はじめに
@piacerex さんの「Elixirで機械学習に初挑戦」シリーズを自分なりにやってみるシリーズです
- 前編:
- 後編:
今回も Livebook を使います
Elixirで機械学習に初挑戦④:データ処理に強いElixirでKaggle挑戦(前半)…「データ前処理」の基礎編
今回は Kaggle のタイタニックデータを使って、乗客の生き残りを学習・予測します
実装したノートブックはこちら
アカウントの作成
Kaggle のアカウントを作成します
トップページの右上「Register」をクリックし、指示に従っていけば簡単に作成できます
データのダウンロード
以下のページ右下「Download All」をクリックし、 taitanic.zip をダウンロードします
tainanic.zip を展開して出てくる以下の CSV ファイルを使用します
- train.csv: 学習データ
- test.csv: テストデータ
セットアップ
Livebook で新しいノートブックを開き、以下のコードを実行します
Mix.install([
{:csv, "~> 3.0"},
{:exla, "~> 0.5"},
{:axon, "~> 0.5"},
{:kino, "~> 0.9"},
{:kino_vega_lite, "~> 0.1"}
])
- CSV: CSV 操作
- EXLA: 高速行列演算
- Axon: 機械学習
- Kino: Livebook の UI/UX
- Kino VegaLite: Livebook でのグラフ出力
データの選択
Kino.Input.file を使ってファイル選択の UI を作ります
train_data_input = Kino.Input.file("train data")
ファイル選択で「train.csv」を選択し、アップロードします
同じく、「test.csv」をアップロードします
test_data_input = Kino.Input.file("test data")
前処理
@piacerex さんは List of Map の形で処理していたので、私は Map of List の形で処理していきます
また、ファイル入出力には Kino の力を活用します
CSV の読込
アップロードした学習データを読み込みます
先頭行はヘッダー、それ以外はデータ行です
[header_org | rows_org] =
train_data_input
|> Kino.Input.read()
|> Map.get(:file_ref)
|> Kino.Input.file_path()
|> File.stream!()
|> CSV.decode!()
|> Enum.to_list()
2023/04/02
Kino の更新により、ファイル読込の処理が変わったので更新しました
結果は以下のようになります
[
["PassengerId", "Survived", "Pclass", "Name", "Sex", "Age", "SibSp", "Parch", "Ticket", "Fare",
"Cabin", "Embarked"],
["1", "0", "3", "Braund, Mr. Owen Harris", "male", "22", "1", "0", "A/5 21171", "7.25", "", "S"],
["2", "1", "1", "Cumings, Mrs. John Bradley (Florence Briggs Thayer)", "female", "38", "1", "0",
"PC 17599", "71.2833", "C85", "C"],
["3", "1", "3", "Heikkinen, Miss. Laina", "female", "26", "0", "0", "STON/O2. 3101282", "7.925",
"", "S"],
...
]
ヘッダーを Atom に変換します
header =
header_org
|> Enum.map(fn column_name ->
column_name
|> String.downcase()
|> String.to_atom()
end)
結果は以下の通り
[:passengerid, :survived, :pclass, :name, :sex, :age, :sibsp, :parch, :ticket, :fare, :cabin,
:embarked]
train_data =
header
|> Enum.with_index()
|> Enum.into(%{}, fn {key, index} ->
{
key,
Enum.map(rows_org, &Enum.at(&1, index))
}
end)
各列毎に List 化します
以下のような形式になります
%{
age: ["22", "38", "26", "35", "35", "", "54", "2", "27", "14", "4", "58", "20", "39", "14", "55",
"2", "", "31", "", "35", "34", "15", "28", "8", "38", "", "19", "", "", "40", "", "", "66", "28",
"42", "", "21", "18", "14", "40", "27", "", "3", "19", "", "", "", "", ...],
cabin: ["", "C85", "", "C123", "", "", "E46", "", "", "", "G6", "C103", "", "", "", "", "", "",
"", "", "", "D56", "", "A6", "", "", "", "C23 C25 C27", "", "", "", "B78", "", "", "", "", "",
"", "", "", "", "", "", "", "", "", "", "", ...],
embarked: ["S", "C", "S", "S", "S", "Q", "S", "S", "S", "C", "S", "S", "S", "S", "S", "S", "Q",
"S", "S", "C", "S", "S", "Q", "S", "S", "S", "C", "S", "Q", "S", "C", "C", "Q", "S", "C", "S",
"C", "S", "S", "C", "S", "S", "C", "C", "Q", "S", "Q", ...],
...
}
テーブル表示してみましょう
Kino.DataTable.new(train_data)
タイタニック号の乗客毎に以下の項目を持ったデータになっています
- age: 年齢
- cabin: 客室番号
- embarked: 搭乗港(C: シェルブール, Q: クイーンズタウン, S: サウサンプトン)、
- fare: 乗船料金
- name: 氏名
- parch: 一緒に乗っていた親・子どもの数
- passengerid: 乗客ID
- pclass: チケット階級(1: 一等級、2: 二等級、3: 三等級)
- sex: 性別
- sibsp: 一緒に乗っていた兄弟・姉妹・配偶者の数
- survided: 生き残ったか(0: いいえ、1: はい)
- ticket: チケット番号
ID 一覧取得
passengerid が乗客を識別するための ID なので、これを ID 一覧として取得します
id_list = train_data.passengerid
結果は以下の通り
["1", "2", "3", "4", "5", "6", "7", "8", "9", "10", "11", "12", "13", "14", "15", "16", "17", "18",
"19", "20", "21", "22", "23", "24", "25", "26", "27", "28", "29", "30", "31", "32", "33", "34",
"35", "36", "37", "38", "39", "40", "41", "42", "43", "44", "45", "46", "47", "48", "49", "50",
...]
ラベル一覧取得
survived が学習・推論する対象なので、これをラベル一覧として取得します
学習時、 Float 型のテンソルにしたいので Nx.tensor(type: :f32) で変換します
label_tensor =
train_data.survived
|> Enum.map(fn datum ->
datum
|> String.to_integer()
|> Nx.tensor(type: :f32)
|> Nx.new_axis(-1)
|> Nx.new_axis(-1)
end)
結果は以下の通り
[
#Nx.Tensor<
f32[1][1]
[
[0.0]
]
>,
#Nx.Tensor<
f32[1][1]
[
[1.0]
]
>,
...
]
入力データの取得
推論時の入力(予測の元にする)データを取得します
対象は passengerid と survived 以外です(ひとまず)
inputs = Map.drop(train_data, [:passengerid, :survived])
不要な項目の排除
生き残ったかどうかにあまり関係しなさそうな項目を排除します
dropped_inputs = Map.drop(inputs, [:cabin, :name, :ticket])
欠損値処理
テーブルを見ても分かりますが、いくつかの項目が空になっているデータがあります
例えば年齢が空になっているデータの件数を取得してみます
train_data.age
|> Enum.filter(& &1=="")
|> Enum.count()
結果は 177 です
これを全項目について行い、空(欠損値)を持つ項目を洗い出します
count_missings = fn data ->
data
|> Enum.into(%{}, fn {key, list} ->
{
key,
list
|> Enum.filter(& &1=="")
|> Enum.count()
}
end)
|> Enum.filter(fn {_, count} -> count > 0 end)
end
count_missings.(train_data)
結果は以下のようになります
[age: 177, cabin: 687, embarked: 2]
つまり年齢、客室番号、搭乗港には欠損値がある、ということです
これらの項目について、空のとき別の値で埋めます(cabin は既に排除しているので何もしません)
- age: 空のとき「0」
- embarked: 空のとき「S」
filled_inputs =
dropped_inputs
|> Map.put(
:age,
dropped_inputs.age
|> Enum.map(fn
"" -> "0"
others -> others
end)
)
|> Map.put(
:embarked,
dropped_inputs.embarked
|> Enum.map(fn
"" -> "S"
others -> others
end)
)
Kino.DataTable.new(filled_inputs)
数値化
搭乗港や性別は文字列なので、これを数値に変換します
まず、性別を一意の数値に変換するためのマップを用意します
sex_map =
filled_inputs.sex
|> Enum.uniq()
|> Enum.sort()
|> Enum.with_index()
|> Enum.into(%{})
結果はこうなります
%{"female" => 1, "male" => 0}
また、搭乗港の場合も同様にします
embarked_map =
filled_inputs.embarked
|> Enum.uniq()
|> Enum.sort()
|> Enum.with_index()
|> Enum.into(%{})
搭乗港の変換マップは以下の通りになります
%{"C" => 0, "Q" => 1, "S" => 2}
準備した変換マップを使って、各項目を文字列から数値に変換します
categorised_inputs =
filled_inputs
|> Map.put(
:sex,
filled_inputs.sex
|> Enum.map(&sex_map[&1])
)
|> Map.put(
:embarked,
filled_inputs.embarked
|> Enum.map(&embarked_map[&1])
)
その他の項目も数字から数値に変換します
parsed_inputs =
[:age, :fare, :parch, :pclass, :sibsp]
|> Enum.reduce(categorised_inputs, fn column_name, acc ->
acc
|> Map.put(
column_name,
acc
|> Map.get(column_name)
|> Enum.map(fn value ->
value
|> Float.parse()
|> elem(0)
end)
)
end)
Kino.DataTable.new(parsed_inputs)
これで全データの全項目が欠損のない数値になりました
テンソル化
各列の値をテンソルにした後、行単位のデータにするため転置(transpose)してから List に分割します
input_tensor_list =
parsed_inputs
|> Map.values()
|> Nx.tensor()
|> Nx.transpose()
|> Nx.to_batched(1)
|> Enum.to_list()
結果は以下のようになります
[
#Nx.Tensor<
f32[1][7]
[
[22.0, 0.0, 7.25, 0.0, 3.0, 0.0, 1.0]
]
>,
#Nx.Tensor<
f32[1][7]
[
[38.0, 1.0, 71.2833023071289, 0.0, 1.0, 1.0, 1.0]
]
>,
...
]
モジュール化
これまでの一連の操作を繰り返し実行できるようにモジュール化します
テストデータの場合は生き残ったかの正解を持っていないため、ラベルは nil が返るようにしています
defmodule PreProcess do
def load_csv(kino_input) do
[header_org | rows_org] =
kino_input
|> Kino.Input.read()
|> Map.get(:file_ref)
|> Kino.Input.file_path()
|> File.stream!()
|> CSV.decode!()
|> Enum.to_list()
header =
header_org
|> Enum.map(fn column_name ->
column_name
|> String.downcase()
|> String.to_atom()
end)
header
|> Enum.with_index()
|> Enum.into(%{}, fn {key, index} ->
{
key,
Enum.map(rows_org, &Enum.at(&1, index))
}
end)
end
def fill_empty(data, fill_map) do
fill_map
|> Enum.reduce(data, fn {column_name, fill_value}, acc ->
acc
|> Map.put(
column_name,
data
|> Map.get(column_name)
|> Enum.map(fn
"" -> fill_value
others -> others
end)
)
end)
end
def to_number(data, columns_names) do
columns_names
|> Enum.reduce(data, fn column_name, acc ->
conversion_map =
data
|> Map.get(column_name)
|> Enum.uniq()
|> Enum.sort()
|> Enum.with_index()
|> Enum.into(%{})
acc
|> Map.put(
column_name,
data
|> Map.get(column_name)
|> Enum.map(&conversion_map[&1])
)
end)
end
def to_tensor(data, columns_names) do
columns_names
|> Enum.reduce(data, fn column_name, acc ->
acc
|> Map.put(
column_name,
acc
|> Map.get(column_name)
|> Enum.map(fn value ->
value
|> Float.parse()
|> elem(0)
end)
)
end)
|> Map.values()
|> Nx.tensor()
|> Nx.transpose()
|> Nx.to_batched(1)
|> Enum.to_list()
end
def process(kino_input, id_key, label_key) do
data_org = load_csv(kino_input)
id_list = Map.get(data_org, id_key)
label_list =
if Map.has_key?(data_org, label_key) do
data_org
|> Map.get(label_key)
|> Enum.map(fn datum ->
datum
|> String.to_integer()
|> Nx.tensor(type: :f32)
|> Nx.new_axis(-1)
|> Nx.new_axis(-1)
end)
else
nil
end
inputs =
data_org
|> Map.drop([id_key, label_key, :cabin, :name, :ticket])
|> fill_empty(%{age: "0", embarked: "S", fare: "0"})
|> to_number([:sex, :embarked])
|> to_tensor([:age, :fare, :parch, :pclass, :sibsp])
{id_list, label_list, inputs}
end
end
改めて学習データをID、ラベル、入力値に変換します
{
train_id_list,
train_label_list,
train_inputs
} = PreProcess.process(train_data_input, :passengerid, :survived)
また、テスト用データも同様に読み込んでおきます
{
test_id_list,
test_label_list,
test_inputs
} = PreProcess.process(test_data_input, :passengerid, :survived)
モデルの定義
学習、推論するためのモデルを準備します
入力の項目すうが 7 なので、入力層の形を {nil, 7} にしています
model =
Axon.input("input", shape: {nil, 7})
|> Axon.dense(48, activation: :tanh)
|> Axon.dropout(rate: 0.2)
|> Axon.dense(48, activation: :tanh)
|> Axon.dense(1, activation: :sigmoid)
学習
学習データとして入力値とラベルのセットを作ります
train_data = Enum.zip(train_inputs, train_label_list)
進捗状況を見るためのグラフを準備します
loss_plot =
VegaLite.new(width: 300)
|> VegaLite.mark(:line)
|> VegaLite.encode_field(:x, "step", type: :quantitative)
|> VegaLite.encode_field(:y, "loss", type: :quantitative)
|> Kino.VegaLite.new()
acc_plot =
VegaLite.new(width: 300)
|> VegaLite.mark(:line)
|> VegaLite.encode_field(:x, "step", type: :quantitative)
|> VegaLite.encode_field(:y, "accuracy", type: :quantitative)
|> Kino.VegaLite.new()
Kino.Layout.grid([loss_plot, acc_plot], columns: 2)
学習を実行します(エポック数は多めに 50 にします)
trained_state =
model
|> Axon.Loop.trainer(:mean_squared_error, Axon.Optimizers.adam(0.0005))
|> Axon.Loop.metric(:accuracy, "accuracy")
|> Axon.Loop.kino_vega_lite_plot(loss_plot, "loss", event: :epoch_completed)
|> Axon.Loop.kino_vega_lite_plot(acc_plot, "accuracy", event: :epoch_completed)
|> Axon.Loop.run(train_data, %{}, epochs: 50, compiler: EXLA)
学習を実行すると、 loss が下がって accuracy が上がる様子が見えます
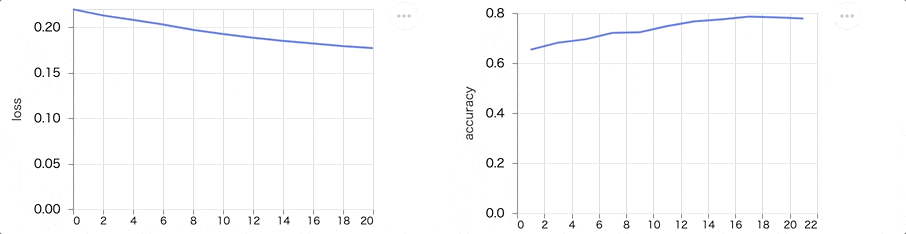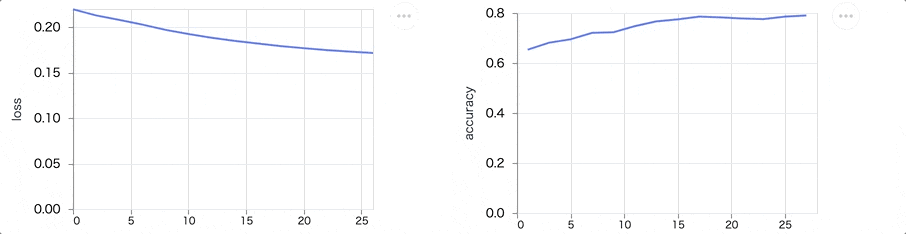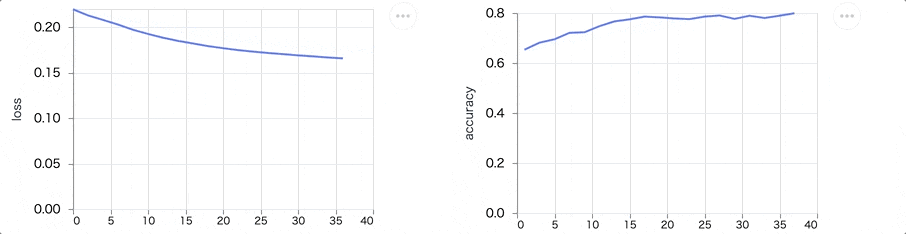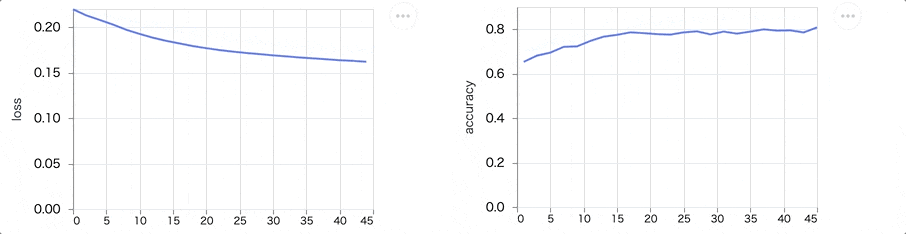
最終的には以下のようなグラフになります
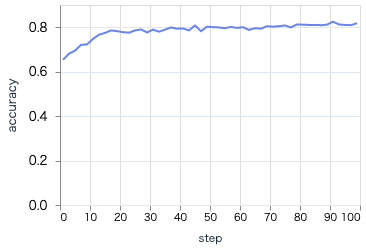
loss も accuracy も傾きが小さくなり、これ以上学習してもあまり改善が見込めないような状態になっているのが分かります
テストデータに対する推論
Axon.predict でテストデータの最初の一件だけ推論してみます
test_inputs
|> List.first()
|> then(&Axon.predict(model, trained_state, &1))
結果は以下のようにテンソルで返ってきます
#Nx.Tensor<
f32[1][1]
EXLA.Backend<host:0, 0.3107249500.3383099400.171576>
[
[0.10238001495599747]
]
>
0.5 より小さいので、この乗客は生き残っていない、と予測したようです
全件に対して実行してみます
results =
test_inputs
|> Nx.concatenate()
|> then(&Axon.predict(model, trained_state, &1))
|> Nx.to_flat_list()
|> Enum.map(&round(&1))
結果は以下のように 0 と 1 の List になります
[0, 0, 0, 0, 1, 0, 0, 0, 1, 0, 0, 0, 1, 0, 1, 1, 0, 0, 0, 0, 0, 0, 1, 1, 1, 0, 1, 0, 0, 0, 0, 0, 0,
1, 0, 0, 1, 1, 0, 0, 0, 0, 0, 1, 1, 0, 0, 0, 1, 1, ...]
推論結果のダウンロード
推論結果を ID と合わせて CSV に変換します
results_csv =
results
|> then(&[test_id_list, &1])
|> Enum.zip()
|> Enum.map(fn {id, label} ->
[id, "#{label}"]
end)
|> then(& [["PassengerId", "Survived"] | &1])
|> CSV.encode()
|> Enum.to_list()
|> Enum.join()
CSV ファイルをダウンロードします
Kino.Download.new(fn -> results_csv end, filename: "result.csv")
推論結果の Kaggle へのアップロード
Kaggle のタイタニックデータのページから「Submit Predictions」のボタンをクリックし、推論結果の CSV ファイルをアップロードします
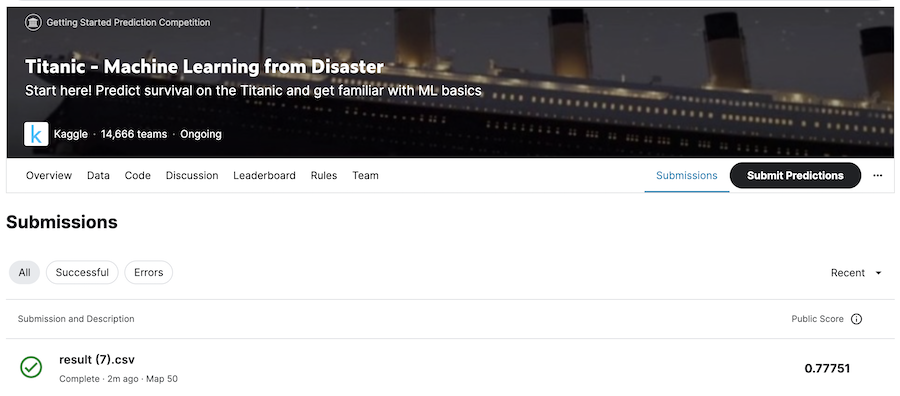
一覧にアップロードしたファイルが追加され、右端に正解率が表示されます
「Leaderboard」タブをクリックすると、順位表が表示されます
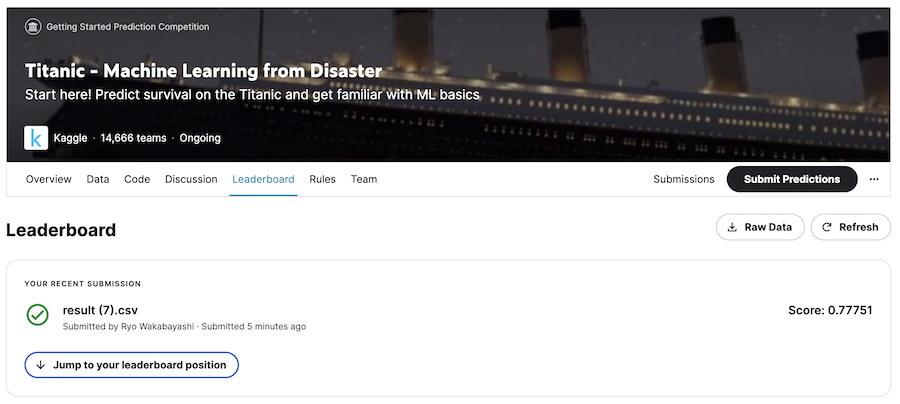
正解率は 77.751 % でした
「Jump to your leaderboard position」で自分の順位が確認できます

今回の順位は 3,969 位でした
Explorer を使った場合
ここまでの操作をより簡単にするため、 Explorer を使ってみます
実装したノートブックはこちら
Explorer を使う場合のセットアップ
セットアップ時に CSV ではなく Explorer をインストールします
Mix.install([
{:exla, "~> 0.5"},
{:axon, "~> 0.5"},
{:kino, "~> 0.9"},
{:kino_vega_lite, "~> 0.1"},
{:explorer, "~> 0.5"}
])
エイリアス等を準備します
alias Explorer.DataFrame
alias Explorer.Series
require Explorer.DataFrame
学習データ、テストデータのアップロードは同じです
train_data_input = Kino.Input.file("train data")
test_data_input = Kino.Input.file("test data")
Explorer による CSV 読込
Explorer では、 DataFrame.from_csv だけで簡単に CSV が読み込めます
train_data =
train_data_input
|> Kino.Input.read()
|> Map.get(:file_ref)
|> Kino.Input.file_path()
|> DataFrame.from_csv!()
Kino.DataTable.new(train_data)
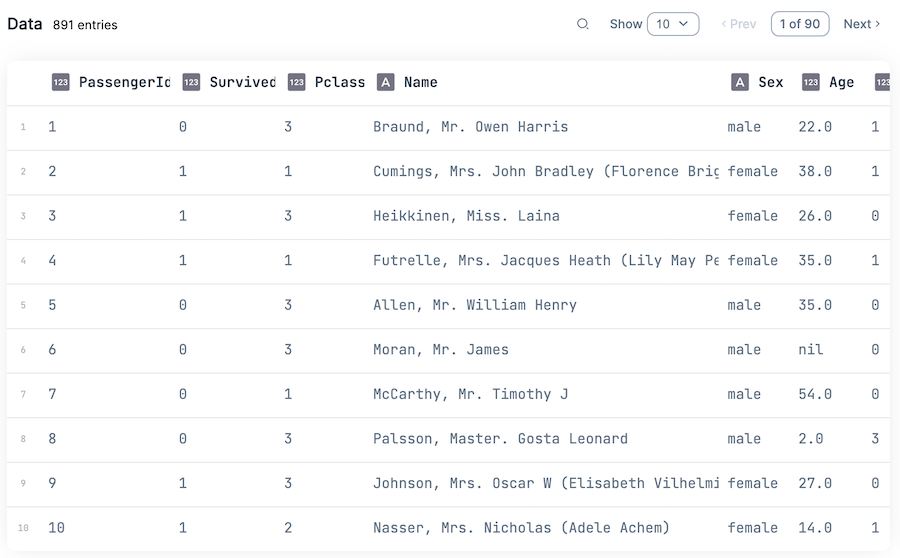
Explorer による項目抽出
ID 一覧の取得はかなり単純です
id_list = Series.to_list(train_data["PassengerId"])
結果は以下のようになります
[1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27,
28, 29, 30, 31, 32, 33, 34, 35, 36, 37, 38, 39, 40, 41, 42, 43, 44, 45, 46, 47, 48, 49, 50, ...]
ラベルはテンソルの配列にするため少し長くなります
label_tensor =
train_data["Survived"]
|> Series.to_tensor(backend: EXLA.Backend)
|> Nx.as_type(:f32)
|> Nx.new_axis(1)
|> Nx.to_batched(1)
|> Enum.to_list()
DataFrame.discard で不要な列を排除します
inputs = DataFrame.discard(train_data, ["PassengerId", "Survived"])
Kino.DataTable.new(inputs)
dropped_inputs = DataFrame.discard(inputs, ["Cabin", "Name", "Ticket"])
Kino.DataTable.new(dropped_inputs)
Explorer による欠損値補完
Series.fill_missing を使って欠損値を補完します
年齢について 0 歳で補完していたのは乱暴だったので、平均値で補完するようにしています
filled_inputs =
dropped_inputs
|> DataFrame.put("Age", Series.fill_missing(train_data["Age"], :mean))
|> DataFrame.put("Embarked", Series.fill_missing(train_data["Embarked"], "S"))
Kino.DataTable.new(filled_inputs)
Explorer によるワンホットエンコーディング
性別と搭乗港について、 DataFrame.dummies でワンホット(One-Hot)エンコーディングします
dummied_inputs =
filled_inputs
|> DataFrame.dummies(["Sex", "Embarked"])
|> DataFrame.concat_columns(DataFrame.discard(filled_inputs, ["Sex", "Embarked"]))
Kino.DataTable.new(dummied_inputs)
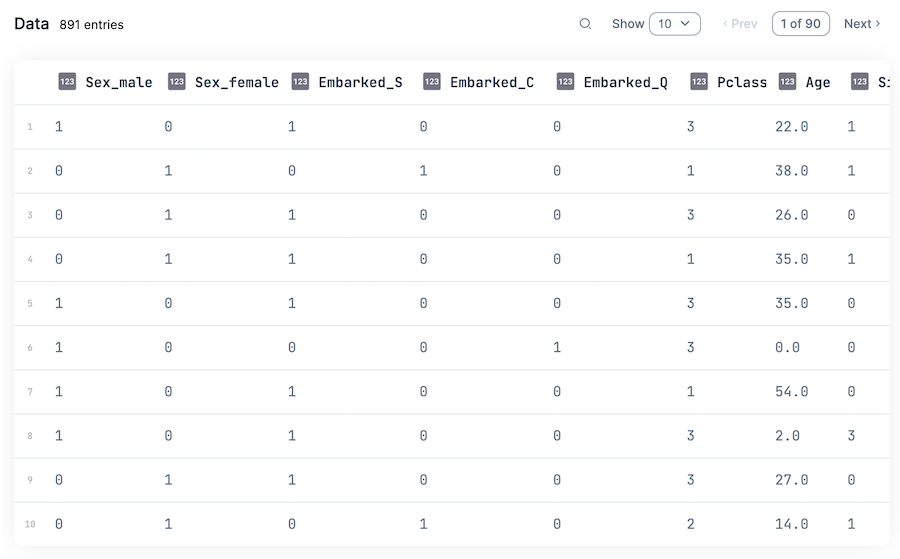
ワンホットエンコーディングにより、列が値の種類の分だけ増殖しています
- Sex
- Sex-male
- Sex-female
- Embarked
- Embarked_C
- Embarked_Q
- Embarked_S
それぞれ、各値に該当する場合は 1 、そうでない場合は 0 になります
性別、搭乗港については値の大小に意味がない(意味を持たせるべきではない)ため、値毎に別の項目として扱うためです
データフレームからのテンソル化
最後にテンソル化します
input_tensor_list =
dummied_inputs
|> DataFrame.to_columns()
|> Map.values()
|> Nx.tensor(backend: EXLA.Backend)
|> Nx.transpose()
|> Nx.to_batched(1)
|> Enum.to_list()
Explorer による前処理のモジュール化
ここまでの一連の処理をモジュール化します
def load_csv(kino_input) do
kino_input
|> Kino.Input.read()
|> Map.get(:file_ref)
|> Kino.Input.file_path()
|> DataFrame.from_csv!()
end
def fill_empty(data, fill_map) do
fill_map
|> Enum.reduce(data, fn {column_name, fill_value}, acc ->
DataFrame.put(
acc,
column_name,
Series.fill_missing(data[column_name], fill_value)
)
end)
end
def replace_dummy(data, columns_names) do
data
|> DataFrame.dummies(columns_names)
|> DataFrame.concat_columns(DataFrame.discard(data, columns_names))
end
def to_tensor(data) do
data
|> DataFrame.to_columns()
|> Map.values()
|> Nx.tensor(backend: EXLA.Backend)
|> Nx.transpose()
|> Nx.to_batched(1)
|> Enum.to_list()
end
def process(kino_input, id_key, label_key) do
data_org = load_csv(kino_input)
id_list = Series.to_list(data_org[id_key])
has_label_key =
data_org
|> DataFrame.names()
|> Enum.member?(label_key)
label_list =
if has_label_key do
data_org[label_key]
|> Series.to_tensor(backend: EXLA.Backend)
|> Nx.as_type(:f32)
|> Nx.new_axis(1)
|> Nx.to_batched(1)
|> Enum.to_list()
else
nil
end
inputs =
if has_label_key do
DataFrame.discard(data_org, [id_key, label_key])
else
DataFrame.discard(data_org, [id_key])
end
|> DataFrame.discard(["Cabin", "Name", "Ticket"])
|> fill_empty(%{"Age" => :mean, "Embarked" => "S", "Fare" => :mean})
|> replace_dummy(["Sex", "Embarked"])
|> to_tensor()
{id_list, label_list, inputs}
end
end
改めて学習データをID、ラベル、入力値に変換します
{
train_id_list,
train_label_list,
train_inputs
} = PreProcess.process(train_data_input, "PassengerId", "Survived")
また、テスト用データも同様に読み込んでおきます
{
test_id_list,
test_label_list,
test_inputs
} = PreProcess.process(test_data_input, "PassengerId", "Survived")
Explorer を使った場合の学習
モデルを定義します
ワンホットエンコーディングにより列が増えたため、入力層の形が {nil, 10} になります
model =
Axon.input("input", shape: {nil, 10})
|> Axon.dense(48, activation: :tanh)
|> Axon.dropout(rate: 0.2)
|> Axon.dense(48, activation: :tanh)
|> Axon.dense(1, activation: :sigmoid)
学習データとして入力値とラベルのセットを作ります
train_data = Enum.zip(train_inputs, train_label_list)
進捗状況を見るためのグラフを準備します
loss_plot =
VegaLite.new(width: 300)
|> VegaLite.mark(:line)
|> VegaLite.encode_field(:x, "step", type: :quantitative)
|> VegaLite.encode_field(:y, "loss", type: :quantitative)
|> Kino.VegaLite.new()
acc_plot =
VegaLite.new(width: 300)
|> VegaLite.mark(:line)
|> VegaLite.encode_field(:x, "step", type: :quantitative)
|> VegaLite.encode_field(:y, "accuracy", type: :quantitative)
|> Kino.VegaLite.new()
Kino.Layout.grid([loss_plot, acc_plot], columns: 2)
学習を実行します(Explorer を使わない場合と同じです)
trained_state =
model
|> Axon.Loop.trainer(:mean_squared_error, Axon.Optimizers.adam(0.0005))
|> Axon.Loop.metric(:accuracy, "accuracy")
|> Axon.Loop.kino_vega_lite_plot(loss_plot, "loss", event: :epoch_completed)
|> Axon.Loop.kino_vega_lite_plot(acc_plot, "accuracy", event: :epoch_completed)
|> Axon.Loop.run(train_data, %{}, epochs: 50, compiler: EXLA)
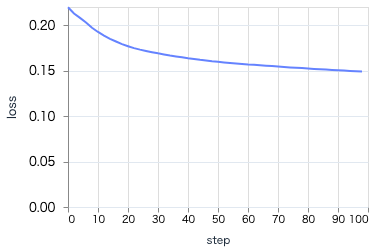
学習時の推移は以下のようになります
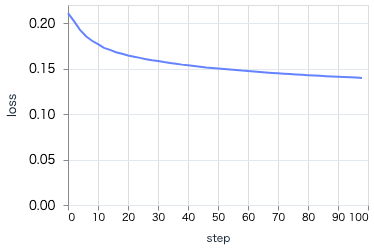
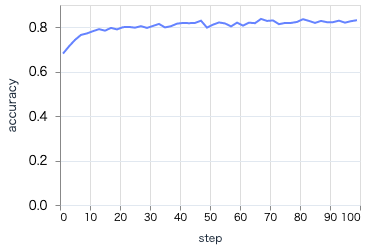
ワンホットエンコードや欠損値の平均による補完のため、 loss が低く、 accuracy が高くなっています
Explorer を使った場合の推論
推論結果をデータフレームに格納してテーブル表示します
results =
test_inputs
|> Nx.concatenate()
|> then(&Axon.predict(model, trained_state, &1))
|> Nx.to_flat_list()
|> Enum.map(&round(&1))
|> then(&%{
"PassengerId" => test_id_list,
"Survived" => &1
})
|> DataFrame.new()
Kino.DataTable.new(results)
Explorer による推論結果の CSV 出力
データフレームを CSV 形式で出力し、ダウンロードします
results
|> DataFrame.dump_csv!()
|> then(&Kino.Download.new(fn -> &1 end, filename: "result.csv"))
Explorer を使った場合の正解率
Explorer を使った場合の正解率は 77.511 でした
残念ながら、Explorer を使わない場合より少し低くなっていますが、この差はテストデータ 1 件分なので、ほとんど誤差と言えるでしょう
まとめ
Kaggle のタイタニックデータを使って、それなりの精度のモデルが構築できました
Explorer を使ったからと言って精度に改善は見られませんでしたが、コードの可読性は著しく上がったと思います
次回、更にデータ分析によって前処理を改善しました