はじめに
以前、 Livebook で FolkorDB を使った GraphRAG を実装しました
この記事では Neo4j を使い、ベクトル検索、全文検索、グラフ検索を組み合わせたハイブリッド RAG を実装します
実装にあたっては Python の LangChain を参考にしました
実装したノートブックはこちら
事前準備
環境構築
以下のような内容で docker-compose.with-neo4j.yml を作成します
services:
livebook_with_neo4j:
image: ghcr.io/livebook-dev/livebook:0.14.5
container_name: livebook_with_neo4j
ports:
- '8080:8080'
- '8081:8081'
neo4j-for-livebook:
image: neo4j:community
container_name: neo4j-for-livebook
tty: true
ports:
- 7474:7474
- 7687:7687
volumes:
- ./neo4j/data:/data
- ./neo4j/logs:/logs
- ./neo4j/conf:/conf
- ./certs:/var/lib/neo4j/certificates/bolt
environment:
- NEO4J_AUTH=none
user: '1000'
group_add:
- '1000'
neo4j-for-livebook というように Neo4j 側のサービス名はハイフン区切り(ケバブケース)にしています
_ を使っていると、接続時にエラーが発生するためです
以下のコマンドを実行すると、 Livebook と Neo4j がそれぞれコンテナで起動します
docker compose --file docker-compose.with-neo4j.yml up
Livebook にはコンテナ起動時に表示される URL (トークン付き)でアクセスします
右上の "+ New notebook" から新しいノートブックを開きます
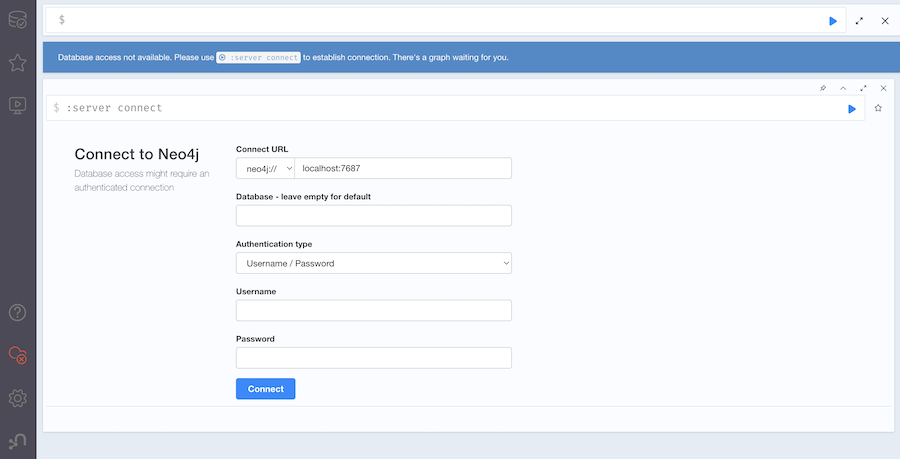
Neo4j Browser(Neo4j の操作用コンソール)には http://localhost:7474/ でアクセスします
認証なしの設定で起動しているため、 "Authentication type" に "No authentication" を選択して "Connect" をクリックしてください
接続できると、 Neo4j の操作用コンソールが表示されます
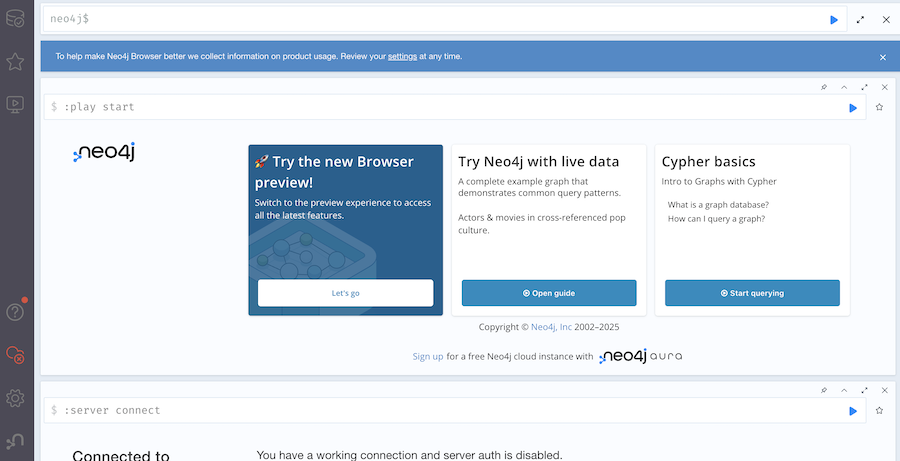
"Try the new Browser preview!" カードの "Let's go" ボタンをクリックすると、新しい UI に切り替わり、改めて接続を求められます
"Connection URL" に "localhost:7687" を入力し、 "Password" は空欄のまま "Connect" をクリックしてください
新しい UI のコンソールが表示されます
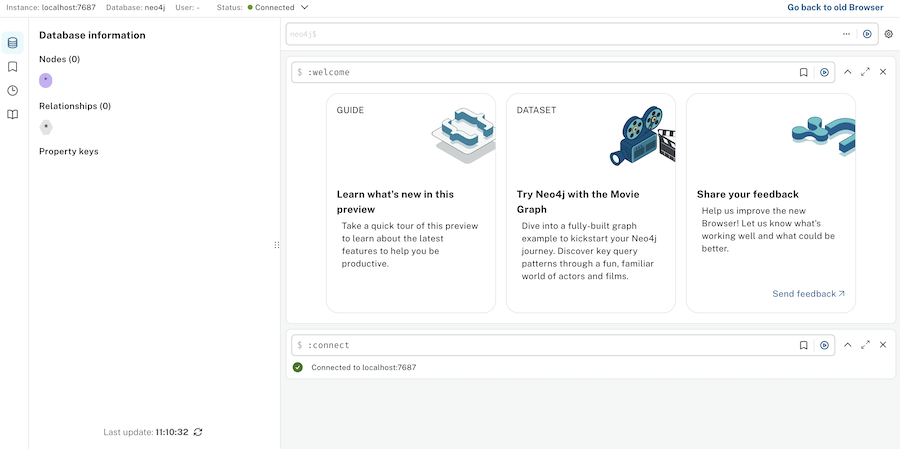
以降、コンテナ起動後の接続時には新しい UI の画面が表示されるようになります
OpenAI APIキーの作成
OpenAI API の API キーを使用するため、あらかじめアカウント、APIキーを作成しておきます
公式サイトにアクセスし、サインアップしてください
OpenAI 社が提供する ChatGPT とは別契約になります
すでに ChatGPT のアカウントを保有をしていたとしても、別途 OpenAI API のサインアップが必要です
初回アカウント作成時は無償トライアルを受けることが可能ですが、基本的に前払いでクレジットを購入しておき、 API 利用のたびに消費していく契約になります
左メニュー API keys を開き、右上 "+ Create new secret key" をクリックします
モーダルが開くので、適当な名前を入力して "Create secret key" をクリックします
API キーが作成されるので、安全な場所に保管しておいてください
検索先ドキュメントの準備
今回は検索先ドキュメントとして桃太郎、金太郎、浦島太郎を使用します
青空文庫から桃太郎、金太郎、浦島太郎のテキストを取得し、平文テキストとして GitHub にアップロードしておきます
今回は楠山正雄さんの書いた桃太郎、金太郎、浦島太郎(著作権切れ)を使用します
- 桃太郎: https://www.aozora.gr.jp/cards/000329/files/18376_12100.html
- 金太郎: https://www.aozora.gr.jp/cards/000329/files/18337_11942.html
- 浦島太郎: https://www.aozora.gr.jp/cards/000329/files/3390_33153.html
青空文庫の収録ファイル取り扱い基準についてはこちら
ルビは邪魔なので削除します
ルビを削除した文書をテキストファイルとして保存し、 GitHub リポジトリーにコミット、プッシュします
準備したものがこちらです(本記事ではこれらを使います)
- 桃太郎: https://raw.githubusercontent.com/RyoWakabayashi/elixir-learning/main/livebooks/bumblebee/colab/momotaro.txt
- 金太郎: https://github.com/RyoWakabayashi/elixir-learning/blob/main/livebooks/bumblebee/colab/kintaro.txt
- 浦島太郎: https://github.com/RyoWakabayashi/elixir-learning/blob/main/livebooks/bumblebee/colab/urashimataro.txt
セットアップ
Livebook のセットアップセルに以下のコードを入力し、必要なモジュールをインストールします
Mix.install([
{:openai_ex, "~> 0.8.6"},
{:boltx, "~> 0.0.6"},
{:kino, "~> 0.14"},
{:req, "~> 0.5"}
])
alias OpenaiEx.Chat
alias OpenaiEx.ChatMessage
alias OpenaiEx.Embeddings
Secrets の設定
Livebook の左メニュー錠前アイコンをクリックすると、 "SECRETS" メニューが開きます
"+ New secret" をクリックすると、新しい secret = 秘密情報を保持することができます
Secrets の設定モーダルが開きます
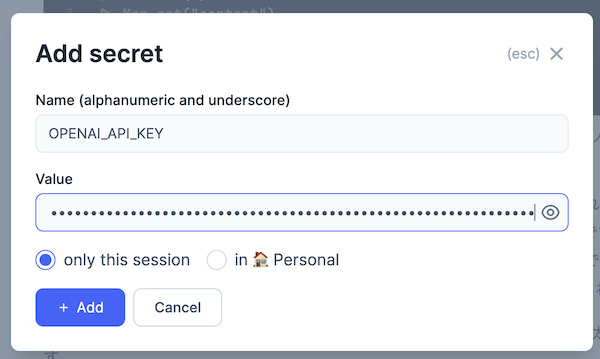
以下の内容を入力し、 "+ Add" をクリックしてください
Name: OPENAI_API_KEY
Value: OpenAI の API キー
OpenAI クライアントの準備
OpenAI のクライアントを用意します
openai =
"LB_OPENAI_API_KEY"
|> System.fetch_env!()
|> OpenaiEx.new()
|> OpenaiEx.with_receive_timeout(60_000)
Kino.nothing()
ドキュメントのグラフデータベースへの格納
ドキュメントの読込
各ドキュメントの URL を定義します
urls = [
"https://raw.githubusercontent.com/RyoWakabayashi/elixir-learning/main/livebooks/bumblebee/colab/momotaro.txt",
"https://raw.githubusercontent.com/RyoWakabayashi/elixir-learning/main/livebooks/bumblebee/colab/kintaro.txt",
"https://raw.githubusercontent.com/RyoWakabayashi/elixir-learning/main/livebooks/bumblebee/colab/urashimataro.txt"
]
ベクトル検索を行うため、文章をベクトル化(埋め込み)するための関数を用意します
関数内では OpenAI API の text-embedding-3-small モデルを呼び出しています
get_feature = fn chunk ->
openai
|> Embeddings.create!(
Embeddings.new(model: "text-embedding-3-small", input: chunk)
)
|> Map.get("data")
|> hd()
|> Map.get("embedding")
end
とりあえず先頭のドキュメント、先頭の章で実行してみます
%{body: text} =
urls
|> hd()
|> Req.get!()
text
|> String.split("\n\n")
|> hd()
|> get_feature.()
実行結果
[0.074187525, -0.020565134, -0.06818059, -0.0052895434, 0.035525072, -0.03917897, 0.0167008,
0.02791119, -0.022573821, -0.016614715, 0.031526826, -0.02517555, -0.046333723, -0.027605105,
0.0055095428, -0.007264753, -0.0064660604, -0.0057438896, 0.0033143342, 0.002057709, 0.021234695,
-0.004490851, 0.0430433, 0.0043951995, 0.01341038, 0.0136973355, 0.019608615, 0.0065473644,
0.042239826, -0.06439278, -0.021942519, -0.023396427, -0.04461199, -0.018240795, -0.004170418,
0.008259531, -0.003962375, -0.04721372, 0.0041369395, -0.019206878, 0.028810317, -0.020278178,
0.026667716, 0.0018006448, 0.031220742, -0.0040221573, -2.2672462e-4, 0.0024104249, 0.0018532532,
0.02414251, ...]
テキストが数値の配列(ベクトル)に変換されました
今後使用する生成 AI モデルとして GPT-4o のモデル ID を定義しておきます
model_id = "gpt-4o"
ドキュメントをグラフデータベースに登録するための関数を用意します
parse_document = fn document, openai, model_id, entities, relations ->
system_message =
"""
You are a top-tier algorithm designed for extracting information in structured formats to build a knowledge graph. Your task is to identify the entities and relations requested with the user prompt from a given text. You must generate the output in a JSON format containing a list with JSON objects. Each object should have the keys: "head", "head_type", "relation", "tail", and "tail_type". The "head" key must contain the text of the extracted entity with one of the types from the provided list in the user prompt.
Attempt to extract as many entities and relations as you can. Maintain Entity Consistency: When extracting entities, it's vital to ensure consistency. If an entity, such as "John Doe", is mentioned multiple times in the text but is referred to by different names or pronouns (e.g., "Joe", "he"), always use the most complete identifier for that entity. The knowledge graph should be coherent and easily understandable, so maintaining consistency in entity references is crucial.
IMPORTANT NOTES:
- Don't add any explanation and text.
- Ensure that both "head_type" and "tail_type" are always in English.
"""
system_message =
if Enum.empty?(entities) do
system_message
else
system_message <>
"""
Unify the “head” or “tail” values of similar entities to match the values of the existing entities.
Existing entities: #{Enum.join(entities, ",")}
"""
end
system_message =
if Enum.empty?(relations) do
system_message
else
system_message <>
"""
Unify the “relation” values of similar relations to match the values of the existing relations.
Existing relations: #{Enum.join(relations, ",")}
"""
end
user_message =
"""
Based on the following example, extract entities and relations from the provided text.
Below are a number of examples of text and their extracted entities and relationships.
[
{'text': 'Adam is a software engineer in Microsoft since 2009, and last year he got an award as the Best Talent', 'head': 'Adam', 'head_type': 'Person', 'relation': 'WORKS_FOR', 'tail': 'Microsoft', 'tail_type': 'Company'},
{'text': 'Adam is a software engineer in Microsoft since 2009, and last year he got an award as the Best Talent', 'head': 'Adam', 'head_type': 'Person', 'relation': 'HAS_AWARD', 'tail': 'Best Talent', 'tail_type': 'Award'},
{'text': 'Microsoft is a tech company that provide several products such as Microsoft Word', 'head': 'Microsoft Word', 'head_type': 'Product', 'relation': 'PRODUCED_BY', 'tail': 'Microsoft', 'tail_type': 'Company'},
{'text': 'Microsoft Word is a lightweight app that accessible offline', 'head': 'Microsoft Word', 'head_type': 'Product', 'relation': 'HAS_CHARACTERISTIC', 'tail': 'lightweight app', 'tail_type': 'Characteristic'},
{'text': 'Microsoft Word is a lightweight app that accessible offline', 'head': 'Microsoft Word', 'head_type': 'Product', 'relation': 'HAS_CHARACTERISTIC', 'tail': 'accessible offline', 'tail_type': 'Characteristic'}
]
For the following text, extract entities and relations as in the provided example.The output should be formatted as a JSON instance that conforms to the JSON schema below.
As an example, for the schema {"properties": {"foo": {"title": "Foo", "description": "a list of strings", "type": "array", "items": {"type": "string"}}}, "required": ["foo"]}
the object {"foo": ["bar", "baz"]} is a well-formatted instance of the schema. The object {"properties": {"foo": ["bar", "baz"]}} is not well-formatted.
Here is the output schema:
```
{
"properties": {
"head": {"description": "extracted head entity like Microsoft, Apple, John. Must use human-readable unique identifier.", "title": "Head", "type": "string"},
"head_type": {"description": "type of the extracted head entity like Person, Company, etc", "title": "Head Type", "type": "string"},
"relation": {"description": "relation between the head and the tail entities", "title": "Relation", "type": "string"},
"tail": {"description": "extracted tail entity like Microsoft, Apple, John. Must use human-readable unique identifier.", "title": "Tail", "type": "string"},
"tail_type": {"description": "type of the extracted tail entity like Person, Company, etc", "title": "Tail Type", "type": "string"}
},
"required": ["head", "head_type", "relation", "tail", "tail_type"]
}
```
Text: '#{document}'
"""
openai
|> Chat.Completions.create!(%{
model: model_id,
messages: [
ChatMessage.system(system_message),
ChatMessage.user(user_message)
]
})
|> Map.get("choices")
|> Enum.at(0)
|> Map.get("message")
|> Map.get("content")
|> String.replace("```json", "")
|> String.replace("```", "")
|> Jason.decode!()
end
以下のようなことを実行しています
-
生成 AI モデルにより、ドキュメントからエンティティとリレーションを抜き出し、以下の形式で出力する
{ "head": "おじいさん", "head_type": "Person", "relation": "LIVES_WITH", "tail": "おばあさん", "tail_type": "Person" } -
"head_type" と "tail_type" は必ず英語にする(Neo4j の label には日本語が指定可能ですが、表記統一のため必ず英語にしています)
-
複数文書を跨いだ表記揺れを補正するため、以下の指定をしています
-
entities(既存のエンティティ)が空でない場合、類似した単語を統一する -
relations(既存の関係)が空でない場合、類似した単語を統一する
-
プロンプトの内容は LangChain の GraphRAG 用プロンプトを元にしています
システム用プロンプトの和訳
あなたは、知識グラフを構築するために情報を構造化形式で抽出するトップクラスのアルゴリズムです。ユーザーの指示に基づき、指定されたテキストからエンティティと関係を特定し、抽出することが任務です。出力はJSON形式で、リスト内にJSONオブジェクトを含む形で生成してください。各オブジェクトは、以下のキーを持つ必要があります:「head」、「head_type」、「relation」、「tail」、「tail_type」。
「head」キーには、ユーザーの指示に含まれるリスト内の種類の1つに該当する、抽出されたエンティティのテキストを含めてください。
できる限り多くのエンティティと関係を抽出することを目指してください。エンティティの一貫性を維持すること:
エンティティを抽出する際には、一貫性を保つことが重要です。たとえば、「John Doe」というエンティティがテキスト内で複数回登場し、異なる名前や代名詞(例: 「Joe」や「he」)で参照される場合、常にそのエンティティを最も完全な識別名で表記してください。知識グラフは一貫性があり、理解しやすいものにする必要があるため、エンティティ参照の一貫性を維持することが重要です。注意事項:
• 説明や追加のテキストを加えないでください。
• 「head_type」と「tail_type」は必ず英語で記述してください。
システム用プロンプトの追加部分(entities 指定時)の和訳
類似するエンティティの「head」または「tail」の値を、既存のエンティティの値と一致させて統一してください。
システム用プロンプトの追加部分(relations 指定時)の和訳
類似するエンティティの「relation」の値を、既存の関係の値と一致させて統一してください。
ユーザー用プロンプトの和訳
以下の例に基づき、提供されたテキストからエンティティと関係を抽出してください。
以下は、テキストとそれから抽出されたエンティティおよび関係の例です。[ { "text": "Adam is a software engineer in Microsoft since 2009, and last year he got an award as the Best Talent", "head": "Adam", "head_type": "Person", "relation": "WORKS_FOR", "tail": "Microsoft", "tail_type": "Company" }, { "text": "Adam is a software engineer in Microsoft since 2009, and last year he got an award as the Best Talent", "head": "Adam", "head_type": "Person", "relation": "HAS_AWARD", "tail": "Best Talent", "tail_type": "Award" }, { "text": "Microsoft is a tech company that provide several products such as Microsoft Word", "head": "Microsoft Word", "head_type": "Product", "relation": "PRODUCED_BY", "tail": "Microsoft", "tail_type": "Company" }, { "text": "Microsoft Word is a lightweight app that accessible offline", "head": "Microsoft Word", "head_type": "Product", "relation": "HAS_CHARACTERISTIC", "tail": "lightweight app", "tail_type": "Characteristic" }, { "text": "Microsoft Word is a lightweight app that accessible offline", "head": "Microsoft Word", "head_type": "Product", "relation": "HAS_CHARACTERISTIC", "tail": "accessible offline", "tail_type": "Characteristic" } ]次のテキストについても、上記の例に従ってエンティティと関係を抽出してください。出力は以下のJSONスキーマに準拠した形式で整形する必要があります。
以下のスキーマ例を参考にしてください:
例えば、スキーマ{ "properties": { "foo": { "title": "Foo", "description": "a list of strings", "type": "array", "items": {"type": "string"} } }, "required": ["foo"] }の場合、オブジェクト
{"foo": ["bar", "baz"]}はスキーマに準拠したフォーマットですが、
{"properties": {"foo": ["bar", "baz"]}}はスキーマに準拠していません。
以下が出力スキーマです:
{ "properties": { "head": { "description": "extracted head entity like Microsoft, Apple, John. Must use human-readable unique identifier.", "title": "Head", "type": "string" }, "head_type": { "description": "type of the extracted head entity like Person, Company, etc", "title": "Head Type", "type": "string" }, "relation": { "description": "relation between the head and the tail entities", "title": "Relation", "type": "string" }, "tail": { "description": "extracted tail entity like Microsoft, Apple, John. Must use human-readable unique identifier.", "title": "Tail", "type": "string" }, "tail_type": { "description": "type of the extracted tail entity like Person, Company, etc", "title": "Tail Type", "type": "string" } }, "required": ["head", "head_type", "relation", "tail", "tail_type"] }
ドキュメントを chunks として分割したとき、全ての chunk についてエンティティと関係を取得する関数を用意します
get_schema = fn chunks, openai, model_id, schema, entities, relations ->
chunks
|> Enum.reduce({schema, entities, relations}, fn chunk, {acc_schema, acc_entities, acc_relations} ->
IO.inspect(chunk)
schema = parse_document.(chunk, openai, model_id, acc_entities, acc_relations)
IO.inspect(schema)
schema =
[schema, acc_schema]
|> Enum.concat()
|> Enum.uniq()
entities =
[
Enum.map(schema, &Map.get(&1, "head")),
Enum.map(schema, &Map.get(&1, "tail")),
acc_entities
]
|> Enum.concat()
|> Enum.uniq()
relations =
[
Enum.map(schema, &Map.get(&1, "relation")),
acc_relations
]
|> Enum.concat()
|> Enum.uniq()
{schema, entities, relations}
end)
end
単純な例を実行してみます
get_schema.(
["太郎はりんごを買いました。", "二郎はみかんをかいました。"],
openai,
model_id,
[
%{
"head" => "三郎",
"head_type" => "Person",
"relation" => "BUY",
"tail" => "林檎",
"tail_type" => "Fruit"
},
%{
"head" => "三郎",
"head_type" => "Person",
"relation" => "BUY",
"tail" => "みかん",
"tail_type" => "Fruit"
}
],
["三郎", "林檎", "みかん"],
["BUY"]
)
実行結果
{[
%{
"head" => "二郎",
"head_type" => "Person",
"relation" => "BUY",
"tail" => "みかん",
"tail_type" => "Product"
},
%{
"head" => "太郎",
"head_type" => "Person",
"relation" => "BUY",
"tail" => "林檎",
"tail_type" => "Product"
},
%{
"head" => "三郎",
"head_type" => "Person",
"relation" => "BUY",
"tail" => "林檎",
"tail_type" => "Fruit"
},
%{
"head" => "三郎",
"head_type" => "Person",
"relation" => "BUY",
"tail" => "みかん",
"tail_type" => "Fruit"
}
], ["二郎", "太郎", "三郎", "みかん", "林檎"], ["BUY"]}
すでに取得済のエンティティとして「林檎」を定義していたため、文章中は「りんご」とひらがな表記であったとしても、「林檎」に統一してくれました
各ドキュメントをダウンロードし、グラフデータベースに登録するためのデータを作成します
各ドキュメントには embedding として、ドキュメントをベクトルに変換した値を設定します
documents = []
schema = []
entities = []
relations = []
{documents, schema, _, _} =
urls
|> Enum.reduce({documents, schema, entities, relations}, fn url,
{acc_documents, acc_schema,
acc_entities, acc_relations} ->
IO.inspect(url)
%{body: text} = Req.get!(url)
chunks = text |> String.trim() |> String.split("\n\n")
documents =
chunks
|> Enum.map(fn chunk ->
%{
id: :crypto.hash(:md5, chunk) |> Base.encode16(case: :lower),
source: url,
text: chunk,
embedding: get_feature.(chunk)
}
end)
{schema, entities, relations} =
get_schema.(chunks, openai, model_id, acc_schema, acc_entities, acc_relations)
{
acc_documents ++ documents,
Enum.uniq(acc_schema ++ schema),
Enum.uniq(acc_entities ++ entities),
Enum.uniq(acc_relations ++ relations)
}
end)
実行結果
{[
%{
id: "d4cad59da6295ecb6949d2943c6b2d90",
text: "むかし、むかし、あるところに、おじいさんとおばあさんがありました。...",
source: "https://raw.githubusercontent.com/RyoWakabayashi/elixir-learning/main/livebooks/bumblebee/colab/momotaro.txt",
embedding: [0.071712725, -0.020324897, -0.06771191, ...]
},
%{
id: "ebe9ae605f4353dc2d5454d95480a98c",
text: " おじいさんとおばあさんは、それはそれはだいじにして桃太郎を育てました。...",
source: "https://raw.githubusercontent.com/RyoWakabayashi/elixir-learning/main/livebooks/bumblebee/colab/momotaro.txt",
embedding: [0.060600497, -0.006748354, -0.05068, ...]
},
%{
id: "ce05969edddeea493d6cbe0a12f24b0e",
text: " 桃太郎はずんずん行きますと、大きな山の上に来ました。...",
source: "https://raw.githubusercontent.com/RyoWakabayashi/elixir-learning/main/livebooks/bumblebee/colab/momotaro.txt",
embedding: [0.031183358, -0.017077051, -0.029669601, ...]
},
...
],
[
%{
"head" => "桃太郎",
"head_type" => "Person",
"relation" => "JOINS",
"tail" => "犬",
"tail_type" => "Animal"
},
%{
"head" => "桃太郎",
"head_type" => "Person",
"relation" => "JOINS",
"tail" => "猿",
"tail_type" => "Animal"
},
%{
"head" => "桃太郎",
"head_type" => "Person",
"relation" => "JOINS",
"tail" => "きじ",
"tail_type" => "Animal"
},
...
],
["桃太郎", "おじいさん", "犬", "猿", "きじ", "桃", "鬼が島", "おばあさん",
"お城", "金太郎", "きこり", "碓井貞光", "森", "おかあさん", "うさぎ", "熊",
"鹿", "都", "坂田金時", "頼光", "おむすび", "浦島太郎", "乙姫さま",
"りゅう宮", "玉手箱", "かめ", "海", "おとうさん", "大広間"],
["JOINS", "GOES_TO", "LIVES_WITH", "NAMED_AFTER", "HAS_CHILD", "CONTAINS", "GIVES_TO", "FINDS",
"MEETS", "GIVEN_BY", "THANKS", "GIVEN_TO", "GUIDED_BY", "SHOWS"]}
桃太郎 JOIN 犬や 桃太郎 JOINS 猿など、ドキュメントの内容に沿った関係が抽出されています
Boltx を使用して Neo4j に接続します
opts = [
hostname: "neo4j-for-livebook",
scheme: "bolt",
auth: [username: "neo4j", password: ""],
user_agent: "boltxTest/1",
pool_size: 15,
max_overflow: 3,
prefix: :default
]
{:ok, conn} = Boltx.start_link(opts)
ノードを作成します
エンティティ(ドキュメント内に登場する人や物)とドキュメントのノードを両方作成するため、エンティティのノードには "Entity" ラベルを付けておきます
"head_type" や "tail_type" をラベルにしていますが、例えば "Big Person" のように空白が入っていると構文エラーになるため、空白を取り除いています
これにより、"Big Person" は "BigPerson" ラベルで登録されることになります
nodes =
[
Enum.map(schema, fn node ->
%{
label: ["__Entity__", Map.get(node, "head_type") |> String.replace(" ", "")],
id: Map.get(node, "head")
}
end),
Enum.map(schema, fn node ->
%{
label: ["__Entity__", Map.get(node, "tail_type") |> String.replace(" ", "")],
id: Map.get(node, "tail")
}
end)
]
|> Enum.concat()
|> Enum.uniq()
|> Enum.reduce(%{}, fn node, acc_nodes ->
case Map.get(acc_nodes, node.id) do
nil ->
Map.put(acc_nodes, node.id, node)
existing_node ->
merged_node =
Map.put(existing_node, :label, existing_node.label ++ node.label)
Map.put(acc_nodes, node.id, merged_node)
end
end)
実行結果
%{
"うさぎ" => %{id: "うさぎ", label: ["__Entity__", "Animal"]},
"おかあさん" => %{id: "おかあさん", label: ["__Entity__", "Person"]},
"おじいさん" => %{id: "おじいさん", label: ["__Entity__", "Person"]},
"おとうさん" => %{id: "おとうさん", label: ["__Entity__", "Person"]},
"おばあさん" => %{id: "おばあさん", label: ["__Entity__", "Person"]},
"おむすび" => %{id: "おむすび", label: ["__Entity__", "Object"]},
"お城" => %{id: "お城", label: ["__Entity__", "Place", "__Entity__", "Structure"]},
"かめ" => %{id: "かめ", label: ["__Entity__", "Animal"]},
"きこり" => %{id: "きこり", label: ["__Entity__", "Person"]},
"きじ" => %{id: "きじ", label: ["__Entity__", "Animal"]},
"りゅう宮" => %{id: "りゅう宮", label: ["__Entity__", "Place", "__Entity__", "Location"]},
"乙姫さま" => %{id: "乙姫さま", label: ["__Entity__", "Person"]},
"坂田金時" => %{id: "坂田金時", label: ["__Entity__", "Person"]},
"大広間" => %{id: "大広間", label: ["__Entity__", "Place"]},
"桃" => %{id: "桃", label: ["__Entity__", "Object"]},
"桃太郎" => %{id: "桃太郎", label: ["__Entity__", "Person"]},
"森" => %{id: "森", label: ["__Entity__", "Location"]},
"浦島太郎" => %{id: "浦島太郎", label: ["__Entity__", "Person"]},
"海" => %{id: "海", label: ["__Entity__", "Location", "__Entity__", "Place"]},
"熊" => %{id: "熊", label: ["__Entity__", "Animal"]},
"犬" => %{id: "犬", label: ["__Entity__", "Animal"]},
"猿" => %{id: "猿", label: ["__Entity__", "Animal"]},
"玉手箱" => %{id: "玉手箱", label: ["__Entity__", "Object"]},
"碓井貞光" => %{id: "碓井貞光", label: ["__Entity__", "Person"]},
"都" => %{id: "都", label: ["__Entity__", "Place"]},
"金太郎" => %{id: "金太郎", label: ["__Entity__", "Person"]},
"頼光" => %{id: "頼光", label: ["__Entity__", "Person"]},
"鬼が島" => %{id: "鬼が島", label: ["__Entity__", "Place", "__Entity__", "Location"]},
"鹿" => %{id: "鹿", label: ["__Entity__", "Animal"]}
}
ドキュメントとエンティティ、関係を全て Neo4j に登録します
ドキュメントの場合、ベクトル検索用の埋込ベクトルを "embedding" に追加しています
Boltx.transaction(conn, fn conn ->
documents
|> Enum.each(fn document ->
Boltx.query!(conn, """
CREATE (node:Document {
id: "#{document.id}",
source: "#{document.source}",
text: "#{document.text}",
embedding: [#{document.embedding |> Enum.map(&Float.to_string(&1)) |> Enum.join(",")}]
})
""" |> IO.inspect())
end)
nodes
|> Enum.each(fn {_, node} ->
Boltx.query!(conn, """
CREATE (node:#{Enum.join(node.label, ":")} {id: "#{node.id}"})
""" |> IO.inspect())
end)
schema
|> Enum.map(fn relation ->
conn
|> Boltx.query!("""
MATCH (h {id:"#{relation |> Map.get("head")}"})
MATCH (t {id:"#{relation |> Map.get("tail")}"})
CREATE (h)-[:#{relation |> Map.get("relation")}]->(t)
""" |> IO.inspect())
end)
end)
実行結果を Neo4j Browser で確認してみましょう
Neo4j Browser で以下のクエリを実行します
MATCH (n) -[r]-> (m) RETURN n,r,m
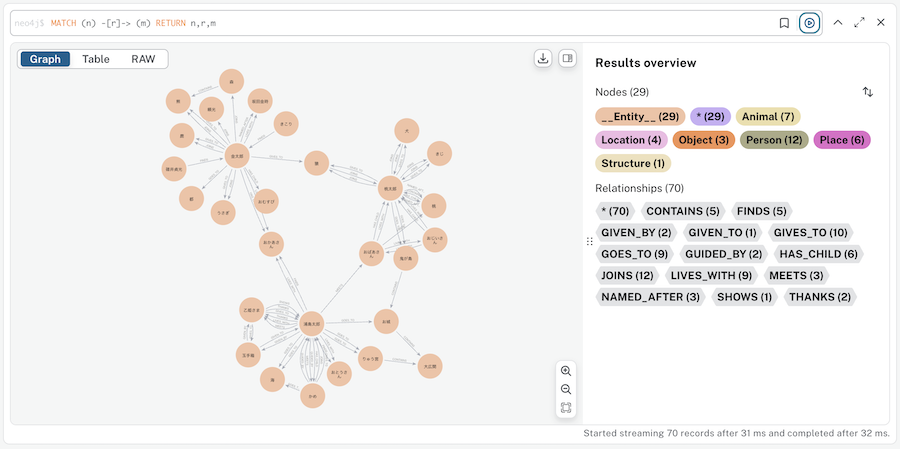
桃太郎、金太郎、浦島太郎のそれぞれのエンティティと関係が登録できています
桃太郎と金太郎の周辺にズームしてみます
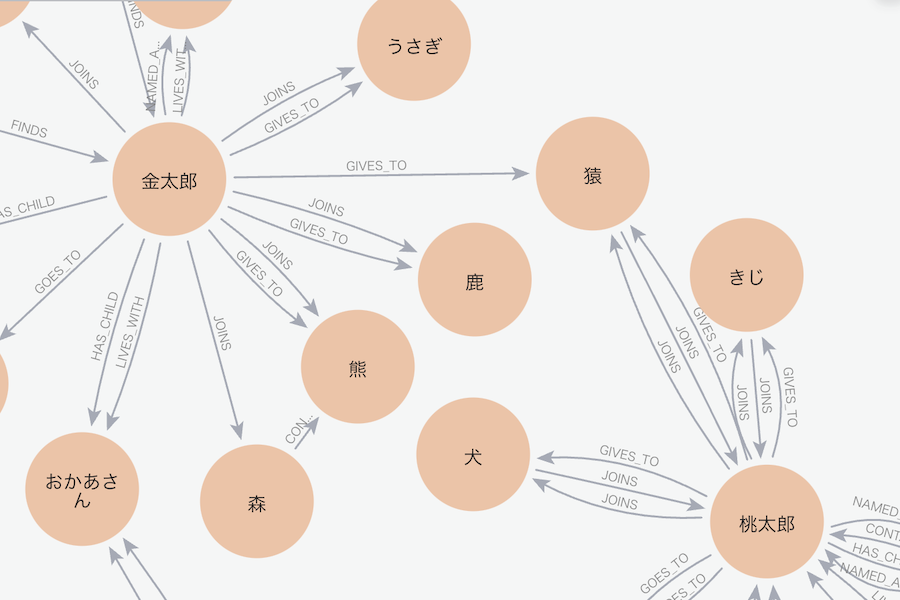
それぞれのお話の登場人物相関図ができているようです
全文検索用のインデックスをドキュメントに対して作成します
今回のドキュメントは日本語なので、OPTIONS {indexConfig: {fulltext.analyzer: 'cjk'}} を指定しています
cjk は中国語、日本語、韓国語を意味し、これらの言語に対応した文書解析を行うように指定しています
この設定を入れない場合、全文検索があまり正しく機能しません
Boltx.query!(conn, """
CREATE FULLTEXT INDEX document IF NOT EXISTS FOR (d:Document) ON EACH [d.text]
OPTIONS {indexConfig: {`fulltext.analyzer`: 'cjk'}}
""")
全文検索用のインデックスをエンティティに対して作成します
ドキュメントのときと同じく、 fulltext.analyzer の指定をしています
Boltx.query!(conn, """
CREATE FULLTEXT INDEX entity IF NOT EXISTS FOR (e:__Entity__) ON EACH [e.id]
OPTIONS {indexConfig: {`fulltext.analyzer`: 'cjk'}}
""")
ベクトル検索用のインデックスをドキュメントに対して作成します
ベクトルの次元数を 1536 、類似度の計算方法にコサイン類似度を指定しています
Boltx.query!(conn, """
CREATE VECTOR INDEX vector IF NOT EXISTS FOR (d:Document) ON d.embedding
OPTIONS {indexConfig: {`vector.dimensions`: 1536, `vector.similarity_function`: "cosine"}}
""")
質問への応答
Neo4j に登録した内容を使って、質問に答えてみます
question = "桃太郎の仲間は誰ですか"
ベクトル検索
質問文をベクトルに変換します
question_feature = get_feature.(question)
実行結果
[0.013788661, 0.012788448, -0.05282762, -2.8513747e-4, 0.044458482, 0.01846313, ...]
ベクトルを文字列化します
str_feature = question_feature |> Enum.map(&Float.to_string(&1)) |> Enum.join(",")
実行結果
"0.013788661,0.012788448,-0.05282762,-2.8513747e-4,0.044458482,0.01846313" <> ...
ベクトル用インデックスを使って、質問文に似ているドキュメントを検索してみます
conn
|> Boltx.query!("""
CALL db.index.vector.queryNodes("vector", 4, [#{str_feature}])
YIELD node, score
WITH node, score LIMIT 4
WITH collect({node:node, score:score}) AS nodes, max(score) AS max
UNWIND nodes AS n
RETURN n.node.text AS text, (n.score / max) AS score
""")
|> Map.get(:results)
実行結果
[
%{
"score" => 1.0,
"text" => " 桃太郎は、犬と猿をしたがえて、船からひらりと陸の上にとび上がりました。..."
},
%{
"score" => 0.9776340096200203,
"text" => "むかし、むかし、あるところに、おじいさんとおばあさんがありました。..."
},
%{
"score" => 0.964001457482406,
"text" => " おじいさんとおばあさんは、それはそれはだいじにして桃太郎を育てました。..."
},
%{
"score" => 0.9382396603875057,
"text" => " 桃太郎はずんずん行きますと、大きな山の上に来ました。..."
}
]
ちゃんと、桃太郎の文章が上位4つとして取得できました
全文検索
全文検索用のインデックスを使用し、質問文に関係するドキュメントを取得します
conn
|> Boltx.query!("""
CALL db.index.fulltext.queryNodes("document", "#{question}", {limit: 4})
YIELD node, score
WITH collect({node:node, score:score}) AS nodes, max(score) AS max
UNWIND nodes AS n
RETURN n.node.text AS text, (n.score / max) AS score
""")
|> Map.get(:results)
実行結果
[
%{
"score" => 1.0,
"text" => " 桃太郎はずんずん行きますと、大きな山の上に来ました。..."
},
%{
"score" => 0.9368487821878516,
"text" => " おじいさんとおばあさんは、それはそれはだいじにして桃太郎を育てました。..."
},
%{
"score" => 0.9095078876919919,
"text" => " 桃太郎は、犬と猿をしたがえて、船からひらりと陸の上にとび上がりました。..."
},
%{
"score" => 0.651711515182827,
"text" => "むかし、むかし、あるところに、おじいさんとおばあさんがありました。..."
}
]
順番は違いますが、こちらも同じく桃太郎の文章を取得できています
ベクトル検索と全文検索のハイブリッド検索
それぞれの検索結果を結合し、上位4つのドキュメントを取得する関数を用意します
get_document_context = fn question ->
str_feature =
question
|> get_feature.()
|> Enum.map(&Float.to_string(&1))
|> Enum.join(",")
conn
|> Boltx.query!("""
CALL () {
CALL db.index.vector.queryNodes("vector", 4, [#{str_feature}])
YIELD node, score
WITH node, score LIMIT 4
WITH collect({node:node, score:score}) AS nodes, max(score) AS max
UNWIND nodes AS n
RETURN n.node AS node, (n.score / max) AS score
UNION
CALL db.index.fulltext.queryNodes("document", "#{question}", {limit: 4})
YIELD node, score
WITH collect({node:node, score:score}) AS nodes, max(score) AS max
UNWIND nodes AS n
RETURN n.node AS node, (n.score / max) AS score
} WITH node, max(score) AS score ORDER BY score DESC LIMIT 4
RETURN node.text AS text, score
""")
|> Map.get(:results)
|> Enum.map(fn %{"text" => text} -> text end)
|> Enum.join("\n")
end
document_context = get_document_context.(question)
実行結果
" 桃太郎は、犬と猿をしたがえて、船からひらりと陸の上にとび上がりました。..."
グラフ検索
ラベル間の関係について、存在する全ての組み合わせを取得します
get_all_relations = fn ->
conn
|> Boltx.query!("""
MATCH (n:__Entity__)-[r]->(m:__Entity__)
RETURN DISTINCT labels(n) AS head, type(r) AS type, labels(m) AS tail
""")
|> Map.get(:results)
|> Enum.flat_map(fn %{"head" => head, "tail" => tail, "type" => type} ->
for h <- Enum.reject(head, &(&1 == "__Entity__")),
t <- Enum.reject(tail, &(&1 == "__Entity__")) do
"(h:#{h}) -[:#{type}]-> (t:#{t})"
end
end)
|> Enum.uniq()
end
all_relations = get_all_relations.()
実行結果
["(h:Object) -[:GIVEN_BY]-> (t:Person)", "(h:Object) -[:GIVEN_TO]-> (t:Person)",
"(h:Person) -[:FINDS]-> (t:Person)", "(h:Person) -[:LIVES_WITH]-> (t:Person)",
"(h:Person) -[:HAS_CHILD]-> (t:Person)", "(h:Person) -[:FINDS]-> (t:Object)",
"(h:Place) -[:CONTAINS]-> (t:Place)", "(h:Structure) -[:CONTAINS]-> (t:Place)",
"(h:Animal) -[:GOES_TO]-> (t:Place)", "(h:Animal) -[:GOES_TO]-> (t:Location)",
"(h:Animal) -[:GUIDED_BY]-> (t:Person)", "(h:Animal) -[:MEETS]-> (t:Person)",
"(h:Animal) -[:JOINS]-> (t:Person)", "(h:Animal) -[:GIVES_TO]-> (t:Person)",
"(h:Location) -[:CONTAINS]-> (t:Place)", "(h:Person) -[:THANKS]-> (t:Person)",
"(h:Person) -[:GIVES_TO]-> (t:Object)", "(h:Person) -[:GIVES_TO]-> (t:Person)",
"(h:Person) -[:SHOWS]-> (t:Person)", "(h:Object) -[:CONTAINS]-> (t:Person)",
"(h:Object) -[:NAMED_AFTER]-> (t:Person)", "(h:Person) -[:JOINS]-> (t:Animal)",
"(h:Person) -[:GOES_TO]-> (t:Place)", "(h:Person) -[:GOES_TO]-> (t:Location)",
"(h:Person) -[:GIVES_TO]-> (t:Animal)", "(h:Person) -[:NAMED_AFTER]-> (t:Object)",
"(h:Person) -[:HAS_CHILD]-> (t:Object)", "(h:Location) -[:CONTAINS]-> (t:Animal)",
"(h:Person) -[:MEETS]-> (t:Person)", "(h:Person) -[:GOES_TO]-> (t:Structure)",
"(h:Person) -[:GIVEN_BY]-> (t:Object)", "(h:Person) -[:GUIDED_BY]-> (t:Animal)",
"(h:Person) -[:HAS_CHILD]-> (t:Animal)", "(h:Person) -[:JOINS]-> (t:Location)",
"(h:Person) -[:NAMED_AFTER]-> (t:Person)", "(h:Person) -[:JOINS]-> (t:Person)",
"(h:Place) -[:CONTAINS]-> (t:Structure)", "(h:Location) -[:CONTAINS]-> (t:Structure)"]
この関係性の情報を元に、質問に対する回答をグラフデータベースから取得するためのクエリを LLM に作ってもらいます
get_relationship_query = fn question, all_relations ->
openai
|> Chat.Completions.create!(%{
model: model_id,
messages: [
ChatMessage.system("""
Task:Extract entities from questions and generate Cypher statement to query a graph database.
Instructions:
Use only the provided relationships and entity properties.
Do not use any other relationships or properties that are not provided.
Relationships: #{Enum.join(all_relations, ",")}
Entity properties: id
Output format:
```json
{
"entities": "<The Lit of entities in the question>",
"query": "<Cypher query>",
"description": "<Output description of the Cypher query>"
}
```
Output example:
```json
{
"entities": ["太郎"],
"query": "MATCH (head:Person|Animal {id: \"太郎\"}) -[rel:BUY|GET]-> (tail) RETURN tail.id AS output",
"description": "太郎が買ったもの"
}
```
IMPORTANT NOTES:
- Do not include any explanations or apologies in your responses.
- Do not respond to any questions that might ask anything else than for you to construct a Cypher statement.
- Do not include any text except the generated Cypher statement and the description.
- Specify similar relationships and entiries to match any of them, such as `(head:LabelA|LabelB) -[rel:TypeA|TypeB|TypeC|TypeD]-> (tail:LabelA|LabelB)`
- The query must always return “output”
The question is:
#{question}
""")
]
})
|> Map.get("choices")
|> Enum.at(0)
|> Map.get("message")
|> Map.get("content")
|> String.replace("```json", "")
|> String.replace("```", "")
|> Jason.decode!()
end
プロンプトの和訳
タスク: 質問からエンティティを抽出し、グラフデータベースを照会するCypher文を生成する。
指示:
- 提供されたリレーションシップとエンティティプロパティのみを使用してください
- 提供されていないリレーションシップやプロパティは使用しないでください
- リレーションシップ: #{Enum.join(all_relations, “,”)}
- エンティティプロパティ: id
出力形式:
{
"entities": "<質問内のエンティティのリスト>",
"query": "<Cypherクエリ>",
"description": "<Cypherクエリの出力内容の説明>"
}
出力例:
{
"entities": ["太郎"],
"query": "MATCH (head:Person|Animal {id: \"太郎\"}) -[rel:BUY|GET]-> (tail) RETURN tail.id AS output",
"description": "太郎が買ったもの"
}
重要な注意事項:
- 回答に説明や謝罪を含めないでください
- Cypher文の構築以外の質問には回答しないでください
- 生成されたCypher文と説明以外のテキストを含めないでください
-
(head:LabelA|LabelB) -[rel:TypeA|TypeB|TypeC|TypeD]-> (tail:LabelA|LabelB)のように、類似するリレーションシップやエンティティを指定してください - クエリは必ずoutputを返すようにしてください
%{
"query" => query,
"entities" => entities,
"description" => description
}
= get_relationship_query.(question, all_relations)
実行結果
%{
"description" => "桃太郎の仲間",
"entities" => ["桃太郎"],
"query" => "MATCH (head:Person {id: '桃太郎'}) -[rel:JOINS]-> (tail:Animal|Person) RETURN tail.id AS output"
}
生成されたクエリを実行する関数を定義します
また、抽出されたエンティティの関係もグラフデータベースから取得します
類似したエンティティでも取得できるように全文検索用のインデックスを使用します
get_graph_context = fn question ->
all_relations = get_all_relations.()
%{
"entities" => entities,
"query" => query,
"description" => description
}
= get_relationship_query.(question, all_relations)
IO.inspect(query)
query_result =
conn
|> Boltx.query!(query)
|> Map.get(:results)
|> Enum.map(fn %{"output" => output} -> output end)
|> Enum.uniq()
|> Enum.join(",")
query_result =
if query_result == "" do
""
else
"#{description}: #{query_result}"
end
IO.puts(query_result)
entities_relations =
entities
|> Enum.flat_map(fn entity ->
conn
|> Boltx.query!("""
CALL db.index.fulltext.queryNodes('entity', "#{entity}", {limit:2})
YIELD node,score
WITH collect({node:node, score:score}) AS nodes, max(score) AS max
UNWIND nodes AS n
WITH n.node AS node, (n.score / max) AS score
WHERE score > 0.7
CALL (node,node) {
WITH node
MATCH (node)-[r]->(neighbor)
RETURN node.id + ':' + type(r) + ' ' + neighbor.id AS output
UNION ALL
WITH node
MATCH (node)<-[r]-(neighbor)
RETURN neighbor.id + ':' + type(r) + ' ' + node.id AS output
}
RETURN output, score LIMIT 50
""")
|> Map.get(:results)
|> Enum.map(fn %{"output" => output} -> output end)
end)
|> Enum.uniq()
|> Enum.join(",")
IO.inspect(entities)
IO.puts(entities_relations)
"#{query_result}\n#{entities_relations}"
end
graph_context = get_graph_context.(question)
Kino.Text.new(graph_context)
実行結果
桃太郎の仲間: きじ,猿,犬
桃太郎:JOINS きじ,桃太郎:GOES_TO 鬼が島,桃太郎:GIVES_TO きじ,桃太郎:GIVES_TO 猿,桃太郎:JOINS 猿,桃太郎:GIVES_TO 犬,桃太郎:NAMED_AFTER 桃,桃太郎:JOINS 犬,桃太郎:HAS_CHILD 桃,おばあさん:LIVES_WITH 桃太郎,おばあさん:HAS_CHILD 桃太郎,犬:JOINS 桃太郎,きじ:JOINS 桃太郎,おじいさん:LIVES_WITH 桃太郎,猿:JOINS 桃太郎,おじいさん:HAS_CHILD 桃太郎,桃:CONTAINS 桃太郎,桃:NAMED_AFTER 桃太郎
質問に対する回答と、桃太郎との関係が抽出できました
コンテキスト情報を参照した回答
ここまで取得してきたコンテキスト情報を使用し、質問に回答します
answer = fn question, document_context, graph_context ->
openai
|> Chat.Completions.create!(%{
model: model_id,
messages: [
ChatMessage.system("""
You are an assistant that helps to form nice and human understandable answers.
The information part contains the provided information that you must use to construct an answer.
The provided information is authoritative, you must never doubt it or try to use your internal knowledge to correct it.
Make the answer sound as a response to the question. Do not mention that you based the result on the given information.
Here is an example:
```
## Graph Context
太郎の買ったもの: りんご
二郎:BUY りんご
## Document Context
三郎はりんごを買いました
## Question
りんごを買ったのは誰ですか
## Helpful Answer
りんごを買ったのは太郎と二郎、三郎です
```
Follow this example when generating answers.
If the provided contexts is empty, say that you don't know the answer.
## Graph Context
#{graph_context}
## Unstructured Context
#{document_context}
## Question
#{question}
## Helpful Answer
""")
]
})
|> Map.get("choices")
|> Enum.at(0)
|> Map.get("message")
|> Map.get("content")
end
プロンプトの和訳
あなたは、質問に対してわかりやすく自然な回答を作成するためのアシスタントです。
提供される情報は信頼できるものであり、それに基づいて回答を作成してください。
提供された情報を疑ったり、内部知識を使って訂正しようとしたりしてはいけません。
回答は質問への答えとして自然な形にしてください。提供された情報に基づいていることを明記しないでください。
## グラフコンテキスト
太郎の買ったもの: りんご
二郎:BUY りんご
## ドキュメントコンテキスト
三郎はりんごを買いました
## 質問
りんごを買ったのは誰ですか
## わかりやすい回答
りんごを買ったのは太郎と二郎、三郎です
この例に従って回答を作成してください。
もし提供されるコンテキストが空の場合、答えがわからないと述べてください。
answer.(question, document_context, graph_context)
実行結果
"桃太郎の仲間はきじ、猿、犬です。"
様々なコンテキスト情報を利用し、正しく回答することができました
ここまでの一連処理を一つの関数にまとめます
answer_with_hybrid_rag = fn question ->
document_context = get_document_context.(question)
graph_context = get_graph_context.(question)
answer.(question, document_context, graph_context)
end
グラフデータベースに登録できなかった「金太郎の武器」に関する質問をしてみます
answer_with_hybrid_rag.("金太郎の武器は何ですか")
標準出力
"MATCH (tail:Object {id: \"武器\"})<-[:GIVEN_BY]-(head:Person {id: \"金太郎\"}) RETURN tail.id AS output"
["金太郎", "武器"]
金太郎:LIVES_WITH 坂田金時,金太郎:JOINS 森,金太郎:JOINS 鹿,金太郎:GIVES_TO 鹿,金太郎:NAMED_AFTER 坂田金時,金太郎:JOINS うさぎ,金太郎:JOINS 頼光,金太郎:JOINS 熊,金太郎:HAS_CHILD おむすび,金太郎:GIVES_TO うさぎ,金太郎:GIVES_TO 猿,金太郎:LIVES_WITH おかあさん,金太郎:HAS_CHILD おかあさん,金太郎:GOES_TO 都,金太郎:GIVES_TO 熊,碓井貞光:FINDS 金太郎,きこり:FINDS 金太郎
実行結果
"金太郎の武器は大きなまさかりです。"
グラフデータベースからは武器に関する情報を得られませんでしたが、ベクトル検索や全文検索によって正しい回答ができました
浦島太郎について訊いてみます
answer_with_hybrid_rag.("浦島太郎はどこに行きましたか")
標準出力
"MATCH (head:Person {id: \"浦島太郎\"}) -[rel:GOES_TO]-> (tail:Place|Location|Structure) RETURN tail.id AS output"
浦島太郎が行った場所: りゅう宮,海,お城
["浦島太郎"]
浦島太郎:FINDS おかあさん,浦島太郎:MEETS おばあさん,浦島太郎:GOES_TO りゅう宮,浦島太郎:GOES_TO 海,浦島太郎:LIVES_WITH おかあさん,浦島太郎:GOES_TO お城,浦島太郎:LIVES_WITH 乙姫さま,浦島太郎:GIVEN_BY 玉手箱,浦島太郎:FINDS おとうさん,浦島太郎:LIVES_WITH おとうさん,浦島太郎:GUIDED_BY かめ,浦島太郎:HAS_CHILD かめ,浦島太郎:THANKS 乙姫さま,浦島太郎:MEETS 乙姫さま,乙姫さま:THANKS 浦島太郎,かめ:GUIDED_BY 浦島太郎,乙姫さま:GIVES_TO 浦島太郎,乙姫さま:SHOWS 浦島太郎,かめ:MEETS 浦島太郎,かめ:JOINS 浦島太郎,かめ:GIVES_TO 浦島太郎,玉手箱:GIVEN_TO 浦島太郎
実行結果
"浦島太郎は、りゅう宮、海、お城に行きました。"
グラフデータベースの検索結果を元に正しく回答できています
複雑な例として、桃太郎と金太郎の両方の家来になっている人物を尋ねてみます
answer_with_hybrid_rag.("桃太郎と金太郎、両方の家来になっているのは誰ですか")
標準出力
"MATCH (tail) <-[rel:JOINS]- (head:Person {id: '桃太郎'}), (tail) <-[rel2:JOINS]- (head2:Person {id: '金太郎'}) RETURN tail.id AS output"
["桃太郎", "金太郎"]
桃太郎:JOINS きじ,桃太郎:GOES_TO 鬼が島,桃太郎:GIVES_TO きじ,桃太郎:GIVES_TO 猿,桃太郎:JOINS 猿,桃太郎:GIVES_TO 犬,桃太郎:NAMED_AFTER 桃,桃太郎:JOINS 犬,桃太郎:HAS_CHILD 桃,おばあさん:LIVES_WITH 桃太郎,おばあさん:HAS_CHILD 桃太郎,犬:JOINS 桃太郎,きじ:JOINS 桃太郎,おじいさん:LIVES_WITH 桃太郎,猿:JOINS 桃太郎,おじいさん:HAS_CHILD 桃太郎,桃:CONTAINS 桃太郎,桃:NAMED_AFTER 桃太郎,金太郎:LIVES_WITH 坂田金時,金太郎:JOINS 森,金太郎:JOINS 鹿,金太郎:GIVES_TO 鹿,金太郎:NAMED_AFTER 坂田金時,金太郎:JOINS うさぎ,金太郎:JOINS 頼光,金太郎:JOINS 熊,金太郎:HAS_CHILD おむすび,金太郎:GIVES_TO うさぎ,金太郎:GIVES_TO 猿,金太郎:LIVES_WITH おかあさん,金太郎:HAS_CHILD おかあさん,金太郎:GOES_TO 都,金太郎:GIVES_TO 熊,碓井貞光:FINDS 金太郎,きこり:FINDS 金太郎
実行結果
"桃太郎と金太郎、両方の家来になっているのは「猿」です。"
金太郎と猿の関係が "GIVES_TO" になっているためクエリでは猿を抽出できませんでしたが、桃太郎と金太郎に関する関係をすべて抽出できているため、「猿」と答えることができました
まとめ
Neo4j を使うことで、ベクトル検索、全文検索、グラフ検索全てを駆使したハイブリッド RAG が実装できました
やはり、日本語では注意しないといけない点が多く、 LangChain の実装そのままではなく、それなりに改良して実装することになりました
まだまだ改良の余地は多そうですが、 RAG の仕組みはよく理解できたと思います