はじめに
Elixir で画像を並列処理してみます
この記事は @zacky1972 さんが ElixirConf US 2022 で発表した内容の一部を Livebook 上で実行したものです
ElixirConf US 2022 の @zacky1972 さんの発表動画はこちら
参考にした @zacky1972 さんの Gist はこちら
実行したノートブックはこちら
前回記事の画像分割はこちら
実行環境
以下のリポジトリーのコンテナ上で実行しています
準備
ノートブックを起動して、以下のコードを実行してセットアップします
Mix.install([
{:download, "~> 0.0.4"},
{:evision, "~> 0.1"},
{:kino, "~> 0.7"},
{:nx, "~> 0.4"},
{:flow, "~> 1.2"},
{:benchee, "~> 1.1"}
])
セットアップ対象
- download: データダウンロード
- evision: 画像処理
- kino: 出力可視化
- nx: 行列演算
- flow: 並列処理
- benchee: ベンチマーク
※ 2022/11/24 現在、 evision 最新の 0.1.19 はインストール中エラーになるため、 0.1.18 を指定しています
※ 2022/11/25 対応してくれました 0.1.20 でインストールできるようになりました
処理する画像をダウンロードしてきます
# 再実行時、Download.from()でeexistエラーになるのを防止
File.rm("Lenna_%28test_image%29.png")
lenna =
Download.from("https://upload.wikimedia.org/wikipedia/en/7/7d/Lenna_%28test_image%29.png")
|> elem(1)
画像を読み込みます
mat = Evision.imread(lenna)
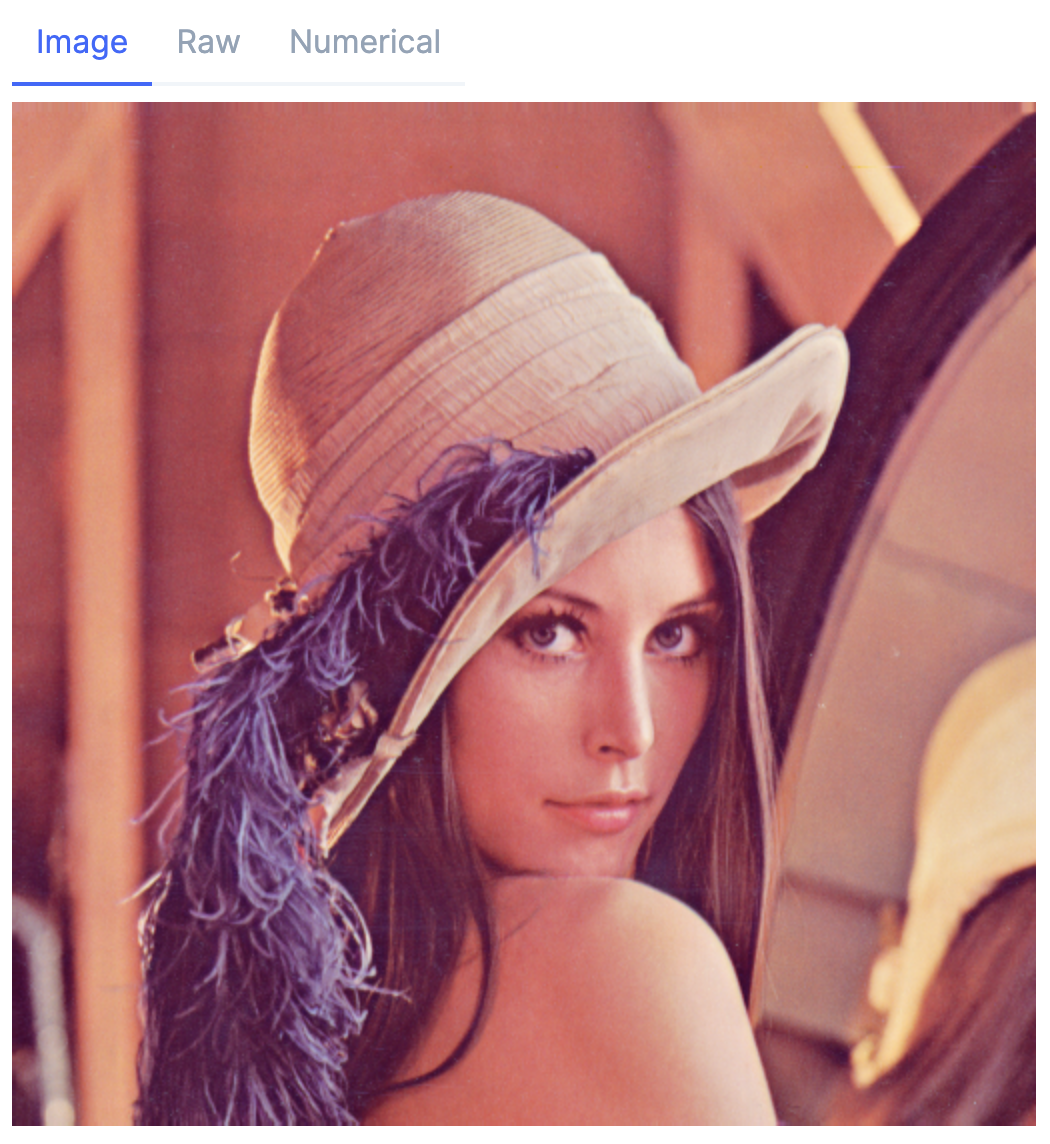
単体処理
画像1枚に対して実行する処理を定義します
proc = fn mat ->
mat
# しきい値処理
|> Evision.threshold(127, 255, Evision.Constant.cv_THRESH_BINARY())
|> elem(1)
# 四角形を3個描画
|> Evision.rectangle({50, 10}, {125, 60}, {255, 0, 0})
|> Evision.rectangle({250, 60}, {325, 110}, {0, 255, 0}, thickness: -1)
|> Evision.rectangle({150, 120}, {225, 320}, {0, 0, 255},
thickness: 5,
lineType: Evision.Constant.cv_LINE_4()
)
# 楕円を描画
|> Evision.ellipse({300, 300}, {100, 200}, 30, 0, 360, {255, 255, 0}, thickness: 3)
end
画像処理を実行します
proc.(mat)

画像をコピー
並列処理を実行するために、画像を128枚コピーしておきます
src_file_ext = Path.extname(lenna)
src_file_basename = Path.basename(lenna, src_file_ext)
src_files =
Stream.unfold(0, fn counter -> {counter, counter + 1} end)
|> Stream.map(&"#{src_file_basename}_#{&1}#{src_file_ext}")
# コピー枚数
copy_count = 128
src_file_paths =
mat
|> List.duplicate(copy_count)
|> Enum.zip(src_files)
|> Enum.map(fn {img, dst_file} ->
Evision.imwrite(dst_file, img)
dst_file
end)

コピーしたものを表示してみます
# コピーしたファイル先頭2件を読込
src_file_paths
|> Enum.slice(0..1)
|> IO.inspect()
|> Enum.map(&Evision.imread(&1))
|> Enum.map(&Kino.render(&1))

逐次処理
並列の前に逐次処理を実行してみます
まず、処理対象のファイル一覧を準備します
stream =
# 存在するファイルを取得
Stream.unfold(0, fn counter -> {counter, counter + 1} end)
|> Stream.map(&{&1, "#{src_file_basename}_#{&1}#{src_file_ext}"})
|> Stream.take_while(fn {_, filename} -> File.exists?(filename) end)

Enum.map で各画像に対して逐次処理します
# Enum.map で処理
enum_proc = fn stream ->
stream
|> Enum.map(fn {_, filename} ->
{
filename,
filename |> Evision.imread() |> proc.()
}
end)
end
imgs_tuple = enum_proc.(stream)
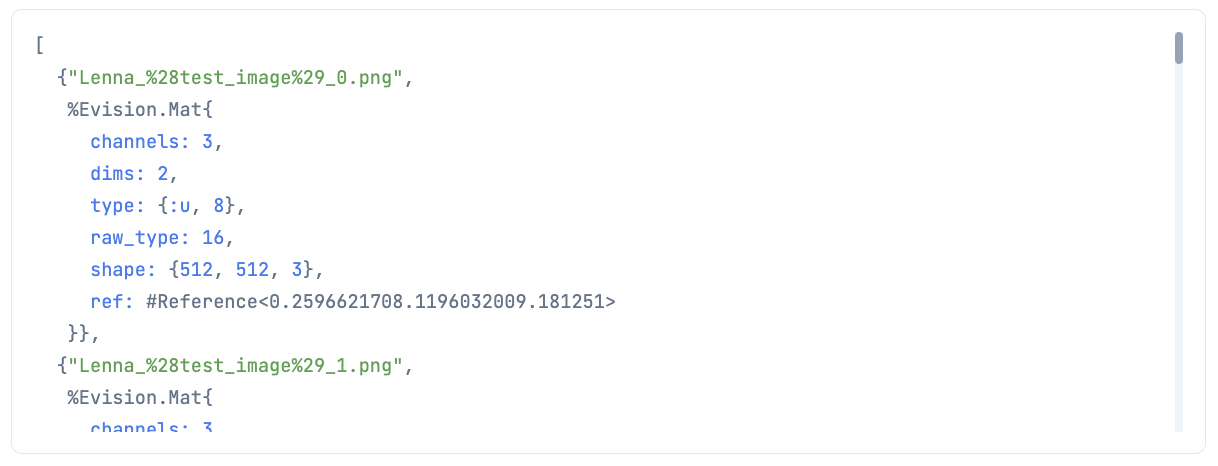
処理結果の先頭2件を表示してみます
# 先頭2件を表示
imgs_tuple
|> Enum.slice(0..1)
|> Enum.map(fn {filename, img} ->
IO.inspect(filename)
Kino.render(img)
end)
ちゃんと各画像に対して処理できています
並列処理
続いて並列処理を定義します
並列処理では Flow というモジュールを使用します
Flow.from_enumerable で、列挙型の入力を Flow に変換します
stages が大きいほど並列数が増えます
Enum.map の代わりに Flow.map を使って個別の処理を実行します
ここまでしか書いていないと Flow が定義されただけ(どのような処理を並列実行するか決めただけ)で実行されないので、
Enum.to_list() を入れて実行結果を配列にします
# Flow.map で処理
flow_proc = fn stream, stages ->
stream
|> Flow.from_enumerable(stages: stages, max_demand: 1)
|> Flow.map(fn {_, filename} ->
{
filename,
filename |> Evision.imread() |> proc.()
}
end)
|> Enum.to_list()
end
stages=4 で実行してみます
imgs_tuple = flow_proc.(stream, 4)
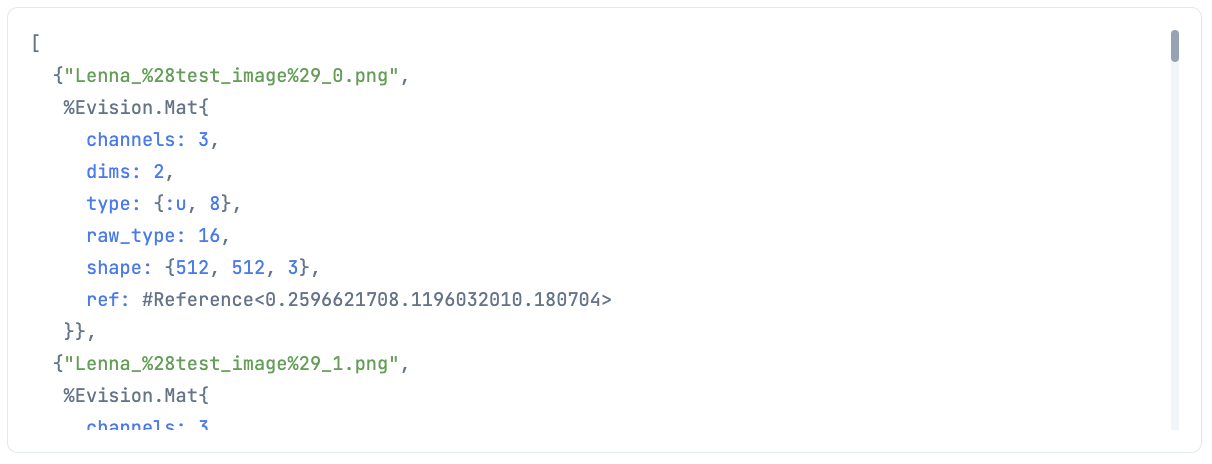
処理結果の先頭2件を表示してみます
# 先頭2件を表示
imgs_tuple
|> Enum.slice(0..1)
|> Enum.map(fn {filename, img} ->
IO.inspect(filename)
Kino.render(img)
end)
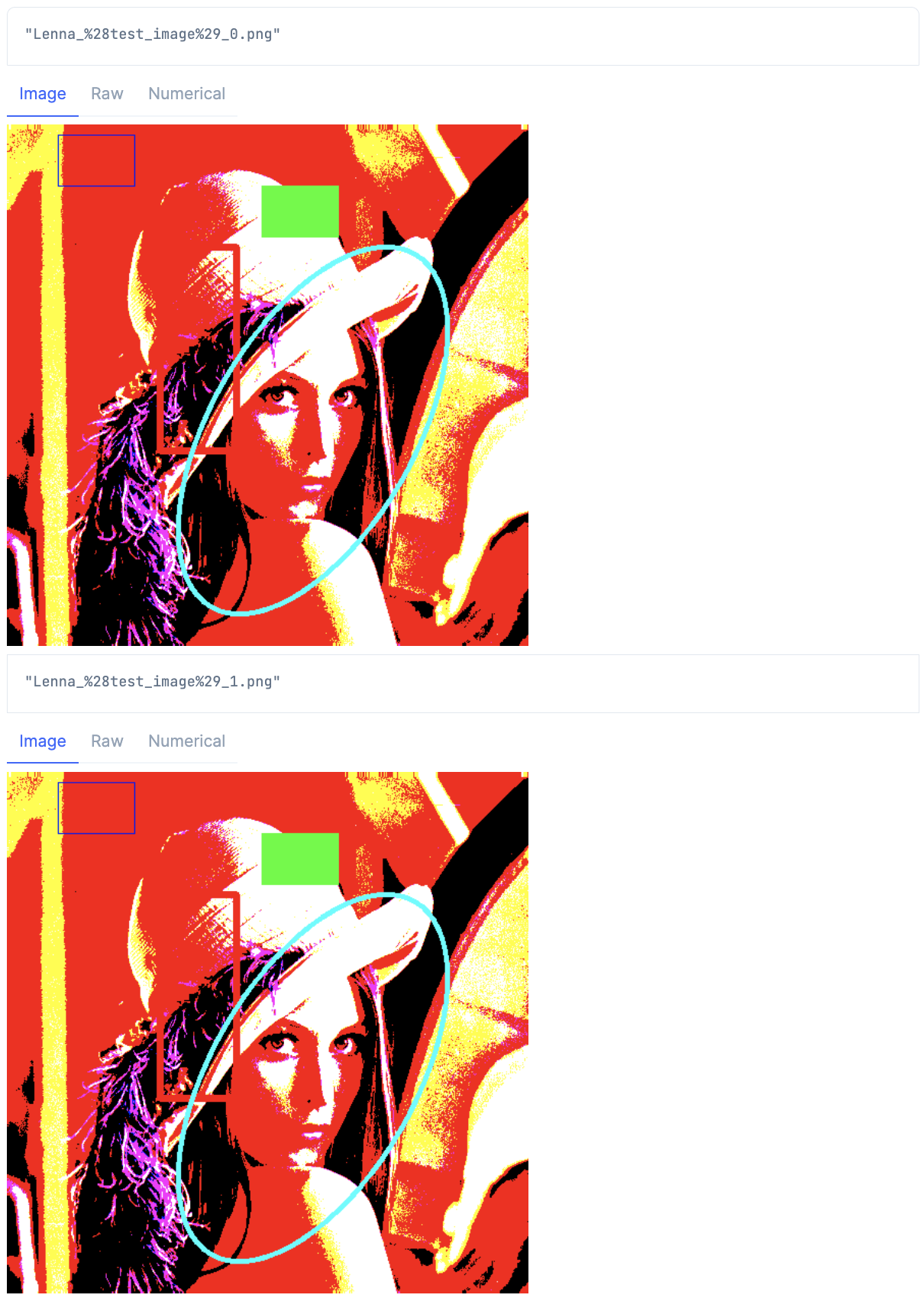
こちらもちゃんと各画像に対して処理できています
速度比較
単に実行しただけでは並列処理を実感できないので、逐次実行の場合と比較してみます
また、ステージ数による速度の違いも見てみます
Benchee.run(%{
"enum" => fn -> enum_proc.(stream) end,
"flow 1" => fn -> flow_proc.(stream, 1) end,
"flow 2" => fn -> flow_proc.(stream, 2) end,
"flow 4" => fn -> flow_proc.(stream, 4) end,
"flow 8" => fn -> flow_proc.(stream, 8) end
})
私の環境での実行結果は以下のようになりました
Operating System: Linux
CPU Information: 06
Number of Available Cores: 6
Available memory: 9.73 GB
Elixir 1.14.0
Erlang 24.3.4.2
Benchmark suite executing with the following configuration:
warmup: 2 s
time: 5 s
memory time: 0 ns
reduction time: 0 ns
parallel: 1
inputs: none specified
Estimated total run time: 35 s
Benchmarking enum ...
Benchmarking flow 1 ...
Benchmarking flow 2 ...
Benchmarking flow 4 ...
Benchmarking flow 8 ...
Name ips average deviation median 99th %
flow 4 1.12 0.89 s ±8.37% 0.87 s 1.02 s
flow 2 1.09 0.92 s ±4.87% 0.90 s 0.99 s
flow 8 0.96 1.04 s ±6.99% 1.02 s 1.16 s
enum 0.67 1.49 s ±2.46% 1.49 s 1.53 s
flow 1 0.67 1.50 s ±2.24% 1.50 s 1.53 s
Comparison:
flow 4 1.12
flow 2 1.09 - 1.04x slower +0.0312 s
flow 8 0.96 - 1.17x slower +0.148 s
enum 0.67 - 1.68x slower +0.60 s
flow 1 0.67 - 1.68x slower +0.61 s
stages=1 のときは並列数1なので、 Enum とほぼ変わりません
stages=2、 stages=4 と速くなり、 stages=8 で遅くなっています
コア数やメモリサイズ、処理の重さなどでこの辺りは変動すると思いますが、
私の環境では、この画像処理は stages=4 が最適、ということになります
Google Colab で実行した場合
ちなみに、以前の記事と同じ方法で Google Colab 上で実行した場合は以下のようになりました
Benchee.run(%{
"enum" => fn -> enum_proc.(stream) end,
"flow 1" => fn -> flow_proc.(stream, 1) end,
"flow 2" => fn -> flow_proc.(stream, 2) end,
"flow 4" => fn -> flow_proc.(stream, 4) end,
"flow 8" => fn -> flow_proc.(stream, 8) end,
"flow 16" => fn -> flow_proc.(stream,16) end,
"flow 32" => fn -> flow_proc.(stream,32) end
})
Operating System: Linux
CPU Information: Intel(R) Xeon(R) CPU @ 2.20GHz
Number of Available Cores: 2
Available memory: 12.68 GB
Elixir 1.13.4
Erlang 25.0.4
Benchmark suite executing with the following configuration:
warmup: 2 s
time: 5 s
memory time: 0 ns
reduction time: 0 ns
parallel: 1
inputs: none specified
Estimated total run time: 49 s
Benchmarking enum ...
Benchmarking flow 1 ...
Benchmarking flow 2 ...
Benchmarking flow 4 ...
Benchmarking flow 8 ...
Benchmarking flow 16 ...
Benchmarking flow 32 ...
Name ips average deviation median 99th %
flow 8 1.48 673.49 ms ±1.04% 670.73 ms 689.20 ms
flow 16 1.46 684.81 ms ±1.23% 686.70 ms 696.95 ms
flow 32 1.44 693.27 ms ±1.75% 692.29 ms 710.05 ms
flow 4 1.44 694.37 ms ±2.30% 694.82 ms 727.84 ms
flow 2 1.41 708.69 ms ±1.73% 708.33 ms 725.59 ms
flow 1 1.04 964.76 ms ±0.99% 966.07 ms 975.51 ms
enum 0.94 1068.06 ms ±17.27% 998.22 ms 1390.78 ms
Comparison:
flow 8 1.48
flow 16 1.46 - 1.02x slower +11.32 ms
flow 32 1.44 - 1.03x slower +19.78 ms
flow 4 1.44 - 1.03x slower +20.89 ms
flow 2 1.41 - 1.05x slower +35.20 ms
flow 1 1.04 - 1.43x slower +291.27 ms
enum 0.94 - 1.59x slower +394.58 ms
そんなに早いというわけでもないですね、、、
今度 Nx を使って同じことをやってみましょう
まとめ
並列処理で速度向上が確認できました
次は複数ノードで分散処理を実行してみます