounms
beta_nms=0.6
- new_coords=1
max_delta=2
この状態で動かすと、、、

一部の検出結果は正しそうですが、
どうやら出力層毎の座標計算が狂っているようです
ただし、スコアはちゃんと入っています
[0. 0. 0. 0. 0. 0. 0.
0. 0. 0. 0. 0. 0. 0.
0. 0. 0. 0.7316571 0. 0. 0.
0. 0. 0. 0. 0. 0. 0.
0. 0. 0. 0. 0. 0. 0.
0. 0. 0. 0. 0. 0. 0.
0. 0. 0. 0. 0. 0. 0.
0. 0. 0. 0. 0. 0. 0.
0. 0. 0. 0. 0. 0. 0.
0. 0. 0. 0. 0. 0. 0.
0. 0. 0. 0. 0. 0. 0.
0. 0. 0. ]
[0. 0. 0. 0. 0. 0.
0. 0. 0. 0. 0. 0.
0. 0. 0. 0. 0. 0.93849015
0. 0. 0. 0. 0. 0.
0. 0. 0. 0. 0. 0.
0. 0. 0. 0. 0. 0.
0. 0. 0. 0. 0. 0.
0. 0. 0. 0. 0. 0.
0. 0. 0. 0. 0. 0.
0. 0. 0. 0. 0. 0.
0. 0. 0. 0. 0. 0.
0. 0. 0. 0. 0. 0.
0. 0. 0. 0. 0. 0.
0. 0. ]
各検出結果はそれぞれアンカーボックスに対応しているため、順序は変わらないはずです
とうことは、、、
new_coords 指定ありと new_coords 指定なしで2回推論を実行し、
座標情報と検出スコアは new_coords 指定ありのもの、
分類スコアは new_coords 指定なしのものを使えば行けそうです

結局原因は分かずじまいですが、とりあえずはこれで検出できました
まとめ
OpenCV でこんなに無理矢理動かすのであれば、
PyTorch で動かした方がいいです