はじめに
Amazon SageMaker は AWS 上で AI のトレーニングやリアルタイム推論などを簡単に実行できるサービスです
今回は YOLOv7 による物体検出を SageMaker 上で実行します
その際、 SageMaker で使える以下のインスタンスタイプでそれぞれ推論を実行し、速度と料金を比較してみました
- ml.m5.xlarge (Intel CPU)
- ml.c7g.xlarge (AWS Graviton3)
- ml.g4dn.xlarge (NVIDIA GPU)
- ml.inf1.xlarge (Amazon Inferentia)
どの程度、速度、料金に差があるでしょうか
元とするコンテナイメージが異なるなど、厳密な比較にはなっていません
あくまでも参考程度として捉えてください
以降、実行した内容についての説明がありますが、結果だけ知りたい方はこちらへ
検証に使用したコードは以下のリポジトリーに格納しています
(今後更新する予定はないため、アーカイブ状態で公開しています)
詳細な手順は README.md をご確認ください
各インスタンスタイプの説明
インスタンスタイプによって SageMaker で使われるマシン(インスタンス)のアーキテクチャ(CPU、GPUの種類)、スペック(CPUのコア数、メモリ容量など)が変わります
当然、インスタンスタイプによって推論速度が変わり、また1時間あたりに発生する料金も変わります
今回利用するインスタンスタイプの料金は以下のようになっています
(※安いので、リージョンは us-west-2 オレゴンを使用)
(※1ドル=138.54円換算、1ヶ月=24時間×30日で計算)
| インスタンスタイプ | アーキテクチャ | 料金($/hours) | 料金(¥/月) |
|---|---|---|---|
| ml.m5.xlarge | Intel CPU | 0.204 | 20,349 |
| ml.c7g.xlarge | AWS Graviton3 | 0.174 | 17,356 |
| ml.g4dn.xlarge | NVIDIA GPU | 0.736 | 73,415 |
| ml.inf1.xlarge | Inferentia | 0.297 | 29,635 |
ml.c7g.xlarge は最新世代なのでかなり安いです
GPU の ml.g4dn.xlarge が断トツで高いです
(他の GPU を積んだインスタンスタイプと比べればこれでも安いですが)
Inferentia の ml.inf1.xlarge は ml.g4dn.xlarge と比べると 60% も低料金になっていますが、これでどこまで高速に推論できるのか、が今回の見どころです
M5 インスタンス
M5 インスタンスは Intel の CPU で動作します
GPU は使えませんが、コストパフォーマンスに優れています
C7G インスタンス (Graviton3)
Graviton は AWS が設計した特別な CPU です
AWS での利用に最適化するよう設計されています
G4DN インスタンス
G4DN インスタンスは NVIDIA の GPU を使うことができます
GPU によって高速な推論が可能になります
INF1 インスタンス (Inferentia)
Inferentia は AWS が設計した CPU アクセラレーターです
AI に特化しているので、パフォーマンスが期待できます
YOLOv7
YOLOv7 は高速、高精度の物体検出用 AI モデルです
その中でも今回は YOLOv7x を使います
公式サイトによると 114fps なので、1秒間に114回推論できる(1回の推論が 8.8 msec)ほどの速さです
(すでに YOLOv8 も出てはいますが、、、)
インフラの準備
今回は推論するモデルのトレーニングも行います
そのため、トレーニング用、推論用の各種 AWS インフラを構築します
本来であれば Terraform などを使うのですが、今回は1回限りなのでシェルスクリプト等で構築しました
IAM ロール
SageMaker でトレーニングと推論を実行するための IAM ロールを作成します
ポリシーには以下のようなパーミッションを付与します
(一時的な物なので、厳密な設定にしていません)
policy/sagemaker-yolov7-train-role-policy
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": [
"cloudwatch:PutMetricData",
"logs:CreateLogStream",
"logs:PutLogEvents",
"logs:CreateLogGroup",
"logs:DescribeLogStreams",
"s3:ListBucket",
"s3:GetObject",
"s3:PutObject",
"ecr:GetAuthorizationToken"
],
"Resource": [
"*"
]
},
{
"Effect": "Allow",
"Action": [
"ecr:BatchCheckLayerAvailability",
"ecr:GetDownloadUrlForLayer",
"ecr:BatchGetImage"
],
"Resource": [
"arn:aws:ecr:*:*:repository/*sagemaker*"
]
}
]
}
ECR リポジトリー
YOLOv7 のトレーニング、推論用コンテナイメージを格納するための ECR リポジトリーを作成します
- トレーニング用(ml.g4dn.xlarge)
- 推論用
- CPU 用 (ml.m5.xlarge)
- Graviton 用 (ml.c7g.xlarge)
- GPU 用 (ml.g4dn.xlarge)
- Inferentia 用 (ml.inf1.xlarge)
トレーニング
トレーニング用イメージのデプロイ
トレーニングは ml.g4dn.xlarge のインスタンスを使って GPU 上で実行します
そのため、トレーニング用のコンテナイメージは CUDA のイメージを元に作成します
YOLOv7 のトレーニングを行うため、 GitHub からソースコードをクローンし、転移学習元のモデルもダウンロードします
FROM nvidia/cuda:11.2.1-cudnn8-devel
...
RUN git clone https://github.com/WongKinYiu/yolov7.git /work
...
RUN wget --quiet --continue \
--timestamping https://github.com/WongKinYiu/yolov7/releases/download/v0.1/yolov7x_training.pt \
--output-document ./yolov7x_training.pt
...
トレーニングには YOLOv7 公式の train.py を利用します
train.py の実行後、ログやグラフなどの学習経過が記録されたファイルと、最善の重み(best.pt)などを S3 へのアップロード用ディレクトリーにコピーしておきます
...
python train.py \
--weights "${weights}" \
--cfg "${cfg}" \
--data "${data}" \
--hyp "${hyp}" \
--epochs "${epochs}" \
--batch-size "${batch_size}" \
--img-size "${size}" "${size}" \
--device "${device}" \
--workers "${workers}" \
--name "${name}" || true
cp "runs/train/${name}"/*.png "${MODEL_DIR}"
cp "runs/train/${name}"/*.jpg "${MODEL_DIR}"
cp "runs/train/${name}"/*.txt "${MODEL_DIR}"
cp "runs/train/${name}"/*.yaml "${MODEL_DIR}"
mkdir -p "${MODEL_DIR}/weights"
best_weights="runs/train/${name}/weights/best.pt"
cp "${best_weights}" "${MODEL_DIR}/weights/" || true
...
また、正常にトレーニングできたことを確認するため、 test.py を使ってテストデータでの検証も続けて行います
...
python test.py \
--weights "${best_weights}" \
--data "${data}" \
--batch-size "${batch_size}" \
--img-size "${size}" \
--device "${device}" \
--task test \
--save-hybrid \
--name "${name}_test" || true
cp -r "runs/test/${name}_test" "${MODEL_DIR}/test" || true
...
トレーニング用データの準備
トレーニングするデータは Open Images Dataset から猫と犬の画像を取得します
データの取得には FiftyOne を使っています
...
CLASSES = ["Cat", "Dog"]
...
dataset = foz.load_zoo_dataset(
"open-images-v6",
split="validation",
label_types=["detections"],
classes=CLASSES,
max_samples=2000,
)
...
データは以下の件数用意できました
- トレーニング用: 1500
- 評価用: 200
- テスト用: 129
取得したデータを YOLOv5 形式でエクスポートし、圧縮して S3 にアップロードします
...
# YOLO V5 形式でエクスポート
train_dataset.export(
export_dir=f"{OUTPUT_DIR}",
dataset_type=DATASET_TYPE,
split="train",
classes=CLASSES,
)
val_dataset.export(
export_dir=f"{OUTPUT_DIR}",
dataset_type=DATASET_TYPE,
split="val",
classes=CLASSES,
)
test_dataset.export(
export_dir=f"{OUTPUT_DIR}",
dataset_type=DATASET_TYPE,
split="test",
classes=CLASSES,
)
...
トレーニングの実行
ECR リポジトリー、 S3 上のデータパスを指定してトレーニングを実行します
...
estimator = sagemaker.estimator.Estimator( # pylint: disable=c-extension-no-member
container,
role,
instance_count=1,
instance_type=parsed_args.instance_type,
max_run=(24 * 60 * 60),
volume_size=5,
output_path=s3_output_path,
base_job_name=parsed_args.job_name,
sagemaker_session=sagemaker_session,
)
...
今回はとりあえず 200 epoch でトレーニングを実行し、約7時間で終了しました
SageMaker から S3 上にアップロードされた学習結果 (model.tar.gz) をダウンロードして展開すると、最善のモデルファイル (weights/best.pt)、mAP などの推移グラフ (results.png)が取得できます
results.png
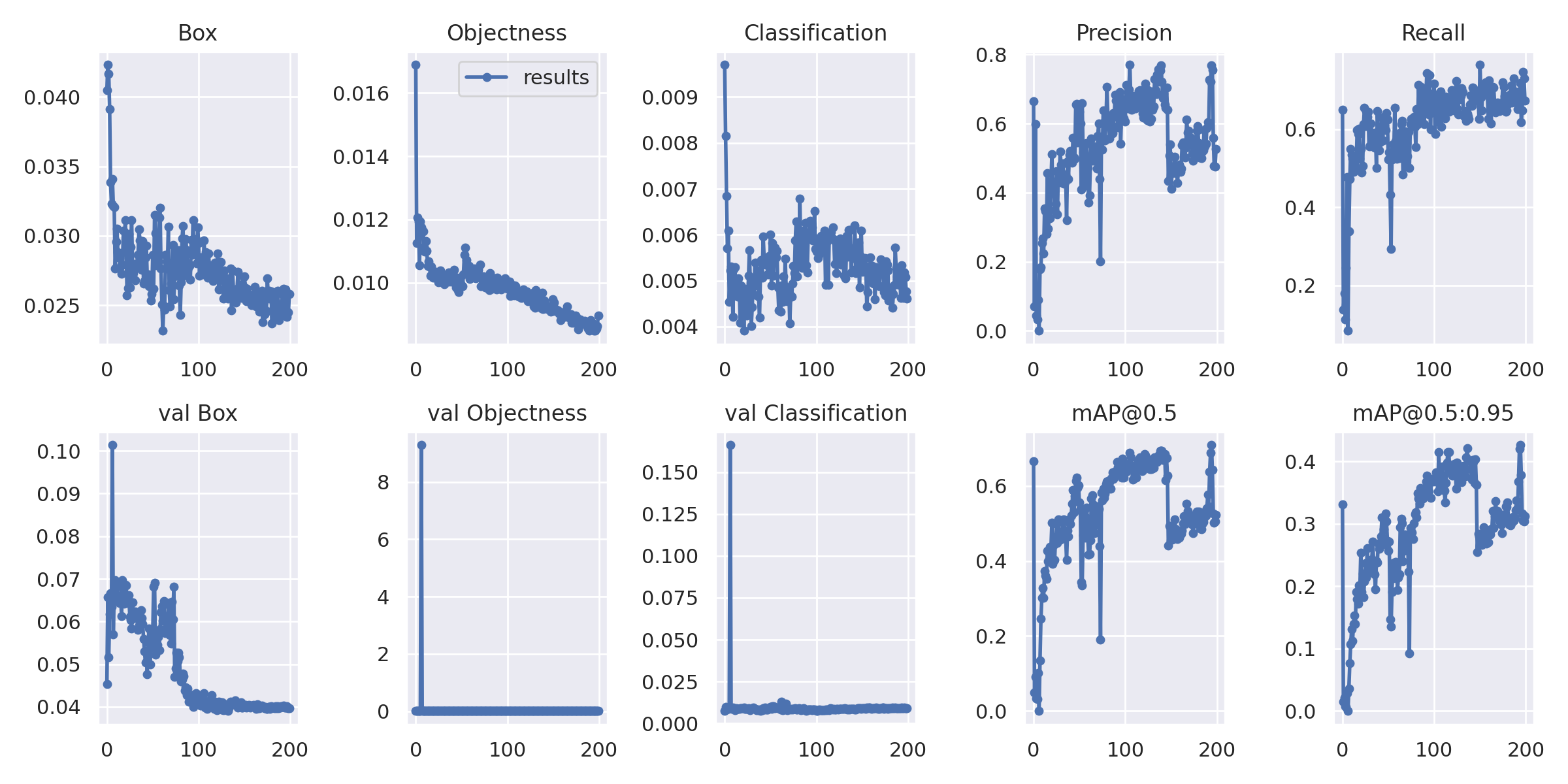
最善の結果は mAP@0.5 が 0.7468、mAP@0.5:0.95 が 0.5026 でした
学習データの量や epoch 数からすれば十分な数値ではないでしょうか
また、テストデータに対する推論結果(test/test_batch0_pred.jpg など)も入っています
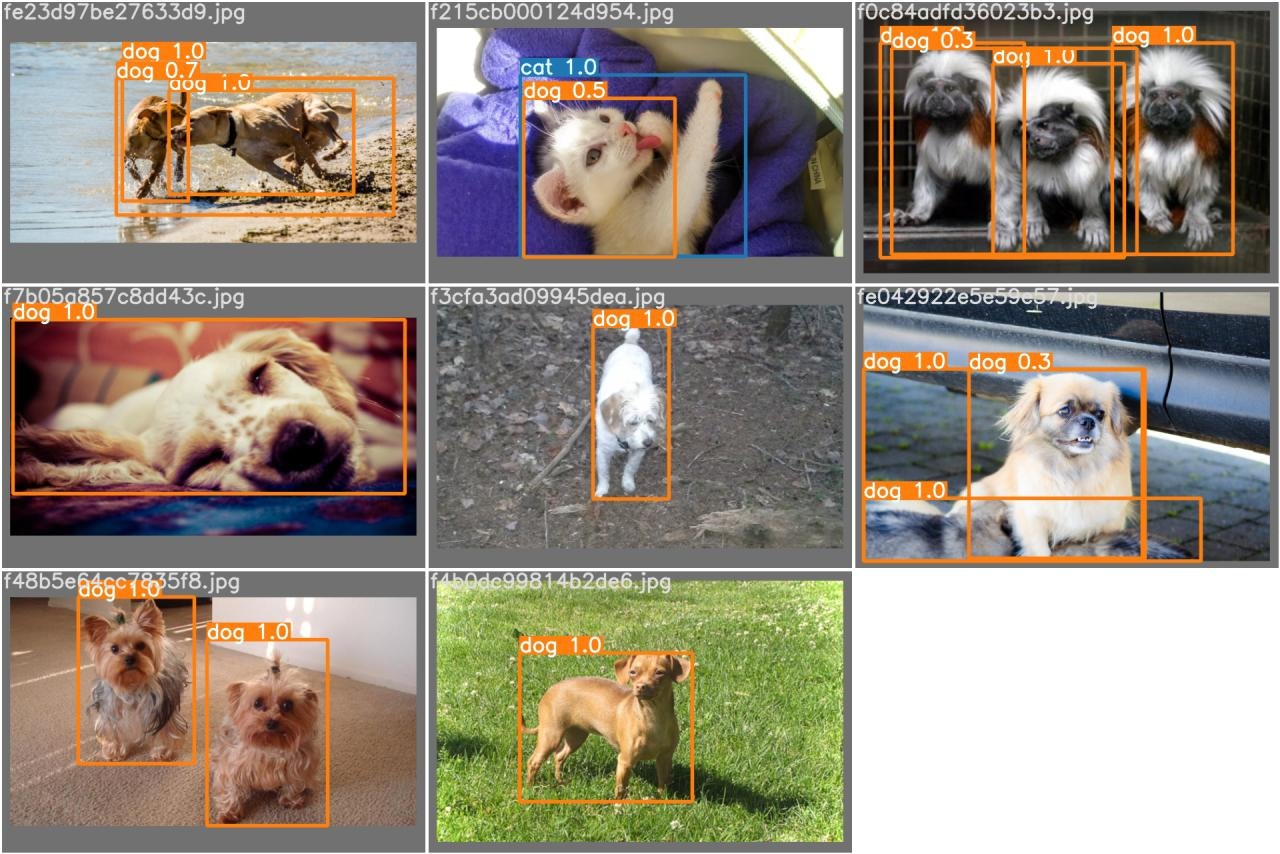


誤検出も含んでいますが、 それなりに学習できているようです
モデルの変換
Inferentia で推論を実行するためには、予めモデルを Inferentia 用に変換しておく必要があります
学習結果から取得したモデルファイルをローカルのコンテナ上で変換します
モデル変換用のコンテナでは以下のように torch-neuron をインストールします
...
RUN pip3 install --no-cache-dir --upgrade pip \
&& pip3 config set global.extra-index-url https://pip.repos.neuron.amazonaws.com \
&& pip3 install --no-cache-dir torch-neuron==1.8.1.2.3.0.0 neuron-cc[tensorflow]==1.11.4.0 "protobuf<4" \
&& pip3 install --no-cache-dir torchvision==0.9.1 --no-deps
...
変換用のコードの一部を抜粋します
...
# Update model
for k, m in model.named_modules():
m._non_persistent_buffers_set = ( # pylint: disable=protected-access
set()
) # pytorch 1.6.0 compatibility
if isinstance(m, Conv): # assign export-friendly activations
if isinstance(m.act, nn.Hardswish):
m.act = Hardswish()
elif isinstance(m.act, nn.SiLU):
m.act = SiLU()
...
def subgraph_builder_function(node):
"""サブグラフ"""
return "Detect" not in node.name
model_neuron = torch.neuron.trace(
model, image, subgraph_builder_function=subgraph_builder_function
)
model_neuron.save("/tmp/models/yolov7x_neuron.pt")
モデル更新部分は YOLOv7 公式の export.py を踏襲しています
重要なのは torch.neuron.trace を使っているところですね
通常の Tracing (TorchScript への変換)だと torch.jit.trace になっているところを torch.neuron.trace にすることで Inferentia 用モデルに変換できます
AWS Neuron の YOLOv4 の例を参考に実装しました
コンテナ上での変換が完了したら、変換前後のモデルファイルを S3 上にアップロードします
推論
推論用イメージのデプロイ
各種推論用イメージをデプロイします
CPU 用 (ml.m5.xlarge)
通常の CPU 用です
モデルファイルを torch.jit.trace で TorchScript に変換し、速度を向上させます
sagemaker/serve_cpu/app/model_loader.py
...
model = attempt_load(model_dir + "/yolov7x.pt", map_location=torch.device("cpu"))
...
dry_run_input = torch.zeros([1, 3, 640, 640])
...
model_jit = torch.jit.trace(model, dry_run_input, strict=False)
...
Graviton 用 (ml.c7g.xlarge)
PyTorch 2.0 では C7G インスタンス上での性能が向上しているようです
コンテナでは明示的に PyTorch の 2.0.1 と Torchvision の 0.15.2 をインストールします
sagemaker/serve_graviton/Dockerfile
...
RUN pip3 install --no-cache-dir --upgrade pip \
&& pip3 install --no-cache-dir \
torch==2.0.1 \
torchvision==0.15.2 \
...
torch.compile でモデルをコンパイルすることで、高速化できるはずです
sagemaker/serve_graviton/app/model_loader.py
...
model = attempt_load(model_dir + "/yolov7x.pt")
model_compiled = torch.compile(model)
...
GPU 用 (ml.g4dn.xlarge)
CUDA 用のコンテナを作成します
こちらも CUDA のイメージを元にします
FROM nvidia/cuda:11.2.1-cudnn8-devel
...
また、 GPU 用に torch.jit.trace で TorchScript に変換します
sagemaker/serve/app/model_loader.py
...
model = attempt_load(model_dir + "/yolov7x.pt", map_location=torch.device(device))
...
dry_run_input = torch.zeros([1, 3, 640, 640]).to(torch.device(device))
...
model_jit = torch.jit.trace(model, dry_run_input, strict=False)
...
Inferentia 用 (ml.inf1.xlarge)
Inferentia 用に torch-neuron をインストールしたコンテナを作成します
sagemaker/serve_inferentia/Dockerfile
RUN pip3 install --no-cache-dir --upgrade pip \
&& pip3 config set global.extra-index-url https://pip.repos.neuron.amazonaws.com \
&& pip3 install --no-cache-dir torch-neuron==1.8.1.2.3.0.0 "protobuf<4" \
&& pip3 install --no-cache-dir torchvision==0.9.1 --no-deps
また、ローカルで Inferentia 用に変換したモデルを使用して推論します
sagemaker/serve_inferentia/app/model_loader.py
...
model_neuron = torch.jit.load(model_dir + "/yolov7x_neuron.pt")
...
エンドポイントの作成
各 ECR リポジトリー、モデルファイルの S3 パスを指定してモデル、エンドポイントコンフィグ、エンドポイントを作成します
推論の実行
テスト用データを使用して推論を実行します
事前に準備していた 129 枚のテスト用画像を1枚ずつ SageMaker に直接リクエストして結果を取得します
...
begin_time = datetime.now()
response = CLIENT.invoke_endpoint(
EndpointName=args.endpoint,
Body=payload,
CustomAttributes=attributes,
ContentType="image/jpeg",
Accept="application/json",
)
logger.info("%s Response time: %s", img_path, datetime.now() - begin_time)
...
(実運用する場合は Lambda や API Gateway などを前に配置することになります)
ちなみに、どのエンドポイントでも検出結果はほぼ同じでした
(Inferentia が僅かに違います)
-
CPU 用 (ml.m5.xlarge)
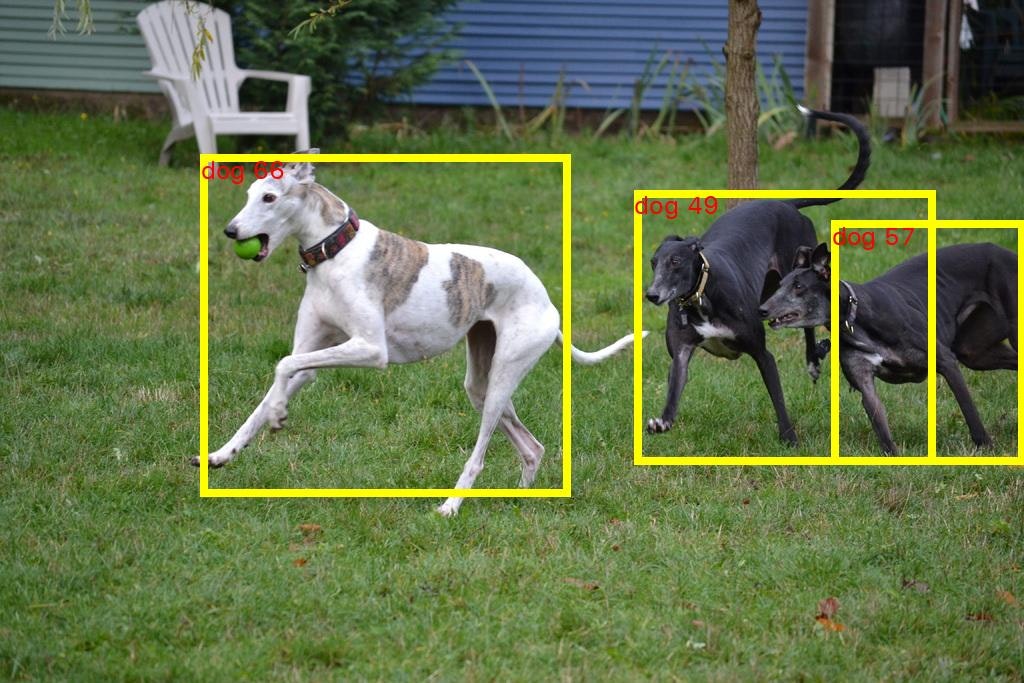
-
Graviton 用 (ml.c7g.xlarge)
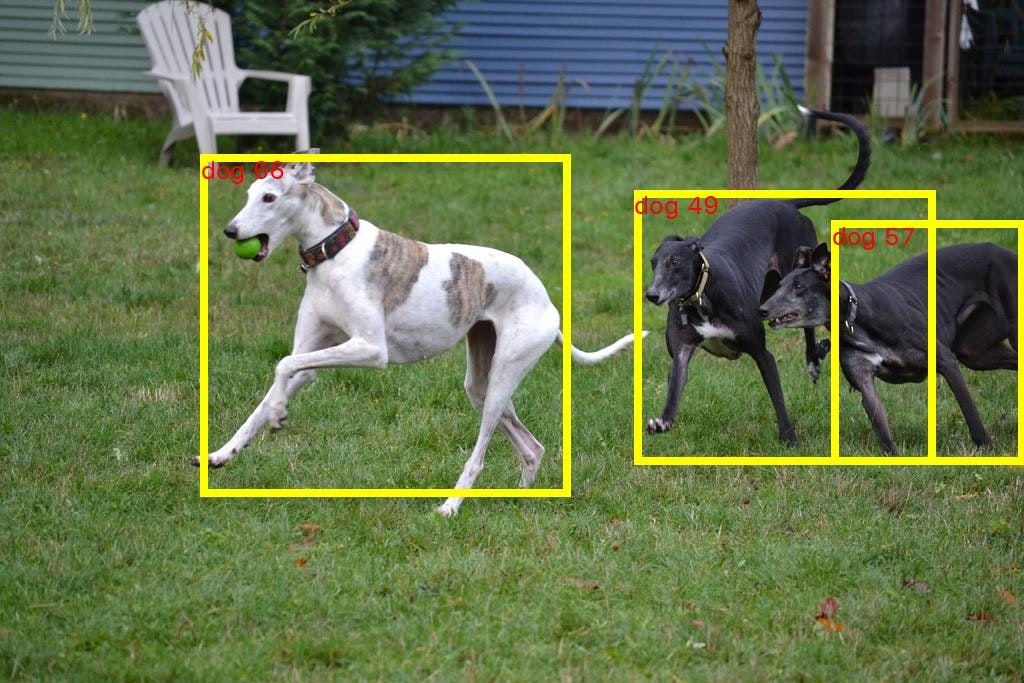
-
GPU 用 (ml.g4dn.xlarge)
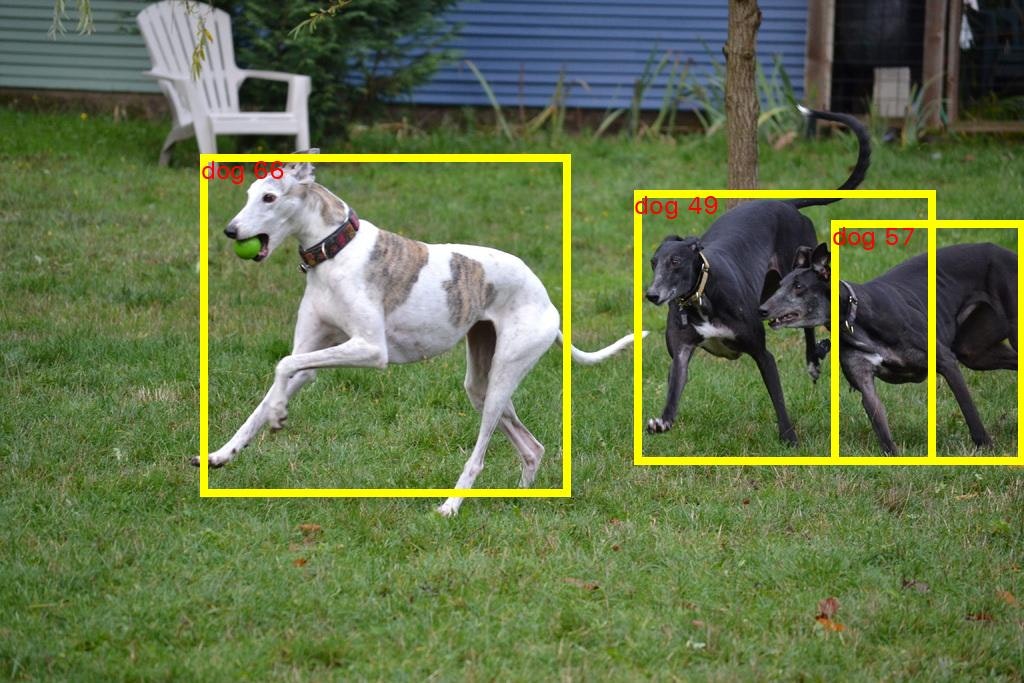
-
Inferentia 用 (ml.inf1.xlarge)
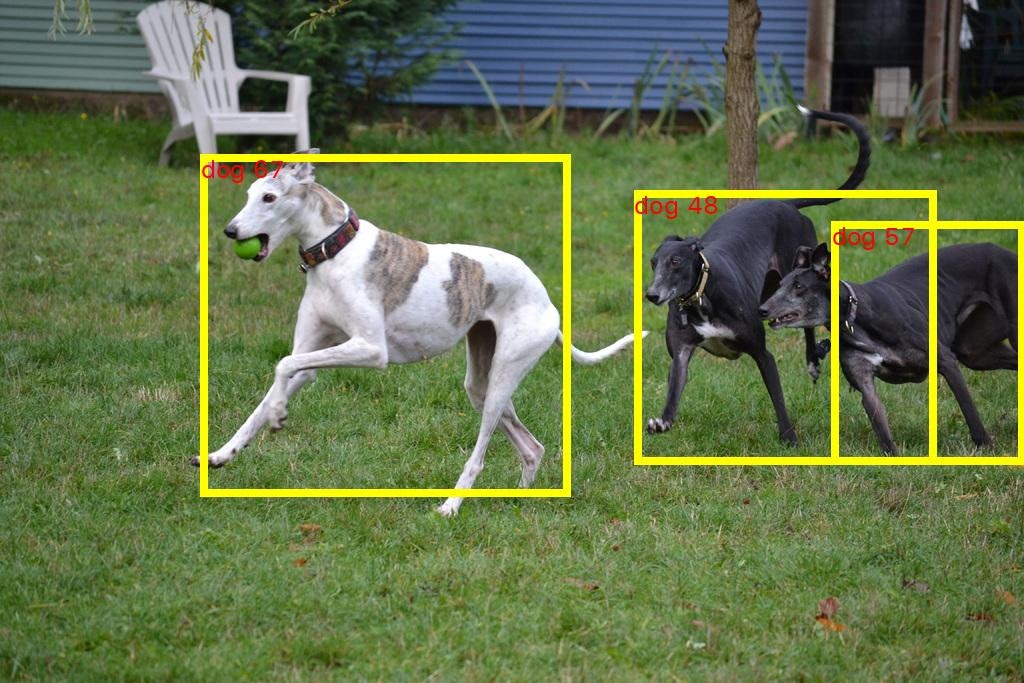
SageMaker のログに「推論単体の時間」「NMS単体の時間」を出すようにしているので、この時間を取得、集計します
また、SageMaker の呼び出しからレスポンスが返ってくるまでの時間も取得、集計します
実行結果
各インスタンスタイプで 129 枚の画像に対して推論した結果を平均すると、以下のようになりました
| インスタンスタイプ | アーキテクチャ | 料金($/hours) | 推論時間 (sec) | NMS 実行時間 (sec) | レスポンス時間 (sec) |
|---|---|---|---|---|---|
| ml.m5.xlarge | Intel CPU | 0.204 | 1.542272 | 0.000658 | 1.828900 |
| ml.c7g.xlarge | AWS Graviton3 | 0.174 | 1.757631 | 0.000744 | 2.007605 |
| ml.g4dn.xlarge | NVIDIA GPU | 0.736 | 0.007493 | 0.036055 | 0.274186 |
| ml.inf1.xlarge | Inferentia | 0.297 | 0.045719 | 0.000636 | 0.276466 |
各時間は以下の期間を計測しています
- 推論時間: SageMaker 上の推論単体にかかった時間
- NMS 実行時間: 推論後の Non-Maximum Suppression にかかった時間
- レスポンス時間: ローカル側で SageMaker エンドポイントの呼び出しから推論結果が返ってくるまでの時間
また、各インスタンスタイプは以下の条件下で計測しています
- ml.m5.xlarge:
torch.jit.traceで TorchScript に変換したモデルで推論 - ml.c7g.xlarge:
torch.compileでコンパイルしたモデルで推論 - ml.g4dn.xlarge:
torch.jit.traceで GPU 用 TorchScript に変換したモデルで推論 - ml.inf1.xlarge:
torch.neuron.traceで Inferentia 用に変換したモデルで推論
料金では ml.c7g.xlarge が最も安いですが、推論時間は最も長くなっています
YOLOv7 では torch.compile の恩恵が得られなかったのか、もしくは私の実装が悪かったのかもしれません
ml.m5.xlarge と ml.c7g.xlarge はいずれもレスポンス時間が 2 秒程度になっているため、速度が要求されたり、大量リクエストがある場合には使えないかもしれません
ただし、あまり速度を要求されない API ではコストパフォーマンス的に採用することがあると思います
ml.g4dn.xlarge は GPU なので、圧倒的に推論時間が短くなっています
7.5 msec なので、 YOLOv7x の公式パフォーマンスよりも速い結果です
ただし、 NMS に推論以上の時間がかかっています
これは、 YOLOv7 の NMS の実装が高速化されたものではないからです
高速化した NMS に変更すればより改善される可能性があります
ml.inf1.xlarge はレスポンス時間が 0.27 sec で ml.g4dn.xlarge とほぼ同じになっています
推論時間が十分に高速であり、 NMS が圧倒的に速く実行されています
レスポンス時間がほぼ同等で料金は6割削減できるので、 ml.inf1.xlarge のコストパフォーマンスは非常に高いと言えるでしょう
環境の削除
作成したものを削除します
- SageMaker のエンドポイント、エンドポイントコンフィグ、モデル
- ECR のリポジトリー
- IAM ロール
特に SageMaker のエンドポイントは起動していると課金され続けるので忘れず削除しましょう
おわりに
Inferentia を利用することで、速く安くリアルタイム推論ができることを確認できました
事前に変換を掛けておくだけで、精度は落とさず、 GPU に比肩する速度、 GPU よりも6割少ない運用コストが実現できるので、今後も積極的に使っていきたいと思います
Inferencia2 が SageMaker に対応すれば、更に高速化、低価格化が期待できそうです