はじめに
Explorer でデータ分析したい!
欠損値(nil)があるから邪魔で分析できない!
0 で埋めてしまいたい!
という人向けの記事です
Livebook で実装した全文はこちら
動作環境
以下のリポジトリーのコンテナ上で Livebook を動かしています
セットアップ
Livebook でデータフレームをデータテーブルとして表示するため、 Kino をインストールします
Mix.install([
{:explorer, "~> 0.3"},
{:kino, "~> 0.7"}
])
エイリアスをつけます
alias Explorer.DataFrame
alias Explorer.Series
データの準備
データを用意します
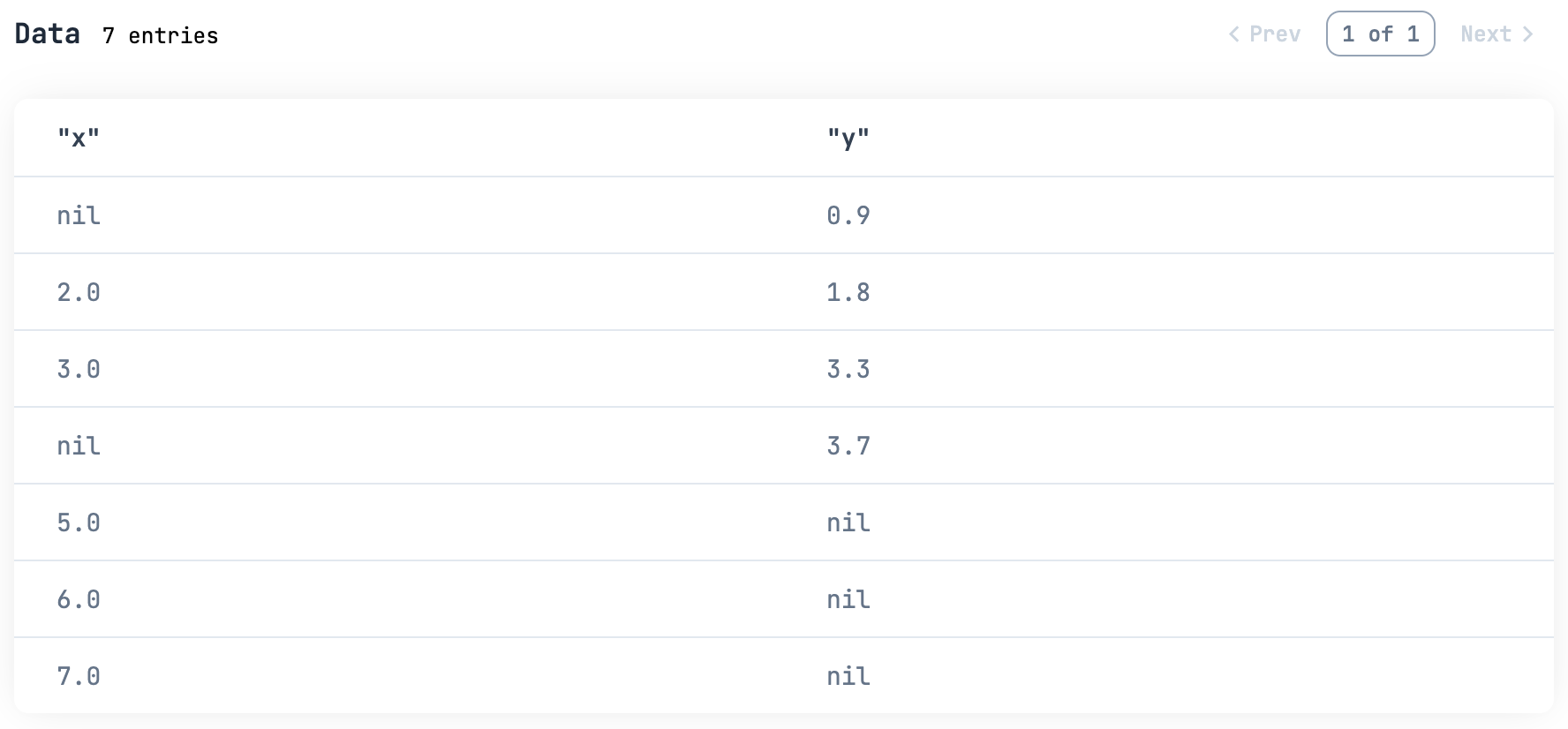
df =
%{
x: [nil, 2.0, 3.0, nil, 5.0, 6.0, 7.0],
y: [0.9, 1.8, 3.3, 3.7, nil, nil, nil]
}
|> DataFrame.new()
df
|> Kino.DataTable.new()
固定値で補完
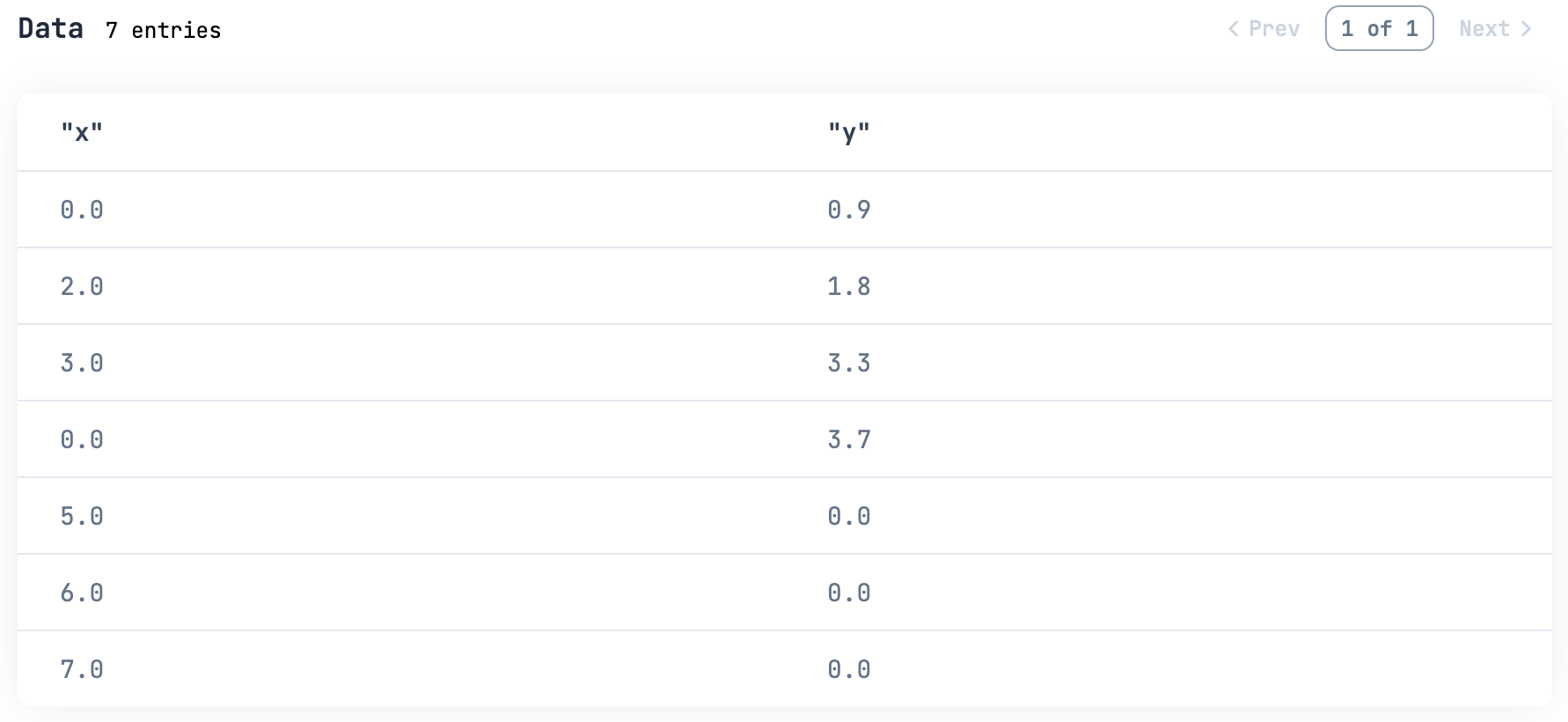
Series.fill_missing で欠損値を補完します
filled_df =
df
# データの全列に対して補完
|> DataFrame.to_series()
|> Enum.reduce(df, fn {col, _}, df ->
# 対象列について、 nil の場合は 0.0 にする
DataFrame.mutate_with(df, &%{col => Series.fill_missing(&1[col], 0.0)})
end)
filled_df
|> Kino.DataTable.new()
集計値で補完
固定値ではなく、最大値、最小値、平均値などの集計値を使って補完します
補完用の関数を定義します
fill_df = fn target_df, value ->
target_df
|> DataFrame.to_series()
|> Enum.reduce(target_df, fn {col, _}, merged_df ->
DataFrame.mutate_with(merged_df, &%{col => Series.fill_missing(&1[col], value)})
end)
end
前の値で補完
:forward を指定すると、 nil になっている行の前の行の値で補完します
先頭行が nil の場合は補完されません
df
|> fill_df.(:forward)
|> Kino.DataTable.new()

次の値で補完
:backward を指定すると、 nil になっている行の次の行の値で補完します
最終行が nil の場合は補完されません
df
|> fill_df.(:backward)
|> Kino.DataTable.new()

最大値で補完
:max を指定すると、最大値で補完します
df
|> fill_df.(:max)
|> Kino.DataTable.new()

最小値で補完
:min を指定すると、最小値で補完します
df
|> fill_df.(:min)
|> Kino.DataTable.new()

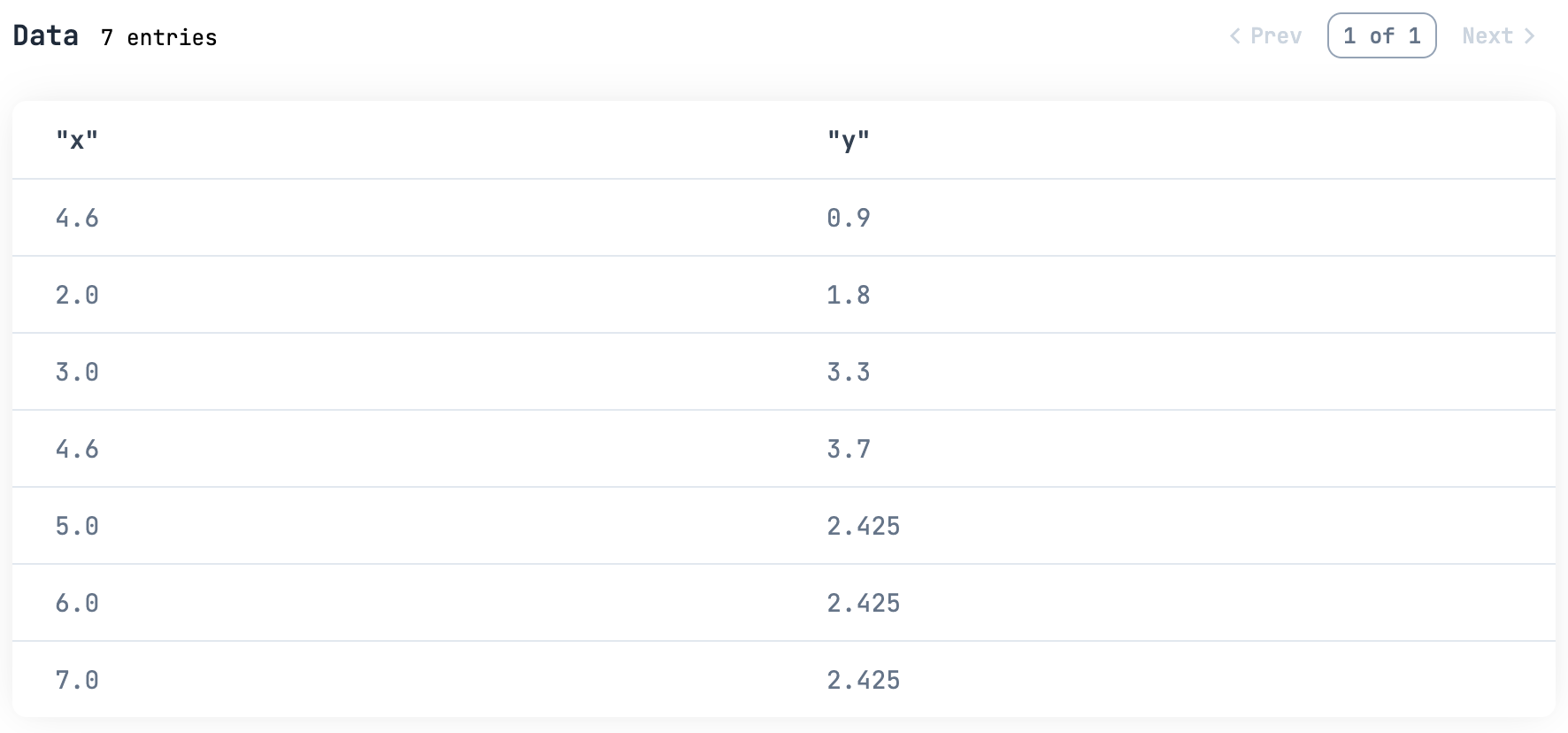
平均値で補完
:mean を指定すると、平均値で補完します
df
|> fill_df.(:mean)
|> Kino.DataTable.new()
様々な型で補完
Series には以下の型が存在します
- float
- integer
- boolean
- string
- date
- datetime
それぞれの型の Series を持つデータフレームを生成します
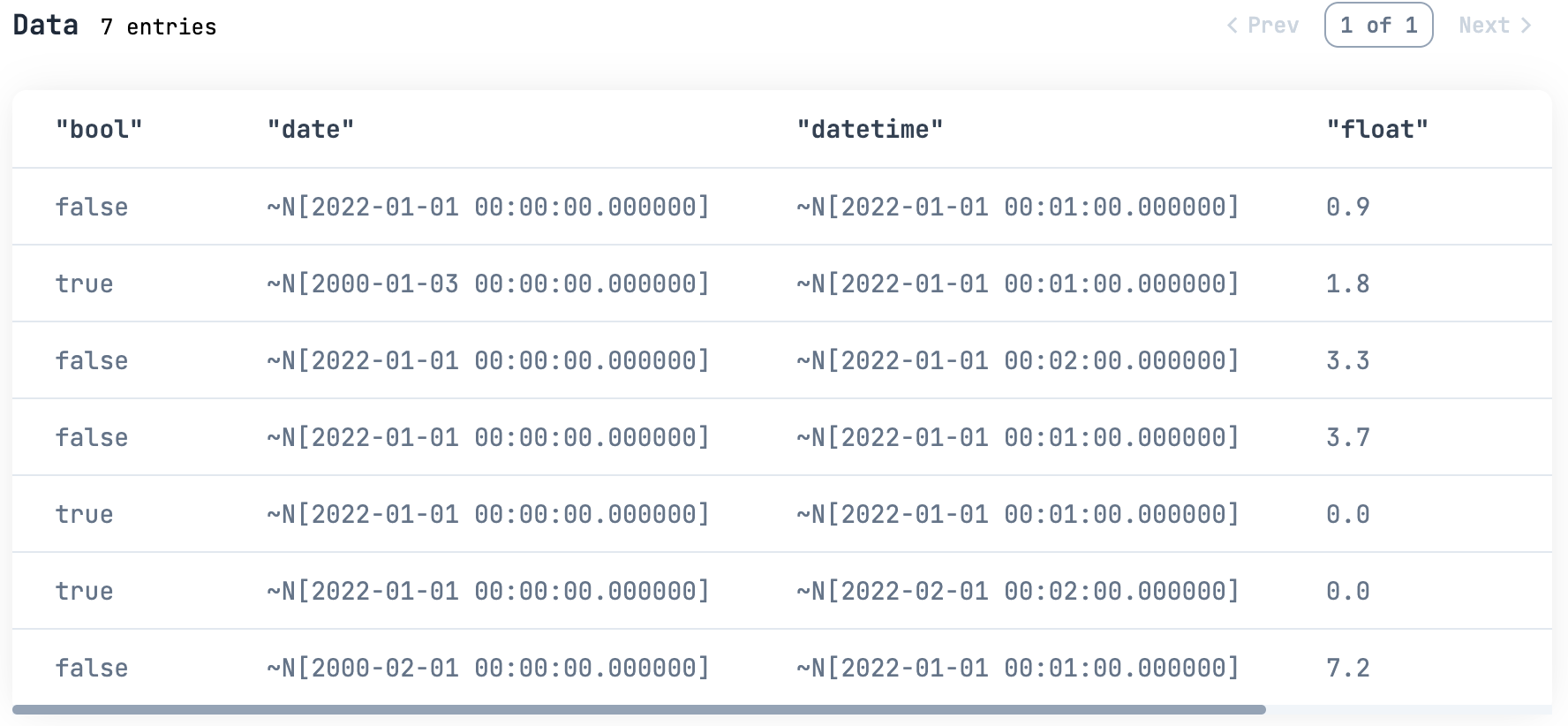
df =
%{
float: [0.9, 1.8, 3.3, 3.7, nil, nil, 7.2],
int: [1, 2, 3, nil, 5, 6, 7],
bool: [nil, true, false, nil, true, true, false],
str: ["a", nil, "c", "d", nil, "e", nil],
date: [~D[2022-01-01], ~D[2000-01-03], nil, nil, nil, nil, ~D[2000-02-01]],
datetime: [nil, ~N[2022-01-01 00:01:00], ~N[2022-01-01 00:02:00], nil, nil, ~N[2022-02-01 00:02:00], nil],
}
|> DataFrame.new()
df
|> Kino.DataTable.new()

各列の型によって補完する値を切り替えます
filled_df =
df
|> DataFrame.to_series()
|> Enum.reduce(df, fn {col, series}, df ->
DataFrame.mutate_with(df, fn lazy ->
fill_value =
case Series.dtype(series) do
:float ->
0.0
:integer ->
0
:string ->
""
:date ->
~D[2022-01-01]
:datetime ->
~N[2022-01-01 00:01:00]
:boolean ->
:min
end
%{col => Series.fill_missing(lazy[col], fill_value)}
end)
end)
filled_df
|> Kino.DataTable.new()

:boolean の場合、 true や false だと受け付けられないため、 :min を指定しています
まとめ
色々な値で補完できることが確認できました