はじめに
Elixir で簡単に AI モデルを扱える Bumblebee で Llama2 や Mistral が動かせるようになっていたので、 Google Colaboratory から実行してみました
基本的には Bumblebee 公式のノートブックを実行していますが、 Google Colaboratory 用に少し改造しています
実装したノートブックはこちら
GPU メモリ容量の関係で Llama2 と Mistral をそれぞれ別のノートブックで実行しています
事前準備
ngrok
Google Colaboratory 上で Livebook を動かすのに ngrok を使うため、 ngrok にサインアップして認証トークンを発行しておきます
Hugging Face
Hugging Face で公開されているモデルを使うため、 Hugging Face にサインアップして認証トークンを発行しておきます
また、使用するモデルは事前に承認を得ておく必要があります
Llama2 は以下のページにアクセスし、下部にある入力フォームから名前などを入力して「Submit」をクリックします

即時承認されないため、あらかじめ前日からリクエストするなどしておきましょう
承認されたら以下の文言が表示されます

Mistral は以下のページにアクセスし、「Agree and access repository」をクリックするとすぐに使えるようになります

Google Colaboratry
少し良い GPU (L4 GPU) を使わないといけないので、 Google Colaboratory の Pro プランが必要です
月額千円強なので、これから GPU をちょこちょこ使うのであれば契約しましょう
Livebook の起動
以下の記事を参考に Google Colaboratory 上で Livebook を起動しましょう
ただし、ランタイムには L4 GPU を指定してください
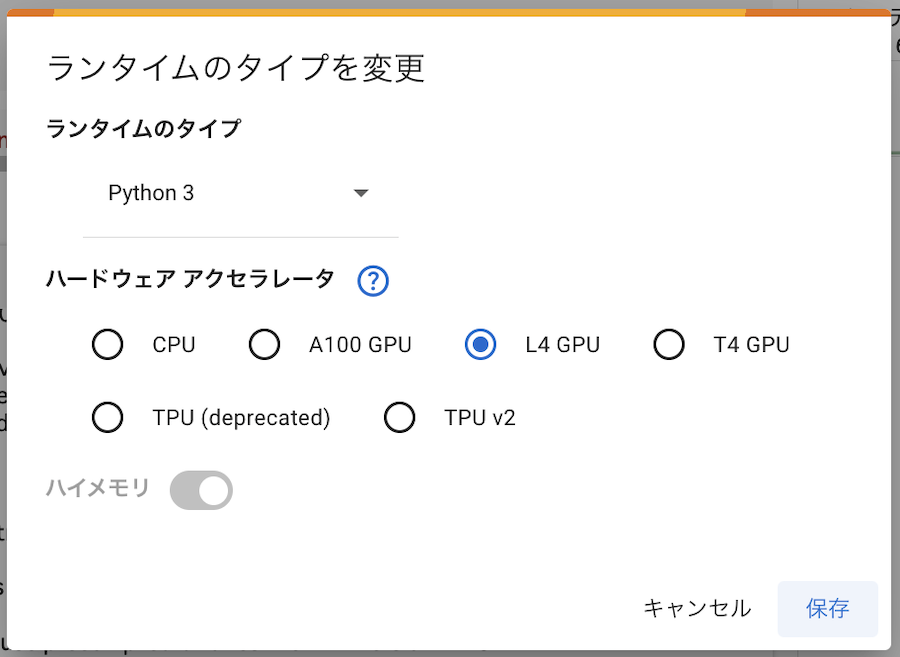
T4 GPU ではメモリ不足で実行できません
実装したノートブックはこちら
ノートブックの準備
新しいノートブックを開きます
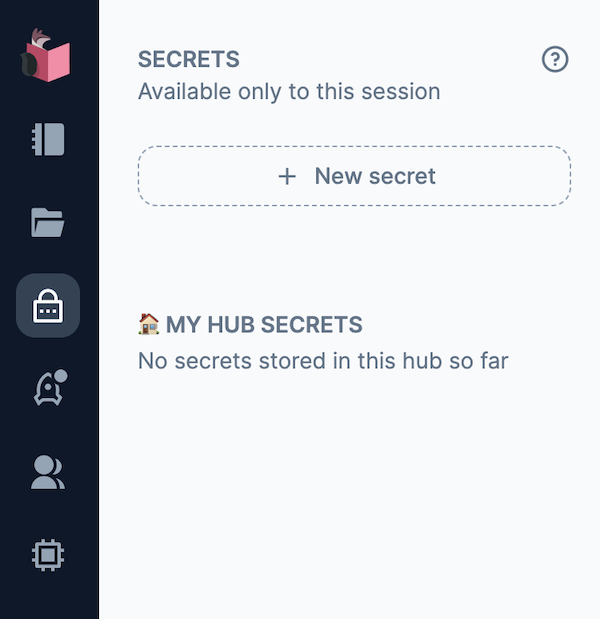
左メニューから南京錠のアイコンをクリックして「SECRETS」を表示し、「+ New secret」をクリックします
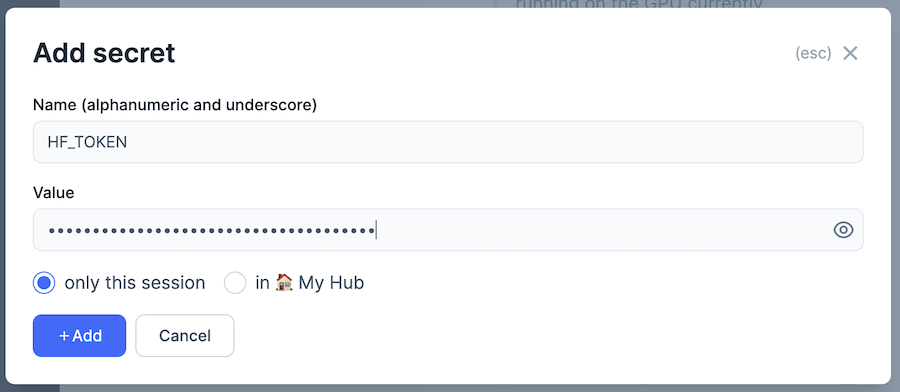
「Name」を「HF_TOKEN」、 Value を Hugging Face のトークンにして「+ Add」をクリックします
依存モジュールのインストール
以下のコードを実行します
Mix.install(
[
{:bumblebee, "~> 0.5"},
{:nx, "~> 0.7"},
{:exla, "~> 0.7"},
{:kino, "~> 0.12"}
],
system_env: [
{"XLA_TARGET", "cuda120"},
{"EXLA_TARGET", "cuda"}
]
)
Nx.global_default_backend({EXLA.Backend, client: :host})
Bumblebee、 Nx、 EXLA、 Kino の 2024年5月30日時点の最新版をインストールしています
EXLA で GPU を使うため、環境変数の設定もしています
- XLA_TARGET: cuda120
- EXLA_TARGET: cuda
2024年5月30日時点では Google Colaboratory で CUDA 12.2 が使えるため、 cuda120 を指定しています
各バージョン指定はそのときの最新を使うなど、適宜変更してください
Llama2 の実行
以下のコードを実行します
Bumblebee で Hugging Face から Llama2 のモデルをダウンロードし、読み込んでいます
hf_token = System.fetch_env!("LB_HF_TOKEN")
repo = {:hf, "meta-llama/Llama-2-7b-chat-hf", auth_token: hf_token}
{:ok, model_info} = Bumblebee.load_model(repo, type: :bf16, backend: EXLA.Backend)
{:ok, tokenizer} = Bumblebee.load_tokenizer(repo)
{:ok, generation_config} = Bumblebee.load_generation_config(repo)
:ok
続けて以下のコードを実行します
Bumblebee で定義したテキスト生成のプロセスを子プロセスとして起動します
後で子プロセスを終了させるため、 pid を保持しておきます
この部分は元のノートブックから変えています
generation_config =
Bumblebee.configure(generation_config,
max_new_tokens: 256,
strategy: %{type: :multinomial_sampling, top_p: 0.6}
)
serving =
Bumblebee.Text.generation(model_info, tokenizer, generation_config,
compile: [batch_size: 1, sequence_length: 1028],
stream: true,
defn_options: [compiler: EXLA]
)
# Should be supervised
{:ok, pid} = Kino.start_child({Nx.Serving, name: Llama, serving: serving})
テキスト入力を用意します
user_input = Kino.Input.textarea("User prompt", default: "What is love?")

デフォルトで「What is love?」というテキストが入っていますが、自分で色々変えてみてください
続けて Llama2 にプロンプトを渡し、テキスト生成を実行します
プロンプト内の指示([INST])は以下のような内容です
あなたは、親切で、礼儀正しく、正直なアシスタントです。常にできる限り役立つ回答をし、安全性を確保してください。あなたの回答には、有害、非倫理的、人種差別的、性差別的、攻撃的、危険、または違法な内容を含めてはいけません。社会的に偏りがなく、前向きな内容にしてください。
質問が意味不明であったり、事実として一貫性がない場合は、誤った回答をするのではなく、その理由を説明してください。質問の答えが分からない場合は、誤った情報を共有しないでください。
user = Kino.Input.read(user_input)
prompt = """
[INST] <<SYS>>
You are a helpful, respectful and honest assistant. Always answer as helpfully as possible, while being safe. Your answers should not include any harmful, unethical, racist, sexist, toxic, dangerous, or illegal content. Please ensure that your responses are socially unbiased and positive in nature.
If a question does not make any sense, or is not factually coherent, explain why instead of answering something not correct. If you don't know the answer to a question, please don't share false information.
<</SYS>>
#{user} [/INST] \
"""
Nx.Serving.batched_run(Llama, prompt) |> Enum.each(&IO.write/1)
実行すると、以下のようにリアルタイムでテキスト生成が実行されます

ちなみに Jupyter 側のリソースを確認すると、この時点で GPU メモリはほとんどパンパンになっているのが分かります

このまま Mistral をロードするとメモリ不足になるため、一旦ここでノートブックを終了し、改めて新しいノートブックを開きます
Mistral
Mistral も同じようにして実行できます
HF_TOKEN をこちらのノートブックでも SECRETS に指定しておきます
必要なモジュールは同じです
Mix.install(
[
{:bumblebee, "~> 0.5"},
{:nx, "~> 0.7"},
{:exla, "~> 0.7"},
{:kino, "~> 0.12"}
],
system_env: [
{"XLA_TARGET", "cuda120"},
{"EXLA_TARGET", "cuda"}
]
)
Nx.global_default_backend({EXLA.Backend, client: :host})
Hugging Face から Mistral のモデルをロードします
公式のノートブックでは認証トークンを渡していませんが、必要なので , auth_token: hf_token を追加しています
hf_token = System.fetch_env!("LB_HF_TOKEN")
repo = {:hf, "mistralai/Mistral-7B-Instruct-v0.2", auth_token: hf_token}
{:ok, model_info} = Bumblebee.load_model(repo, type: :bf16, backend: EXLA.Backend)
{:ok, tokenizer} = Bumblebee.load_tokenizer(repo)
{:ok, generation_config} = Bumblebee.load_generation_config(repo)
:ok
以下のようにしてテキスト生成を実行します
[INST] の内容を和訳すると以下のようになっています
あなたのお気に入りの調味料は何ですか?
そうですね、新鮮なレモンジュースを少し絞るのが大好きです。料理にちょうどいい風味を加えてくれるんです。
マヨネーズのレシピを教えてもらえますか?
prompt = """
<s>[INST] What is your favourite condiment? [/INST]
Well, I'm quite partial to a good squeeze of fresh lemon juice. It adds just the right amount of zesty flavour to whatever I'm cooking up in the kitchen!</s>
[INST] Do you have mayonnaise recipes? [/INST]\
"""
Nx.Serving.batched_run(Mistral, prompt) |> Enum.each(&IO.write/1)

マヨネーズのレシピを教えてくれました
不完全ですが日本語にも応えてくれます

後片付け
遊び終わったら Jupyter の方のランタイムを接続解除して削除しておきましょう
放っておくと無駄にコンピューティング・ユニットが消費されてしまいます
まとめ
有償版の Google Colaboratory を使うことで Bumblebee から Llama2 と Mistral によるテキスト生成が実行できました
これから更に色々なモデルに対応していくと思うので楽しみですね