はじめに
先日参加した JAWS DAYS 2024 にて紹介されていた、 Turing さんのマルチモーダル LLM を Google Colab で動かしてみます
マルチモーダルとはテキスト、画像、音声など複数種類のデータを一度に扱えることを意味します
本記事で動かしてみる BLIP は、画像を解釈して質問に返答してくれます
AIに写真を見せて「この写真に写っているコップは何色?」みたいな質問ができるわけです
Turing さんは完全自動運転を目指しており、その中で LLM を使おうとしています
車に搭載したカメラの映像から周囲のモノを認識し、適切な運転をさせようという試みですね
Turing 棚橋さんの記事はこちら
前回書いた Stockmark 社の日本語 LLM を動かす記事はこちら
モデルの取得元
モデルは Hugging Face で公開されています
モデルのダウンロードに Hugguing Face のアクセストークンが必要になるので、サインアップしてトークンを用意しておきましょう
設定画面の左メニューから「Access Tokens」を開き、「New token」ボタンでトークンが作成できます
Google Colab のランタイム
7b = 70億パラメーターのモデルを使います
GPU RAM は 16.2 GB 使われたため、ランタイムには A100 GPU を選択する必要があります
お金はかかりますが、 Google Colab Pro を契約しましょう
他の LLM も色々触ってみるのであれば、結果安上がりだと思います
ノートブックの設定
新しいノートブックを開きます
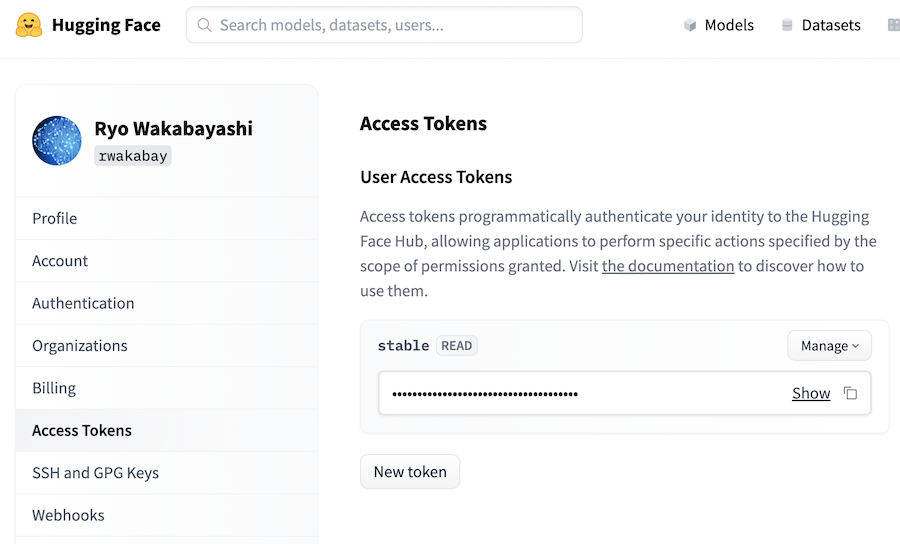
上メニューから「ランタイム」 |> 「ランタイムのタイプを変更」を開きます

ハードウェアアクセラレータで「A100 GPU」を選択し、「保存」をクリックします
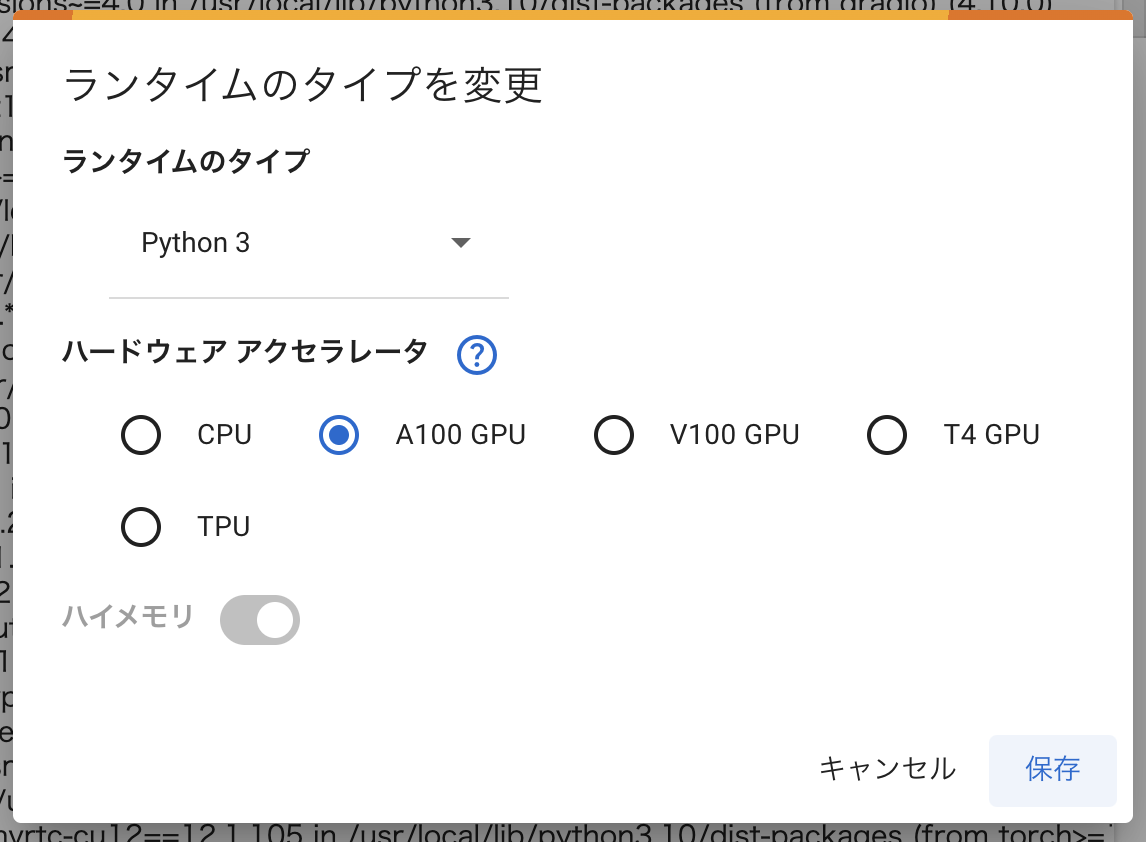
左メニューの鍵アイコンをクリックし、 HF_TOKEN という名前で Hugging Face のアクセストークンをシークレットに登録しておきます
「ノートブックからのアクセス」を忘れず ON にしておきましょう
セットアップ
以降、 Colab のセルにコードを貼り付けて実行します
初回セル実行時、場合によっては「A100 GPU」を使うことができず、「V100 GPU」で実行されてしまうことがあります
そのまま進んでも GPU RAM 不足になるため、その場合はランタイムを接続解除、削除しましょう
しばらく待ってから改めてランタイムタイプに「A100 GPU」を選択し、再度実行して A100 が使えるまでリトライします
リトライが嫌な場合は Colab のさらに上のプランを契約しましょう
Heron の GitHub リポジトリーをクローンしてきます
!git clone https://github.com/turingmotors/heron.git
Heron は Turing 社が開発しているマルチモーダル学習ライブラリです
Heron のモジュールを使うため、ディレクトリーを移動します
%cd heron
pip 自体を最新化してから、必要なモジュールをインストールします
!pip install --upgrade pip
!pip install accelerate datasets deepspeed einops evaluate gradio peft protobuf sentencepiece transformers wandb japanize-matplotlib
公式の Heron インストール手順に従うのであれば以下のコマンドになります
!pip install --upgrade pip
!pip install -r requirements.txt
!pip install -e .
しかし、上記手順でインストールすると開発用のモジュール(isort や black、pre-commit)等もインストールされてしまいます
また、 Jupyter 自体の更新もされるため、セッション再起動を促されてしまいます
不要なインストールを避けるため、モジュールを個別に指定しています
更に、今回は簡単な UI を構築するため、 Gradio を追加しています
モジュールをインポートします
import gradio as gr
import requests
import torch
from heron.models.video_blip import VideoBlipForConditionalGeneration, VideoBlipProcessor
from PIL import Image
from transformers import LlamaTokenizer
gradio は最後に UI を作るためのものなので、モデルを動かしたいだけの場合は不要です
モデルのロード
Hugging Face からモデルをダウンロードし、ロードします
device_id = 0
device = f"cuda:{device_id}"
MODEL_NAME = "turing-motors/heron-chat-blip-ja-stablelm-base-7b-v1"
model = VideoBlipForConditionalGeneration.from_pretrained(MODEL_NAME)
公式の手順では以下のようにロードしています
model = VideoBlipForConditionalGeneration.from_pretrained(
MODEL_NAME, torch_dtype=torch.float16, ignore_mismatched_sizes=True
)
残念ながらこの手順だとエラーが発生したため、オプションの指定を削除しています
ここで torch_dtype を指定しなくても、この後のコードで半精度に変換しているので問題なさそうです
モデルを半精度に変換してから、使用するデバイスを GPU に変更します
model = model.half()
model.eval()
model.to(device)
前処理を準備します
processor = VideoBlipProcessor.from_pretrained("Salesforce/blip2-opt-2.7b")
tokenizer = LlamaTokenizer.from_pretrained("novelai/nerdstash-tokenizer-v1", additional_special_tokens=['▁▁'])
processor.tokenizer = tokenizer
生成
画像とテキストを入力として、それに応じたテキストを生成します
まずは、Hugging Face の Usage と同じ入力を使います
url = "https://www.barnorama.com/wp-content/uploads/2016/12/03-Confusing-Pictures.jpg"
image = Image.open(requests.get(url, stream=True).raw)
image

text = f"##human: この画像の面白い点は何ですか?\n##gpt: "
画像とテキストに前処理を施します
inputs = processor(
text=text,
images=image,
return_tensors="pt",
truncation=True,
)
inputs = {k: v.to(device) for k, v in inputs.items()}
inputs["pixel_values"] = inputs["pixel_values"].to(device, torch.float16)
eos_token_id_list = [
processor.tokenizer.pad_token_id,
processor.tokenizer.eos_token_id,
int(tokenizer.convert_tokens_to_ids("##"))
]
生成を実行します
with torch.no_grad():
out = model.generate(**inputs,
max_length=256,
do_sample=False,
temperature=0.,
eos_token_id=eos_token_id_list,
no_repeat_ngram_size=2)
# print result
print(processor.tokenizer.batch_decode(out)[0])
結果は以下のようなテキストになります
画像の面白い点は、黄色いタクシーの荷台に立っている男性が、タクシーに積まれたアイロン台でアイロンの仕事をしていることだ。このシーンは、アイロンは通常アイロニングやプレスに使われるものであり、日常的なアイテムの典型的な使い方ではないため、興味深く、珍しい。アイロールをしている男性は、この型破りなアイデアを実行する技術と専門知識を披露している。
<|pad|>
UI付きで実行
Gradio を使って簡易的な UI を用意します
まず、入力を出力に変換するための関数を用意します
def infer(image, text):
inputs = processor(
text=text,
images=image,
return_tensors="pt",
truncation=True,
)
inputs = {k: v.to(device) for k, v in inputs.items()}
inputs["pixel_values"] = inputs["pixel_values"].to(device, torch.float16)
eos_token_id_list = [
processor.tokenizer.pad_token_id,
processor.tokenizer.eos_token_id,
int(tokenizer.convert_tokens_to_ids("##"))
]
with torch.no_grad():
out = model.generate(**inputs,
max_length=256,
do_sample=False,
temperature=0.,
eos_token_id=eos_token_id_list,
no_repeat_ngram_size=2)
return processor.tokenizer.batch_decode(out)[0]
Gradio で入出力を定義します
gr.Interface(
fn=infer,
inputs=[
gr.Image(label="Image"),
gr.Textbox(label="Prompt"),
],
outputs=[gr.Textbox()]
).launch(debug=True)
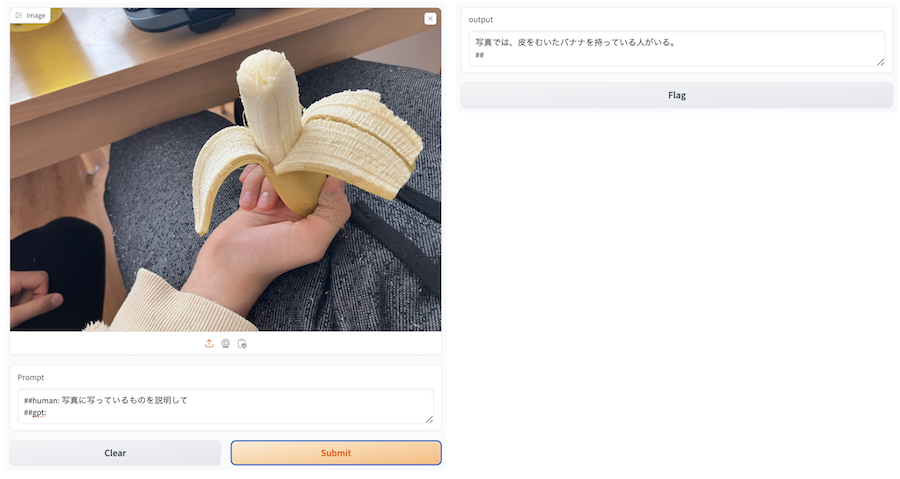
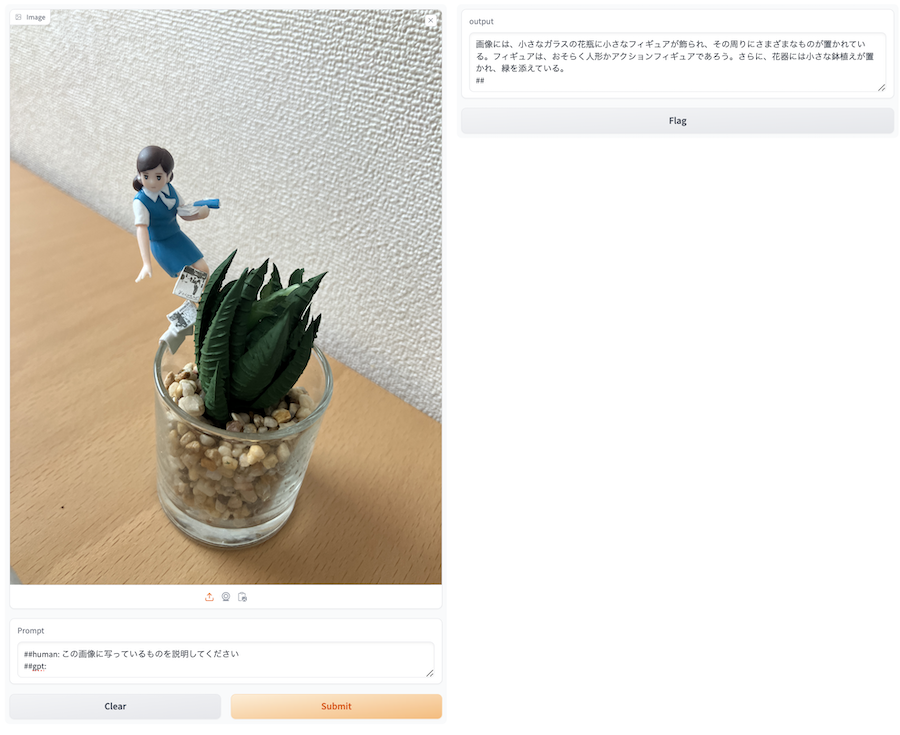
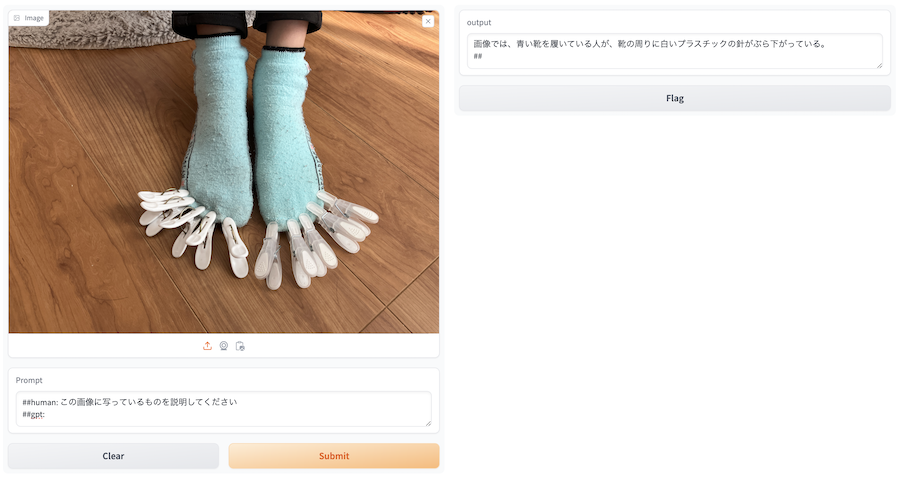
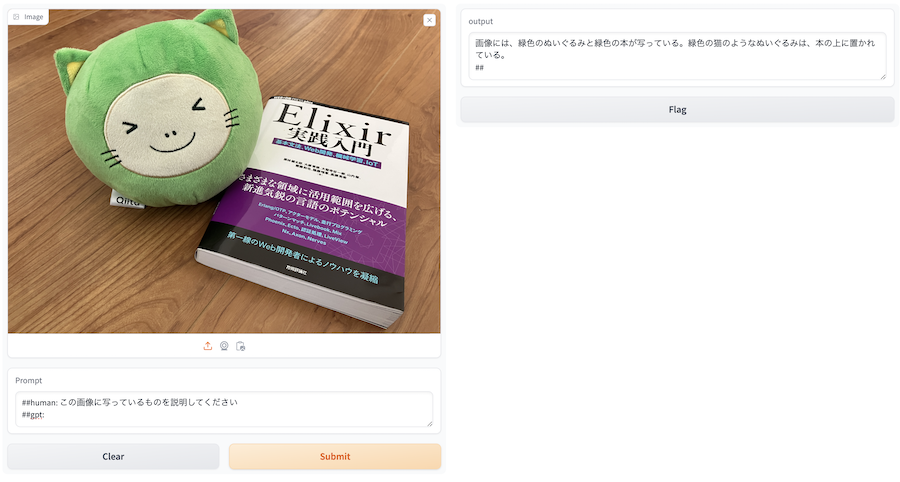
実行すると、以下のような UI が表示されます
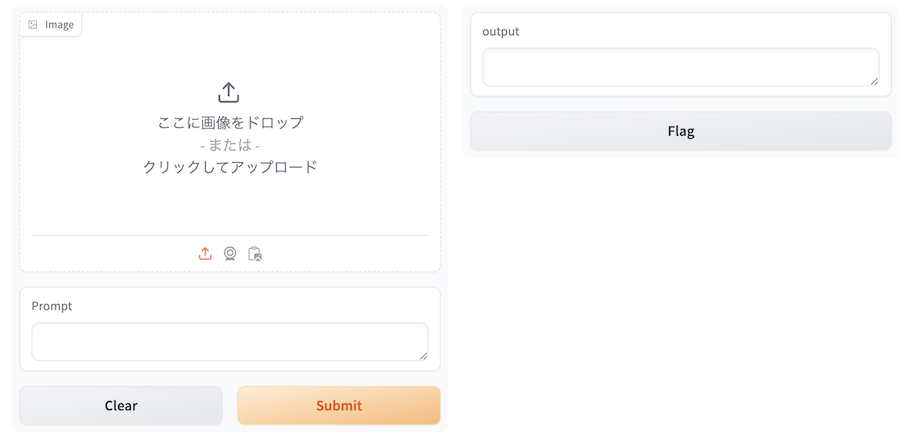
左側の imgae で適当な画像を選択し、 Prompt に適当な文言を入れてみましょう
「Submit」を押すと、右側の output に生成結果が表示されます
改行しようとして Enter キーを押すと「Submit」を押したときと同じように生成処理が実行されてしまいます
改行したい場合は Shift キーを押しながら Enter キーを押しましょう
一通り遊び終わったら上メニューから「ランタイム」|>「ランタイムを接続解除して削除」を選択し、ランタイムを削除しておきましょう
ランタイムを動かし続けていると、無駄に コンピューティング・ユニットを消費してしまいます
まとめ
Turing 社のマルチモーダル LLM heron-blip-v1 を Google Colaboratory で動かすことができました
複雑なものは説明が難しいようですが、用途を限定すれば実用できるかもしれません