はじめに
Livebook は Elixir のコードをブラウザから実行し、様々なことを自動化できるツールです
Livebook では一連の処理と実行結果をノートブックとして保存、共有することができます
また、実装したものをそのままアプリとして公開することも可能です
本記事では Livebook と Ollama を利用して、生成 AI とブラウザ上でチャットするアプリを実装します
事前準備
Ollama のインストール
Ollama の公式サイトからインストーラーをダウンロードし、実行してください
インストールすると、ターミナル( Windows の場合はコマンドプロンプトや PowerShell など)から生成 AI とチャットできるようになります
本記事では軽量な Gemma 3 の 1B モデルを使用します
ターミナルで以下のコマンドを実行してください
ollama run gemma3:1b
以下のように表示され、 Gemma3 1B のモデルファイルがダウンロードされてチャットが始まります
pulling manifest
pulling dbe81da1e4ba... 100% ▕████████████████▏ 815 MB
pulling e0a42594d802... 100% ▕████████████████▏ 358 B
pulling dd084c7d92a3... 100% ▕████████████████▏ 8.4 KB
pulling 0a74a8735bf3... 100% ▕████████████████▏ 55 B
pulling cc0038d7c4c6... 100% ▕████████████████▏ 492 B
verifying sha256 digest
writing manifest
success
>>>
何らか指示や質問をすると、応えてくれます
>>> 可愛いネコのアスキーアートを作って
承知しました。可愛いネコのアスキーアートを作成します。
/\_/\
( o.o )
> ^ <
**解説:**
* `/\_/\`: ネコの耳
* `( o.o )`: ネコの顔
* `> ^ <`: ネコの口
**さらに可愛くするために:**
もし、さらに可愛くしたい場合は、以下のように調整できます。
* **目の大きさを大きくする:** `( o.o )` の目を少し大きくする
* **鼻を少し長くする:** `> ^ <` の鼻を少し長くする
* **背景色を少しする:** 背景色を少し明るくしたり、少し色を付けたりすると
、より可愛らしくなります。
**例:背景色を少し明るくする**
/\_/\
( o.o )
> ^ <
\ /
\/
**もし、何か特定のスタイルや、ネコの特徴(例えば、ふわふわの毛並みなど)があ
れば、教えてください。**
例:
* 「ふわふわの毛並みのネコ」
* 「丸いネコ」
* 「夜のネコ」
など、ご要望に応じて調整します。
Ctrl + d でチャットを終了します
Ollama サーバーの起動
Ollama は以下のアイコンで Launcher に追加されているので、未起動であれば起動しておきましょう

Ollama のアプリケーションを起動しているとき、 Ollama は API サーバーとして起動しています
停止する場合、メニューバーに表示されている Ollama アイコンから Quit Ollama をクリックしてください

インストーラー以外の方法でインストールしたなど、 GUI が存在していない場合、以下のコマンドで API サーバーを起動します
ollama serve
Livebook のインストール
Livebook の公式サイトからインストーラーをダウンロードして実行してください
macOS の場合、インストーラーを実行すると以下のように Finder が開くので、 Livebook のアイコンを Applications のディレクトリーにドラッグ&ドロップしてください

インストールしたら Livebook を起動してください(macOS の場合は Launchpad から Livebook のアイコンをクリック)

ブラウザで以下のような画面が開きます

Livebook でのチャット実装
ノートブックの取得
Livebook の画面右上 Open のボタンをクリックしてください
開いた画面で From URL タブを選択し、 Notebook URL に https://github.com/RyoWakabayashi/elixir-learning/blob/main/livebooks/ollama/chat_with_gemma_3.livemd と入力してください
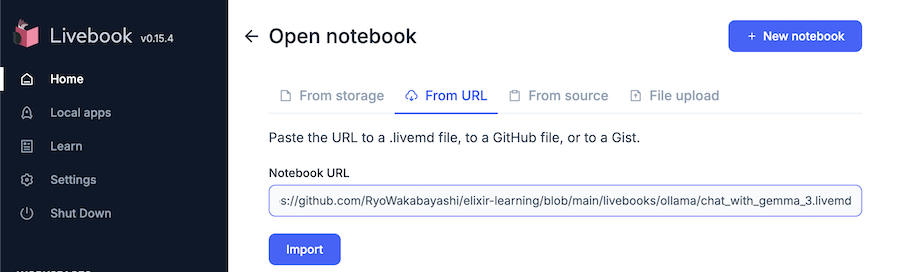
Import ボタンをクリックすると、以下のような画面が表示されます
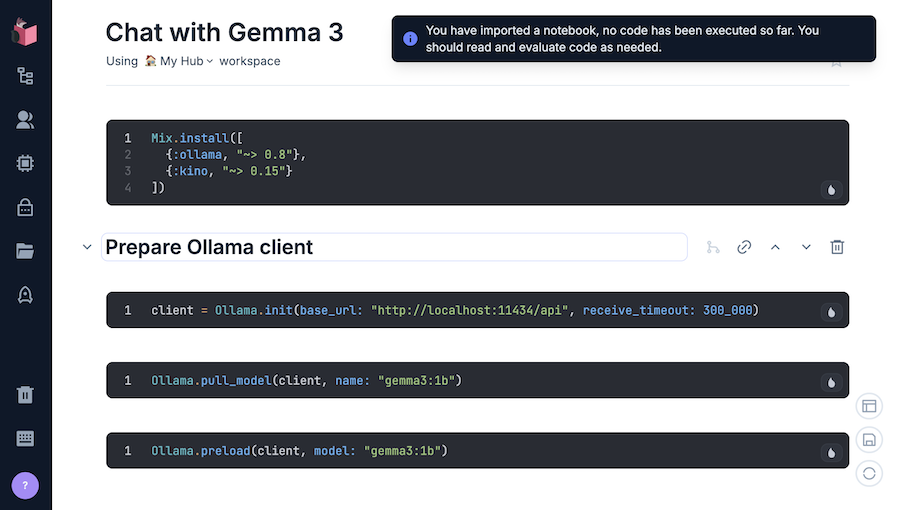
セットアップ
一番上にある、以下のコードが書かれているセル(黒い枠)をクリックしてください
Mix.install([
{:ollama, "~> 0.8"},
{:kino, "~> 0.15"}
])
以下のように、左上に Setup と表示されるので、 Setup をクリックしてください

一番上のセルはセットアップセルというもので、ノートブックの実装に必要な外部モジュールのインストールなどを実行します
しばらくすると :ok と実行結果が表示されます

セットアップセルの実行により、以下のモジュールがインストールされました
Ollama クライアントの準備
次のセルをクリックすると、左上に Evaluate という文字が表示されます

Evaluate をクリックすることで、セル内のコード(以下に示すコード)が実行されます(以降も同様の手順で実行できます)
client = Ollama.init(base_url: "http://localhost:11434/api", receive_timeout: 300_000)
セルの実行結果が以下のように表示されます
%Ollama{
req: %Req.Request{
method: :get,
url: URI.parse(""),
headers: %{"user-agent" => ["ollama-ex/0.8.0"]},
body: nil,
options: %{receive_timeout: 300000, base_url: "http://localhost:11434/api"},
halted: false,
adapter: &Req.Steps.run_finch/1,
request_steps: [
put_user_agent: &Req.Steps.put_user_agent/1,
compressed: &Req.Steps.compressed/1,
encode_body: &Req.Steps.encode_body/1,
put_base_url: &Req.Steps.put_base_url/1,
auth: &Req.Steps.auth/1,
put_params: &Req.Steps.put_params/1,
put_path_params: &Req.Steps.put_path_params/1,
put_range: &Req.Steps.put_range/1,
cache: &Req.Steps.cache/1,
put_plug: &Req.Steps.put_plug/1,
compress_body: &Req.Steps.compress_body/1,
checksum: &Req.Steps.checksum/1,
put_aws_sigv4: &Req.Steps.put_aws_sigv4/1
],
response_steps: [
retry: &Req.Steps.retry/1,
handle_http_errors: &Req.Steps.handle_http_errors/1,
redirect: &Req.Steps.redirect/1,
decompress_body: &Req.Steps.decompress_body/1,
verify_checksum: &Req.Steps.verify_checksum/1,
decode_body: &Req.Steps.decode_body/1,
output: &Req.Steps.output/1
],
error_steps: [retry: &Req.Steps.retry/1],
private: %{}
}
}
事前準備でインストールしておいた Ollama に http://localhost:11434/api の URL を介してアクセスするように指定してます
receive_timeout: 300_000 は Ollama からの応答を待つ最大時間(ミリ秒単位)です
続いて次のセルも実行します
Ollama.pull_model(client, name: "gemma3:1b")
Gemma3 1b の生成 AI モデルをローカルにダウンロードしています
すでにターミナルからチャットを実行する際にダウンロード済みなので、すぐに以下の実行結果が表示されます
{:ok, %{"status" => "success"}}
続いてのセルを実行し、モデルを読み込んでおきます
Ollama.preload(client, model: "gemma3:1b")
実行結果
{:ok, true}
Gemma 3 とのチャット
次のセルを実行しましょう
messages = [
%{role: "system", content: "あなたは親切なアシスタントです"},
%{role: "user", content: "浦島太郎が助けたのは何ですか?"}
]
{:ok, %{"message" => message}} =
Ollama.chat(
client,
model: "gemma3:1b",
messages: messages
)
Gemma 3 に対して Ollama 経由で「浦島太郎が助けたのは何ですか?」という質問を投げています
少し待つと、以下のような実行結果が返ってきます
{:ok,
%{
"created_at" => "2025-03-16T14:07:38.568146Z",
"done" => true,
"done_reason" => "stop",
"eval_count" => 207,
"eval_duration" => 3616000000,
"load_duration" => 53152500,
"message" => %{
"content" => "浦島太郎が助けたのは、様々なものがありますが、主なものをいくつか挙げますね。\n\n* **浦島太郎の船「浦島太郎」**:これは、浦島太郎が助けた最も重要なものです。\n* **木ノ葉島**:浦島太郎は、木ノ葉島に住む「木ノ葉の男」を助け、その島を救いました。\n* **海賊の船**:浦島太郎は、海賊の船を捕まえて、その船を救いました。\n* **海賊の船の乗組員**:浦島太郎は、海賊の船の乗組員を救い、彼らを助けました。\n\nこれらの出来事を通して、浦島太郎は様々な人々を助け、世界を救うという使命を担っています。\n\nもし、浦島太郎が助けた具体的な出来事について知りたい場合は、どの場面について知りたいか教えてください。",
"role" => "assistant"
},
"model" => "gemma3:1b",
"prompt_eval_count" => 32,
"prompt_eval_duration" => 137000000,
"total_duration" => 3828557958
}}
このままだと返答が読みにくいので、返答の文字列だけを取り出し、 Markdown として表示します
Kino.Markdown.new(message["content"])
実行結果

Gemma3 1b は浦島太郎についてあまり詳しくないためいい加減な返答を返しますが、会話自体は成立しています
ストリーミングでのチャット
次のセルを実行してください
{:ok, stream} =
Ollama.chat(
client,
model: "gemma3:1b",
messages: messages,
stream: true
)
stream
|> Stream.map(fn chunk ->
IO.write(chunk["message"]["content"])
end)
|> Stream.run()
Ollama.chat に stream: true を指定することで、生成 AI からの返答をストリーミングで少しづつ受け取ることができます
Stream.map でストリームから応答がある度に指定した処理を実行するよう定義し、 Stream.run() でストリーミング処理を実行します
実行結果

チャットフォームの作成
以下のコードでチャットのテキスト入力、出力フレームを作ります
# 出力用フレーム
output_frame = Kino.Frame.new()
# ストリーミング用フレーム
stream_frame = Kino.Frame.new()
# 入力用フォーム
input_form =
Kino.Control.form(
[
input_text: Kino.Input.textarea("メッセージ")
],
submit: "送信"
)
initial_messages = [
%{role: "system", content: "あなたは親切なアシスタントです"}
]
# フォーム送信時の処理
Kino.listen(input_form, initial_messages, fn %{data: %{input_text: input}}, messages ->
messages = messages ++ [%{role: "user", content: input}]
Kino.Frame.append(output_frame, Kino.Markdown.new("ユーザー: " <> input))
{:ok, stream} =
Ollama.chat(
client,
model: "gemma3:1b",
messages: messages,
stream: true
)
full_response =
stream
|> Stream.transform("AI: ", fn chunk, acc ->
response = acc <> chunk["message"]["content"]
markdown = Kino.Markdown.new(response)
Kino.Frame.render(stream_frame, markdown)
{[chunk["message"]["content"]], response}
end)
|> Enum.join()
Kino.Frame.render(stream_frame, Kino.Markdown.new(""))
Kino.Frame.append(output_frame, Kino.Markdown.new("AI: " <> full_response))
{:cont, messages ++ [%{role: "assistant", content: full_response}]}
end)
# フレームを空にしておく
Kino.Frame.render(output_frame, Kino.Markdown.new(""))
Kino.Frame.render(stream_frame, Kino.Markdown.new(""))
# 入出力を並べて表示
Kino.Layout.grid([output_frame, stream_frame, input_form], columns: 1)
実行結果

アプリ化
最後に実装したフォームをアプリとして動かしてみましょう
不要セルの削除
まず、アプリで表示しない項目として、最後のセルから上3つ分のセルを削除します(最後のセルは残します)
削除対象のセルをクリックすると右上にゴミ箱アイコンが表示されるので、それぞれクリックしてください

モーダルが表示されたら赤い "Delete" ボタンをクリックしてください
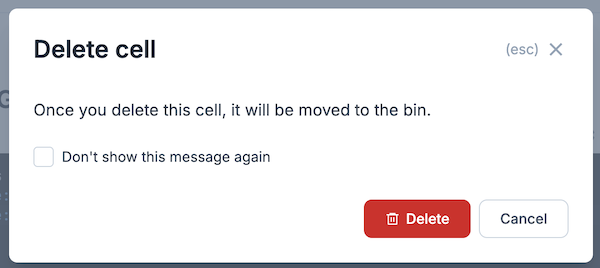
他の不要セルも同様に削除します


アプリの設定
Livebook 左メニューのロケットアイコンをクリックすると、アプリの設定が開きます

既に設定済の状態ですが、アプリの設定を確認しておきます
"Configure" のボタンをクリックしてください

以下のような設定が確認できます
- Slug: アプリの URL 末尾につく文字列
- Password-protected: チェックを付けると固定パスワードでアクセス制限できます
- Session type: チャットアプリの場合、同じ会話を全員で共有するか、会話は個別にするかを選択します
- Shutdown after inactivity: 指定した時間アクセスがない場合、アプリをシャットダウンします
- Show source: コードを表示します
- Only render rich outputs:
Kinoを使って作った要素だけを表示します - List existing sessions: 同じアプリを使っている他の人の存在を一覧表示します
今回のアプリでは最後に作ったフォームだけが表示されるようになっています
特に変更せず、右上のバツボタンでモーダルを閉じます
アプリの起動
左メニューから "Launch preview" をクリックしてください
アプリがローカルマシン上で起動し、以下のように情報が表示されます
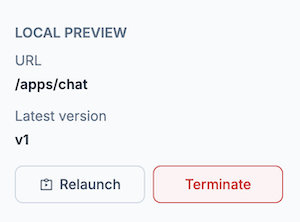
"Deploy with Livebook Teams" をクリックして手順を進めていくと、クラウド上にアプリを配置し、公開することができます
"/apps/chat" の部分がリンクになっているのでクリックします
新しいセッションを開くか確認され流ので、 "+ New session" のボタンをクリックしてください

少し待つとフォームが表示されます
チャットアプリとして会話できるようになりました

まとめ
Livebook で生成 AI チャットアプリが実装できました
しかし、 Gemma 3 1B の知識量はイマイチです
また、自分たちだけが持っている独自資料などについては当然質問しても答えてくれません
次の記事ではこのチャットアプリに RAG (検索拡張生成)という機能を追加し、あらかじめ登録しておいたドキュメントに基づいて返答するようにしてみます