はじめに
以下のような機会があり、 Swift script で CoreML のモデルを動かしてみました
- TuriCreate で学習したモデルを動かして精度検証したい
- XCode でビルドせずに、気軽に動かしたい
コードを整理して GitHub に載せたので、 Qiita にも初記事を投稿してみたいと思います
そんなに新しい情報はありませんが、 GitHub には Apple 公式の YOLOv3 を使った例を掲載しましたので、 CoreML をとりあえず動かしてみたい方は参考にしてください
XCode でプロジェクトを作らないため、1ファイルに全て書いており、見にくいですがご了承下さい
実行環境
- macOS Big Sur 11.3.1
- Swift 5.4
スクリプトの使い方
モデルのコンパイル方法
.mlmodel ファイルのままでは実行できないので、先にモデルをコンパイルします
実行すると、 .mlmodel のファイルが .mlmodelc のディレクトリーになります
こちらの記事を参考に実装しました
- 引数
- コンパイル前の MLModel のパス
swift CompileMLModel.swift YOLOv3.mlmodel
物体検出の実行方法
以下のように実行すると、物体検出の結果を表示します
-
引数
- コンパイル済 MLModel のパス
- 物体検出したい画像ファイルのパス
-
結果の項目
- ラベル
- スコア(0〜1)
- 座標情報(それぞれ画像全体の幅・高さを1としたときの比、左上原点)
- 左上X座標
- 左上Y座標
- 幅
- 高さ
$ swift DetectObject.swift YOLOv3.mlmodelc chair.png
chair 0.99625164 (0.19140625, 0.01318359375, 0.763671875, 0.97265625)
コードの内容・解説
coremlcompiler
XCode で開発する場合は TuriCreate で出力した mlmodel ファイルをそのままプロジェクトに入れれば、勝手にコンパイルしてくれます
Swift script から呼んだり、 XCode の Playground から呼び出す場合は、自分でコンパイルしてあげる必要があります
実は Swift で実装しなくても、 coremlcompiler を使って以下のようにコンパイルできます
実装した後に知りました
xcrun coremlcompiler compile YOLOv3.mlmodel .
コマンドライン引数のパース
コマンドライン引数から .mlmodelc のディレクトリーパスを取得します
let modelPath = CommandLine.arguments.dropFirst().first
モデルの読み込み
引数から取得したパスを指定して、モデルを読み込みます(エラー処理は省きました)
let modelUrl = URL(fileURLWithPath: modelPath)
guard let yoloModel = try? MLModel(contentsOf: modelUrl),
let yoloMLModel = try? VNCoreMLModel(for: yoloModel) else { return }
リクエストの準備
imageCropAndScaleOption は .scaleFill を指定します
CoreML で画像をモデルに渡す際に、モデルの入力サイズに合わせてスケーリングするのですが、
その際にアスペクト比を保持するか、中央を切り出すか、などの選択をしています
詳細は Apple の公式が分かりやすいです
self.yoloRequest = VNCoreMLRequest(model: yoloMLModel) { [weak self] request, error in
self?.detected(request: request, error: error)
}
self.yoloRequest?.imageCropAndScaleOption = .scaleFill
リクエストの実行
iOS ではなく macOS で動かしているため、入力の画像は NSImage になっています
VNImageRequestHandler に渡すためには CGImage や CIImage などにする必要があるため、変換します
func detect(_ image: NSImage) {
guard let cgImage = image.cgImage(forProposedRect: nil, context: nil, hints: nil),
let yoloRequest = self.yoloRequest else { return }
let handler = VNImageRequestHandler(cgImage: cgImage)
try? handler.perform([yoloRequest])
}
結果の表示
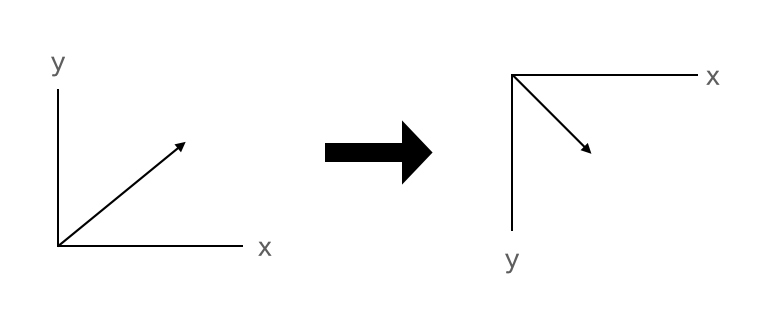
CoreML の座標系は左下が原点になっています
画像処理で一般的な左上原点の座標系に変換するため、 boundingBox を上下反転 .flipVirtical() します
guard let observations = request.results as? [VNRecognizedObjectObservation] else { return }
observations.forEach { observation in
if let topLabel = observation.topLabel {
print(topLabel.identifier, topLabel.confidence,
observation.boundingBox.flipVertical())
}
}
.topLabel や .flipVertical() は extension で実装しました
extension VNRecognizedObjectObservation {
var topLabel: VNClassificationObservation? {
self.labels.max { $0.confidence < $1.confidence }
}
}
extension CGRect {
func flipVertical(size: CGSize = CGSize(width: 1.0, height: 1.0)) -> CGRect {
CGRect(x: self.minX, y: size.height - self.maxY,
width: self.width, height: self.height)
}
}
あとはこれを応用して、大量画像の検出結果をJSONに出力したり、画像にプロットしたりすれば精度検証ができるという寸法です