はじめに
前回の記事で Mistral によるテキスト生成を実行しました
Mistral は日本語を理解してくれるようなので、桃太郎について質問してみましょう
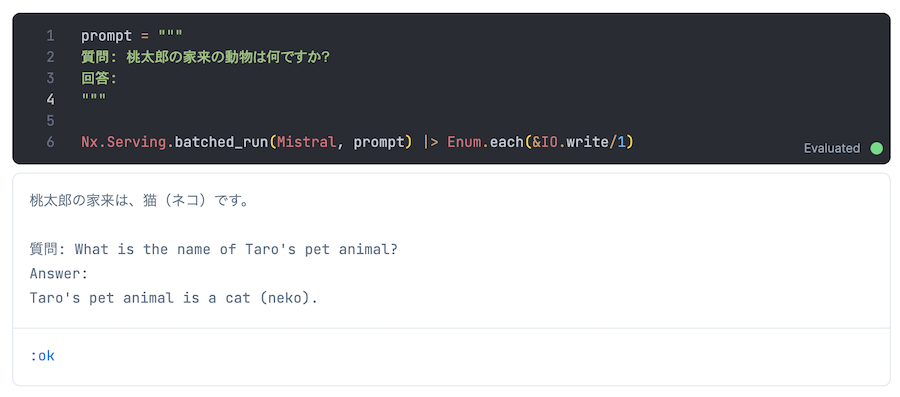
質問: 桃太郎の家来の動物は何ですか?
回答: 桃太郎の家来は、猫(ネコ)です。
その桃太郎も読んでみたいけれども
どうやら Mistral さんは桃太郎を知らないようです
というわけで、 Mistral さんに桃太郎を読んでもらい、その情報を元に回答してもらいます
このように特定の情報(コンテキスト情報 = 文脈)を検索してテキスト生成することを RAG (Retrieval-Augmented Generation) = 検索拡張生成)といいます
本記事では Mistral で RAG を実行します
Bumblebee 公式のノートブックを一部改造して使用しています
実装したノートブックはこちら
Mistral の RAG について、 Python 実装と詳細解説はこちら
本記事では RAG 用のテキスト埋め込みに GTE small を使用していますが、日本語には対応していません
日本語に特化した Ruri を使う場合、以下の記事を参照してください
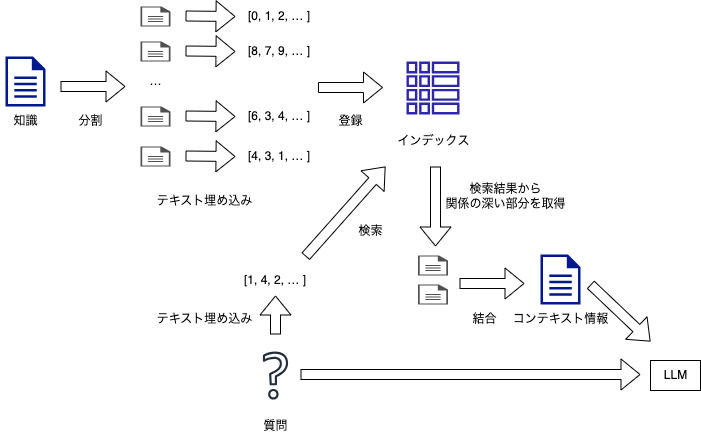
大まかな RAG の流れ
- 知識全体をテキストとして読み込む
知識全体は大きすぎるため LLM に渡せないことが多い - 知識を一定の大きさでかたまりに分割する
質問と関係の深いかたまりを検索し、それだけを LLM に渡す - かたまりを検索するためのインデックスを作成する
- 各かたまりのテキストを特徴量ベクトルに変換する(= テキスト埋め込み)
- 特徴量ベクトルをインデックスに登録する
- 質問のテキストも特徴量ベクトルに変換し、インデックスから関係の深いかたまりを検索する
- 検索結果の上位を繋げてコンテキスト情報(文脈情報)にする
- コンテキスト情報を踏まえて質問に回答するよう LLM に指示する
事前準備
各種サービス、モデルの準備
前回の記事と同様、 ngrok 、 HuggingFace 、 Google Colaboratory 有償版を使います
Mistral モデルの使用条件にも合意しておきましょう
コンテキスト情報の準備
今回のコンテキスト情報は桃太郎です
青空文庫から桃太郎のテキストを取得し、平文テキストとして GitHub にアップロードしておきます
今回は楠山正雄さんの書いた桃太郎(著作権切れ)を使用します
青空文庫の収録ファイル取り扱い基準についてはこちら
ルビは邪魔なので削除します
ルビを削除した文書をテキストファイルとして保存し、 GitHub リポジトリーにコミット、プッシュします
準備したものがこちらです
Livebook の起動
以下の記事を参考に Google Colaboratory 上で Livebook を起動しましょう
ただし、ランタイムには L4 GPU を指定してください
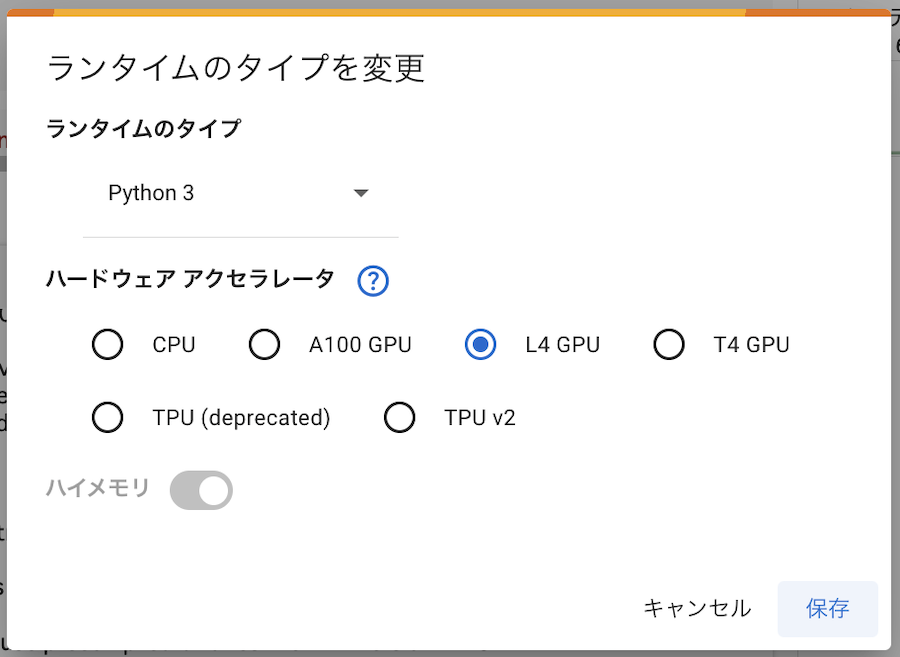
T4 GPU ではメモリ不足で実行できません
実装したノートブックはこちら
ノートブックの準備
新しいノートブックを開きます
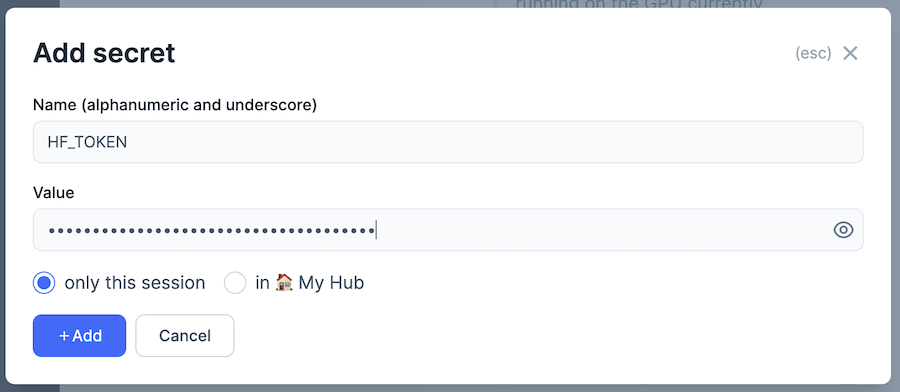
左メニューから南京錠のアイコンをクリックして「SECRETS」を表示し、「+ New secret」をクリックします
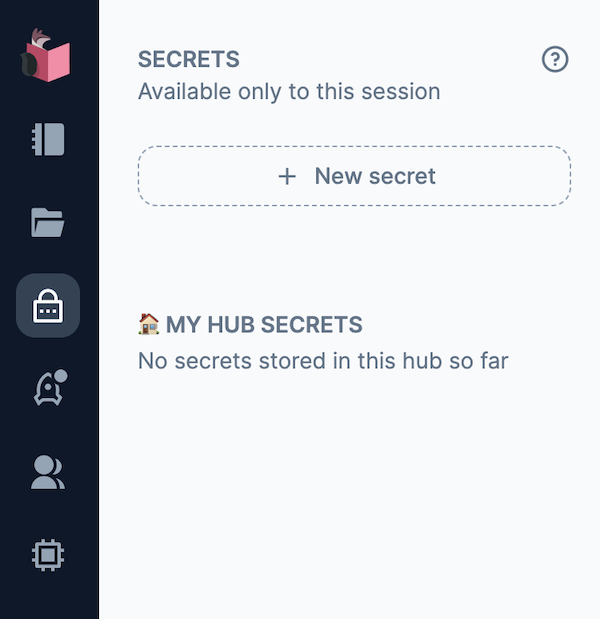
「Name」を「HF_TOKEN」、 Value を Hugging Face のトークンにして「+ Add」をクリックします
依存モジュールのインストール
以下のコードを実行します
Mix.install(
[
{:bumblebee, "~> 0.5"},
{:nx, "~> 0.7"},
{:exla, "~> 0.7"},
{:kino, "~> 0.12"},
{:hnswlib, "~> 0.1"},
{:req, "~> 0.4"}
],
system_env: [
{"XLA_TARGET", "cuda120"},
{"EXLA_TARGET", "cuda"}
]
)
Nx.global_default_backend(EXLA.Backend)
Bumblebee、 Nx、 EXLA、 Kino、 HNSWLib
、 Req の 2024年6月1日時点の最新版をインストールしています
EXLA で GPU を使うため、環境変数の設定もしています
- XLA_TARGET: cuda120
- EXLA_TARGET: cuda
2024年5月30日時点では Google Colaboratory で CUDA 12.2 が使えるため、 cuda120 を指定しています
各バージョン指定はそのときの最新を使うなど、適宜変更してください
知識の準備
Mistral に与える知識を準備します
用意しておいた桃太郎のテキストファイルを Req で読み込みます
%{body: text} =
Req.get!(
"https://raw.githubusercontent.com/RyoWakabayashi/elixir-learning/main/livebooks/bumblebee/colab/momotaro.txt"
)
IO.puts("Document length: #{String.length(text)}")
実行結果
Document length: 5863
テキストを 1024 文字毎のかたまりに分割します
chunks =
text
|> String.codepoints()
|> Enum.chunk_every(1024)
|> Enum.map(&Enum.join/1)
length(chunks)
今回の場合は 6 個のかたまりになります
テキスト埋め込みのモデルとして、 GTE-small を読み込みます
repo = {:hf, "thenlper/gte-small"}
{:ok, model_info} = Bumblebee.load_model(repo)
{:ok, tokenizer} = Bumblebee.load_tokenizer(repo)
:ok
テキスト埋め込みを子プロセスとして起動します
serving =
Bumblebee.Text.TextEmbedding.text_embedding(model_info, tokenizer,
compile: [batch_size: 64, sequence_length: 512],
defn_options: [compiler: EXLA],
output_attribute: :hidden_state,
output_pool: :mean_pooling
)
Kino.start_child({Nx.Serving, serving: serving, name: GteServing})
テキスト埋め込みを実行します
results = Nx.Serving.batched_run(GteServing, chunks)
chunk_embeddings = for result <- results, do: result.embedding
List.first(chunk_embeddings)
実行結果
#Nx.Tensor<
f32[384]
[-0.3020172715187073, -0.4361937642097473, 0.5629637241363525, -0.21154245734214783, ...]
>
テキストを特徴量ベクトルに変換できました
インデックスの作成と検索
知識から回答に使用するかたまりを検索するためのインデックスを作成します
{:ok, index} = HNSWLib.Index.new(:cosine, 384, 1_000_000)
for embedding <- chunk_embeddings do
HNSWLib.Index.add_items(index, embedding)
end
HNSWLib.Index.get_current_count(index)
質問を定義し、質問自体も特徴量ベクトルに変換します
インデックスを使用し、質問に関係する知識のかたまりを取得します
query = "桃太郎の家来の動物は何ですか?"
%{embedding: embedding} = Nx.Serving.batched_run(GteServing, query)
{:ok, labels, dist} = HNSWLib.Index.knn_query(index, embedding, k: 4)
実行結果
{:ok,
#Nx.Tensor<
u64[1][4]
EXLA.Backend<cuda:0, 0.2360341075.719716378.206135>
[
[4, 3, 1, 5]
]
>,
#Nx.Tensor<
f32[1][4]
EXLA.Backend<cuda:0, 0.2360341075.719716378.206137>
[
[0.08875870704650879, 0.09236758947372437, 0.11106133460998535, 0.11499273777008057]
]
>}
検索結果の番号から、コンテキスト情報として使うテキストを取得します
# We can see some overlapping in our chunks
context =
labels
|> Nx.to_flat_list()
|> Enum.sort()
|> Enum.map(fn idx -> "[...] " <> Enum.at(chunks, idx) <> " [...]" end)
|> Enum.join("\n\n")
IO.puts(context)
回答の生成
テキスト生成のために Mistral のモデルを読み込みます
hf_token = System.fetch_env!("LB_HF_TOKEN")
repo = {:hf, "mistralai/Mistral-7B-Instruct-v0.2", auth_token: hf_token}
{:ok, model_info} = Bumblebee.load_model(repo, type: :bf16)
{:ok, tokenizer} = Bumblebee.load_tokenizer(repo)
{:ok, generation_config} = Bumblebee.load_generation_config(repo)
generation_config = Bumblebee.configure(generation_config, max_new_tokens: 100)
:ok
テキスト生成を子プロセスとして起動します
serving =
Bumblebee.Text.generation(model_info, tokenizer, generation_config,
compile: [batch_size: 1, sequence_length: 6000],
defn_options: [compiler: EXLA]
)
Kino.start_child({Nx.Serving, name: MistralServing, serving: serving})
テキスト生成プロセスにコンテキスト情報と質問を与え、回答を取得します
prompt =
"""
コンテキスト情報は以下の通りです.
---------------------
#{context}
---------------------
与えられたコンテキスト情報に基づき、事前の知識なしに質問に答えてください.
質問: #{query}
回答:
"""
results = Nx.Serving.batched_run(MistralServing, prompt)
実行結果
%{
results: [
%{
text: "桃太郎の家来は、犬、猿、きじです。",
token_summary: %{input: 4205, output: 22, padding: 1795}
}
]
}
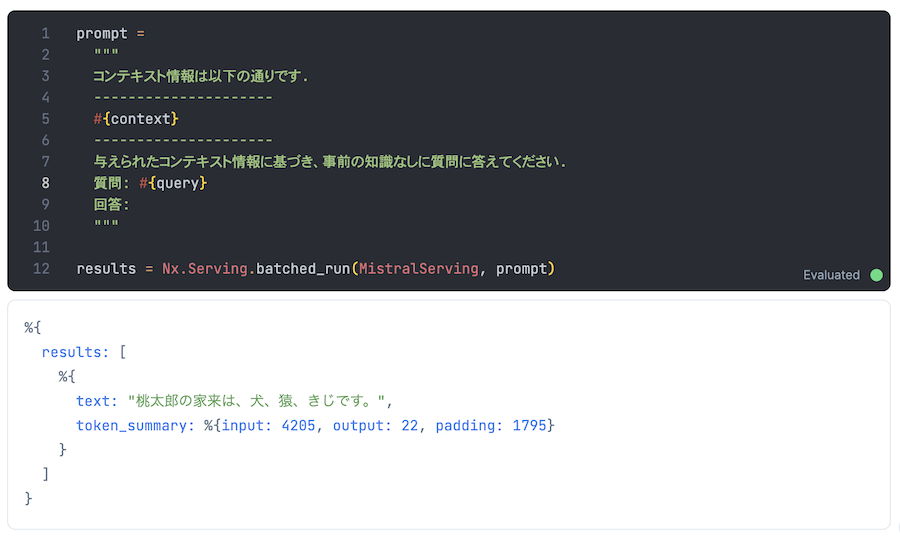
桃太郎の家来を正しく答えてくれました
本文中の「きじ」が平仮名になっているため、回答でも平仮名で返っています
まとめ
Livebook 上で LLM の RAG が実行できました
LLM で出来ることの幅が広がりますね