はじめに
前回の記事で Google Colaboratory 上で Nx の各種バックエンドを動かしました
では同じようにして Google Colaboratory 上で Bumblebee を動かし、画像生成や画像分類、テキスト補完などを実行してみましょう
実装したノートブックはこちら
それぞれ import すると実行しやすいと思います
画像生成(Stable Diffusion)など単体は実行できましたが、複数のノートブックを実行しているとメモリ不足でエラーが発生しました
メモリ不足を防ぐためには、不要になったノートブックのセッションを閉じてください
-
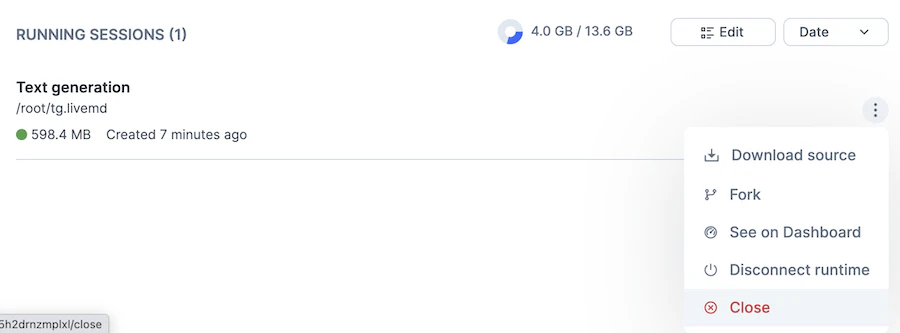
現在開いているノートブックを閉じる場合
基本的に各ノートブックを実行し終わったらセッションを閉じるようにしましょう
- ノートブックの最上部タイトルの右端にあるアイコンからドロップダウンを開き Close を選択する
- 確認モーダルで Close session をクリックする
-
Livebook の Home 画面から閉じる場合
- 一番下に表示されている現在開いているノートブックの一覧を確認する
- 不要になったノートブックの右端アイコンからドロップダウンを開き Close を選択する
- 確認モーダルで Close session をクリックする
それでもメモリエラーが解消しない場合、以下の手順で Livebook を再起動してください
-
Livebook のタブを閉じる
-
Colab の Jupyter に戻る
-
実行中になっている
!livebook server --port 8888 --no-tokenのセルを中断する -
二つ上のセル(以下の内容)から順次再実行する
get_ipython().system_raw('./ngrok http 8888 &') !sleep 5s
共通
セットアップセルは全処理共通で以下のコードを実行します
Mix.install(
[
{:bumblebee, "~> 0.1"},
{:nx, "~> 0.4"},
{:exla, "~> 0.4"},
{:kino, "~> 0.8"}
],
system_env: [
{"XLA_TARGET", "cuda114"}
],
config: [
nx: [
default_backend: EXLA.Backend
]
]
)
2023年2月15日現在、 Nx や EXLA は 0.5 がリリースされていますが、 Bumblebee がまだそのバージョンに対応していないため、 0.4 を指定しています
また、 GPU を使うために XLA_TARGET を指定しています
Google Colaboratory の場合、 XLA_TARGET を cuda118 にすると Bumblebee の推論実行時にエラーが発生したため、 cuda114 にしています
また、 config で Nx が使うバックエンドを EXLA.Backend に指定します
ちなみに Torchx をバックエンドにして Bumblebee を動かすことはできませんでした
画像生成(Stable Diffusion)
まず画像生成を実行してみましょう
セットアップと時間計測以外は以下の記事と同じです
画像生成の設定
repository_id = "CompVis/stable-diffusion-v1-4"
cache_dir = "/tmp/bumblebee_cache"
画像生成モデルのダウンロード
{:ok, tokenizer} =
Bumblebee.load_tokenizer({
:hf,
"openai/clip-vit-large-patch14",
cache_dir: cache_dir
})
{:ok, clip} =
Bumblebee.load_model({
:hf,
repository_id,
subdir: "text_encoder", cache_dir: cache_dir
})
{:ok, unet} =
Bumblebee.load_model(
{
:hf,
repository_id,
subdir: "unet", cache_dir: cache_dir
},
params_filename: "diffusion_pytorch_model.bin"
)
{:ok, vae} =
Bumblebee.load_model(
{
:hf,
repository_id,
subdir: "vae", cache_dir: cache_dir
},
architecture: :decoder,
params_filename: "diffusion_pytorch_model.bin"
)
{:ok, scheduler} =
Bumblebee.load_scheduler({
:hf,
repository_id,
subdir: "scheduler", cache_dir: cache_dir
})
{:ok, featurizer} =
Bumblebee.load_featurizer({
:hf,
repository_id,
subdir: "feature_extractor", cache_dir: cache_dir
})
{:ok, safety_checker} =
Bumblebee.load_model({
:hf,
repository_id,
subdir: "safety_checker", cache_dir: cache_dir
})
serving =
Bumblebee.Diffusion.StableDiffusion.text_to_image(
clip,
unet,
vae,
tokenizer,
scheduler,
num_steps: 20,
num_images_per_prompt: 2,
safety_checker: safety_checker,
safety_checker_featurizer: featurizer,
compile: [batch_size: 1, sequence_length: 60],
defn_options: [compiler: EXLA]
)
画像生成の実行
prompt_input = Kino.Input.text("PROMPT")
テキストエリアに Super Robot と入れてみます
output = Nx.Serving.run(serving, Kino.Input.read(prompt_input))
output.results
|> Enum.map(fn result ->
Kino.Image.new(result.image)
end)
|> Kino.Layout.grid(columns: 2)
実行結果は以下のようになりました

画像生成の時間計測
:timer.tc を使って時間を計測し、10回の平均を求めます
1..10
|> Enum.map(fn _ ->
{time, _} = :timer.tc(Nx.Serving, :run, [serving, Kino.Input.read(prompt_input)])
time
end)
|> then(&(Enum.sum(&1) / 10))
実行時間は 27351272.3 マイクロ秒 = 約 27.4 秒でした
画像分類
画像分類もセットアップと時間計測以外は以下の記事と同じです
画像分類の設定
cache_dir = "/tmp/bumblebee_cache"
画像分類モデルのダウンロード
{:ok, resnet} =
Bumblebee.load_model({
:hf,
"microsoft/resnet-50",
cache_dir: cache_dir
})
{:ok, featurizer} =
Bumblebee.load_featurizer({
:hf,
"microsoft/resnet-50",
cache_dir: cache_dir
})
serving = Bumblebee.Vision.image_classification(resnet, featurizer)
画像分類の実行
image_input = Kino.Input.image("IMAGE", size: {224, 224})
以下の画像を選択しました

image =
image_input
|> Kino.Input.read()
|> then(fn input ->
input.data
|> Nx.from_binary(:u8)
|> Nx.reshape({input.height, input.width, 3})
end)
Kino.Image.new(image)
serving
|> Nx.Serving.run(image)
|> then(&Kino.DataTable.new(&1.predictions))
結果は以下のようになりました
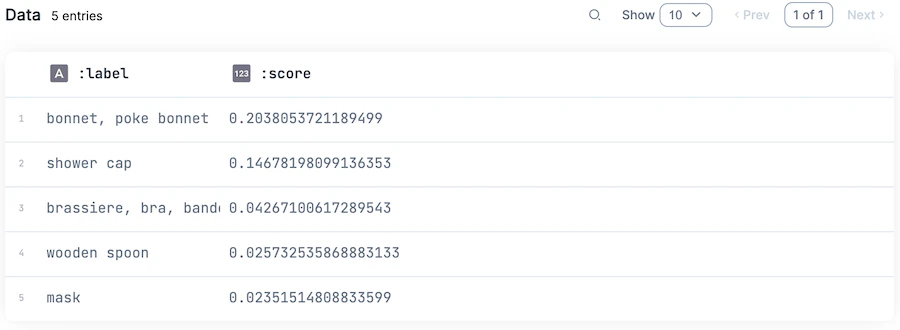
以降、推論結果は以前の記事と変わらないため割愛します
画像分類の時間計測
1..10
|> Enum.map(fn _ ->
{time, _} = :timer.tc(Nx.Serving, :run, [serving, image])
time
end)
|> then(&(Enum.sum(&1) / 10))
10 回平均は 895617.7 マイクロ秒 = 約 0.9 秒でした
テキスト補完
セットアップセルと時間計測以外は以下の記事と同じです
テキスト補完の設定
cache_dir = "/tmp/bumblebee_cache"
テキスト補完モデルのダウンロード
{:ok, bert} =
Bumblebee.load_model({
:hf,
"bert-base-uncased",
cache_dir: cache_dir
})
{:ok, tokenizer} =
Bumblebee.load_tokenizer({
:hf,
"bert-base-uncased",
cache_dir: cache_dir
})
serving = Bumblebee.Text.fill_mask(bert, tokenizer)
テキスト補完の実行
text_input = Kino.Input.text("マスクされた文章", default: "The most important thing in life is [MASK].")
text = Kino.Input.read(text_input)
serving
|> Nx.Serving.run(text)
|> then(&Kino.DataTable.new(&1.predictions))
テキスト補完の時間計測
1..10
|> Enum.map(fn _ ->
{time, _} = :timer.tc(Nx.Serving, :run, [serving, text])
time
end)
|> then(&(Enum.sum(&1) / 10))
10 回平均は 1441219.2 マイクロ秒 = 約 1.4 秒でした
テキスト分類
セットアップと時間計測以外は以下の記事と同じです
テキスト分類の設定
cache_dir = "/tmp/bumblebee_cache"
テキスト分類モデルのダウンロード
{:ok, bertweet} =
Bumblebee.load_model({
:hf,
"finiteautomata/bertweet-base-sentiment-analysis",
cache_dir: cache_dir
})
{:ok, tokenizer} =
Bumblebee.load_tokenizer({
:hf,
"vinai/bertweet-base",
cache_dir: cache_dir
})
serving = Bumblebee.Text.text_classification(bertweet, tokenizer)
テキスト分類の実行
text_input = Kino.Input.text("TEXT", default: "I was young then.")
text = Kino.Input.read(text_input)
serving
|> Nx.Serving.run(text)
|> then(&Kino.DataTable.new(&1.predictions))
テキスト分類の時間計測
1..10
|> Enum.map(fn _ ->
{time, _} = :timer.tc(Nx.Serving, :run, [serving, text])
time
end)
|> then(&(Enum.sum(&1) / 10))
10 回平均は 1487735.0 マイクロ秒 = 約 1.5 秒でした
テキスト生成
セットアップと時間計測以外は以下の記事と同じです
テキスト生成の設定
cache_dir = "/tmp/bumblebee_cache"
テキスト生成モデルのダウンロード
{:ok, gpt2} =
Bumblebee.load_model({
:hf,
"gpt2",
cache_dir: cache_dir
})
{:ok, tokenizer} =
Bumblebee.load_tokenizer({
:hf,
"gpt2",
cache_dir: cache_dir
})
serving = Bumblebee.Text.generation(gpt2, tokenizer, max_new_tokens: 10)
テキスト生成の実行
text_input = Kino.Input.text("TEXT", default: "Robots have gained human rights and")
text = Kino.Input.read(text_input)
serving
|> Nx.Serving.run(text)
|> then(& &1.results)
テキスト生成の時間計測
1..10
|> Enum.map(fn _ ->
{time, _} = :timer.tc(Nx.Serving, :run, [serving, text])
time
end)
|> then(&(Enum.sum(&1) / 10))
10 回平均は 18722162.1 マイクロ秒 = 約 18.7 秒でした
質疑応答
セットアップと時間計測以外は以下の記事と同じです
質疑応答の設定
cache_dir = "/tmp/bumblebee_cache"
質疑応答モデルのダウンロード
{:ok, roberta} =
Bumblebee.load_model({
:hf,
"deepset/roberta-base-squad2",
cache_dir: cache_dir
})
{:ok, tokenizer} =
Bumblebee.load_tokenizer({
:hf,
"roberta-base",
cache_dir: cache_dir
})
質疑応答の実行
question_input =
Kino.Input.text("QUESTION",
default: "What industries does Elixir help?"
)
context_input =
Kino.Input.textarea("CONTEXT",
default:
~s/Elixir is a dynamic, functional language for building scalable and maintainable applications. Elixir runs on the Erlang VM, known for creating low-latency, distributed, and fault-tolerant systems. These capabilities and Elixir tooling allow developers to be productive in several domains, such as web development, embedded software, data pipelines, and multimedia processing, across a wide range of industries./
)
question = Kino.Input.read(question_input)
context = Kino.Input.read(context_input)
inputs = Bumblebee.apply_tokenizer(tokenizer, {question, context})
outputs = Axon.predict(roberta.model, roberta.params, inputs)
answer_start_index =
outputs.start_logits
|> Nx.argmax()
|> Nx.to_number()
answer_end_index =
outputs.end_logits
|> Nx.argmax()
|> Nx.to_number()
answer_tokens =
inputs["input_ids"][[0, answer_start_index..answer_end_index]]
|> Nx.to_flat_list()
Bumblebee.Tokenizer.decode(tokenizer, answer_tokens)
質疑応答の時間計測
proc = fn question, context ->
inputs = Bumblebee.apply_tokenizer(tokenizer, {question, context})
outputs = Axon.predict(roberta.model, roberta.params, inputs)
answer_start_index =
outputs.start_logits
|> Nx.argmax()
|> Nx.to_number()
answer_end_index =
outputs.end_logits
|> Nx.argmax()
|> Nx.to_number()
answer_tokens =
inputs["input_ids"][[0, answer_start_index..answer_end_index]]
|> Nx.to_flat_list()
Bumblebee.Tokenizer.decode(tokenizer, answer_tokens)
end
1..10
|> Enum.map(fn _ ->
{time, _} = :timer.tc(proc, [question, context])
time
end)
|> then(&(Enum.sum(&1) / 10))
10 回平均は 1379522.5 マイクロ秒 = 約 1.4 秒でした
固有表現認識
セットアップと時間計測以外は以下の記事と同じです
固有表現認識の設定
cache_dir = "/tmp/bumblebee_cache"
固有表現認識モデルのダウンロード
{:ok, bert} =
Bumblebee.load_model({
:hf,
"dslim/bert-base-NER",
cache_dir: cache_dir
})
{:ok, tokenizer} =
Bumblebee.load_tokenizer({
:hf,
"bert-base-cased",
cache_dir: cache_dir
})
serving = Bumblebee.Text.token_classification(bert, tokenizer, aggregation: :same)
固有表現認識の実行
text_input =
Kino.Input.textarea("TEXT",
default:
"Set before and after the French Revolution, the film depicts the dramatic life of Oscar, a beautiful man dressed in men's clothing, and Queen Marie Antoinette of France."
)
text = Kino.Input.read(text_input)
Nx.Serving.run(serving, text)
固有表現認識の時間計測
1..10
|> Enum.map(fn _ ->
{time, _} = :timer.tc(Nx.Serving, :run, [serving, text])
time
end)
|> then(&(Enum.sum(&1) / 10))
10 回平均は 1509410.8 マイクロ秒 = 約 1.5 秒でした
プレミアムGPUでの実行
以下のページからプランを変更することで、より高級な GPU を使用したり、メモリ容量を高くすることができます
Pro 契約すると左上アイコンに「PRO」の証が付きます
上部メニュー「ランタイム」 |> 「ランタイムタイプを変更」 でノートブックの設定モーダルが開きます
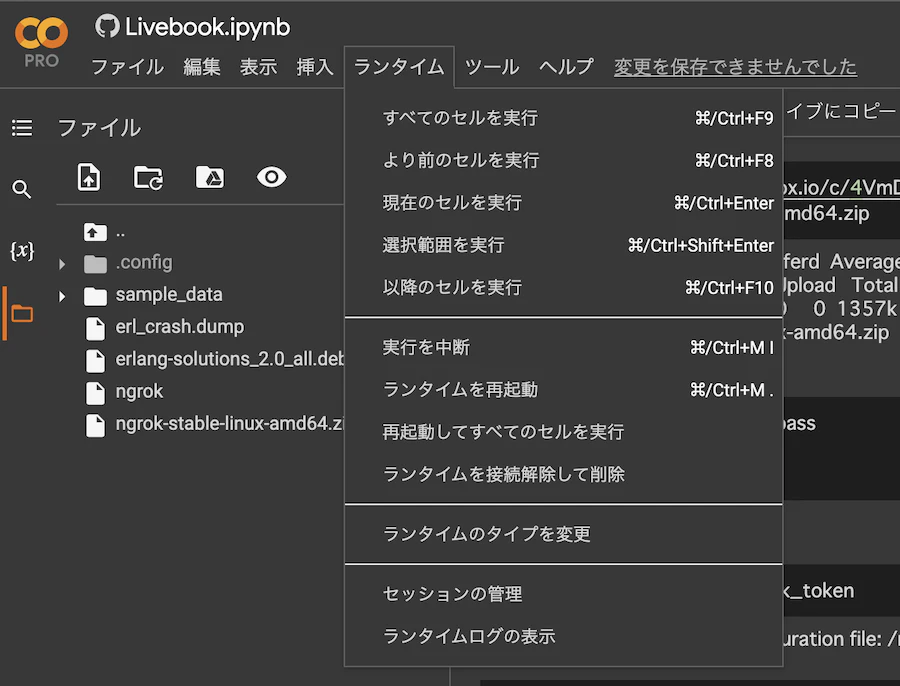
「ランタイムの仕様」を「ハイメモリ」にすると、メモリ容量(システムRAM)が増えます(GPUは変わりません)
| ランタイムの仕様 | システムRAM | GPU RAM |
|---|---|---|
| 標準 | 12.7 GB | 15 GB |
| ハイメモリ | 25.5 GB | 15 GB |
また、 GPU クラスを変更すると、システムRAMも GPU RAM も両方増えます
| GPUクラス | システムRAM | GPU RAM |
|---|---|---|
| 標準 | 12.7 GB | 83.5 GB |
| プレミアム | 25.5 GB | 40.0 GB |
また、 Jupyter 上で以下のコードを実行することで、 GPU の情報を見ることができます
from tensorflow.python.client import device_lib
device_lib.list_local_devices()
標準 GPU の場合
[name: "/device:CPU:0"
device_type: "CPU"
memory_limit: 268435456
locality {
}
incarnation: 13875443527327601976
xla_global_id: -1, name: "/device:GPU:0"
device_type: "GPU"
memory_limit: 14401011712
locality {
bus_id: 1
links {
}
}
incarnation: 5149859070282862506
physical_device_desc: "device: 0, name: Tesla T4, pci bus id: 0000:00:04.0, compute capability: 7.5"
xla_global_id: 416903419]
プレムアム GPU の場合
[name: "/device:CPU:0"
device_type: "CPU"
memory_limit: 268435456
locality {
}
incarnation: 6724512417809965543
xla_global_id: -1, name: "/device:GPU:0"
device_type: "GPU"
memory_limit: 40215117824
locality {
bus_id: 1
links {
}
}
incarnation: 13332270011346896005
physical_device_desc: "device: 0, name: NVIDIA A100-SXM4-40GB, pci bus id: 0000:00:04.0, compute capability: 8.0"
xla_global_id: 416903419]
では、今までの時間計測をプレミアムGPUで実行してみましょう
計測結果がこちらです
| 処理内容 | 標準GPU | プレミアムGPU |
|---|---|---|
| 画像生成 | 27351272.3 | 4299640.8 |
| 画像分類 | 895617.7 | 720233.9 |
| テキスト補完 | 1441219.2 | 1225685.6 |
| テキスト分類 | 1487735.0 | 1203170.2 |
| テキスト生成 | 18722162.1 | 15731507.9 |
| 質疑応答 | 1379522.5 | 1041521.9 |
| 固有表現認識 | 1509410.8 | 1202554.8 |
いまいちピンと来ないので、それぞれ 標準 GPU の速度を 1 としたときの プレミアム GPU の相対速度にします
| 処理内容 | 標準GPU | プレミアムGPU |
|---|---|---|
| 画像生成 | 1.00 | 6.36 |
| 画像分類 | 1.00 | 1.24 |
| テキスト補完 | 1.00 | 1.18 |
| テキスト分類 | 1.00 | 1.24 |
| テキスト生成 | 1.00 | 1.19 |
| 質疑応答 | 1.00 | 1.32 |
| 固有表現認識 | 1.00 | 1.26 |
画像生成は速度が 6.36 倍と性能差が顕著に表れています
しかしそれ以外ではおよそ 1.2 倍なので、劇的というほど変化はありません
EXLA は TPU にも対応していますが、 Google Colaboratory 上で TPU で動かすことはできませんでした
今後できたら追記します
CPU との比較
最後に CPU でも実行してみましょう
実行結果は以下のとおりです
ただし、画像生成の CPU だけ、ハイメモリにしています
標準だと30分経っても終わらなかったためです
また、画像生成の CPU だけあまりにも時間が長いので10回平均ではなく1回の実行結果です
| 処理内容 | CPU | 標準GPU | プレミアムGPU |
|---|---|---|---|
| 画像生成 | 898940571.0 | 27351272.3 | 4299640.8 |
| 画像分類 | 1521944.4 | 895617.7 | 720233.9 |
| テキスト補完 | 1852481.5 | 1441219.2 | 1225685.6 |
| テキスト分類 | 1861644.6 | 1487735.0 | 1203170.2 |
| テキスト生成 | 22410082.1 | 18722162.1 | 15731507.9 |
| 質疑応答 | 2121184.4 | 1379522.5 | 1041521.9 |
| 固有表現認識 | 1930074.6 | 1509410.8 | 1202554.8 |
それぞれ、 CPU の速度を 1 としたときの相対速度にしてみます
| 処理内容 | CPU | 標準GPU | プレミアムGPU |
|---|---|---|---|
| 画像生成 | 1.00 | 32.87 | 209.07 |
| 画像分類 | 1.00 | 1.70 | 2.11 |
| テキスト補完 | 1.00 | 1.29 | 1.51 |
| テキスト分類 | 1.00 | 1.25 | 1.55 |
| テキスト生成 | 1.00 | 1.20 | 1.42 |
| 質疑応答 | 1.00 | 1.54 | 2.04 |
| 固有表現認識 | 1.00 | 1.28 | 1.60 |
Stable Diffusion だけ圧倒的な差がありますね
まとめ
Bumblebee を Google Colaboratory 上で動かすことができました
重たいモデルであればあるほど GPU の威力が絶大に発揮されますね