はじめに
Livebook から AWS のサービスを操作するシリーズです
今回は Amazon DynamoDB を操作します
Amazon DynamoDB は NoSQL データベースサービスで、超格安でデータベースを運用できます
フルマネージドでサーバレスなので、環境構築とかは気にせず、使った分だけ料金を払えばOKです
今回はテーブル作成・削除とデータ追加、データ取得を Livebook からやってみます
実装したノートブックはこちら
事前作業
AWS のアカンウトと、 DynamoDB の権限を持った IAM ユーザーと、その認証情報(ACCESS_KEY_ID と SECRET_ACCESS_KEY)が必要です
実行環境
Livebook 0.8.0 の Docker イメージを元にしたコンテナで動かしました
コンテナ定義はこちらを参照
セットアップ
ex_aws_dynamo を中心に、必要なモジュールをインストールします
また、データ分析のために Explorer もインストールします
Mix.install([
{:ex_aws, "~> 2.0"},
{:ex_aws_dynamo, "~> 4.2"},
{:poison, "~> 5.0"},
{:hackney, "~> 1.18"},
{:sweet_xml, "~> 0.7"},
{:explorer, "~> 0.4"},
{:kino, "~> 0.8"}
])
エイリアス等の準備をします
alias ExAws.Dynamo
alias Explorer.DataFrame
alias Explorer.Series
require Explorer.DataFrame
認証
入力エリアを用意し、そこに IAM ユーザーの認証情報を入力します
ACCESS_KEY_ID と SECRET_ACCESS_KEY は秘密情報なので、値が見えないように Kino.Input.password を使います
access_key_id_input = Kino.Input.password("ACCESS_KEY_ID")
secret_access_key_input = Kino.Input.password("SECRET_ACCESS_KEY")
操作対象にする DynamoDB テーブルのリージョンもここで入力しておきましょう
region_input = Kino.Input.text("REGION")
各認証情報を ExAws に渡すためにまとめておきます
秘密情報が実行結果に現れないよう、セルの最後には "dummy" を入れておきましょう
auth_config = [
access_key_id: Kino.Input.read(access_key_id_input),
secret_access_key: Kino.Input.read(secret_access_key_input),
region: Kino.Input.read(region_input)
]
"dummy"
テーブル作成
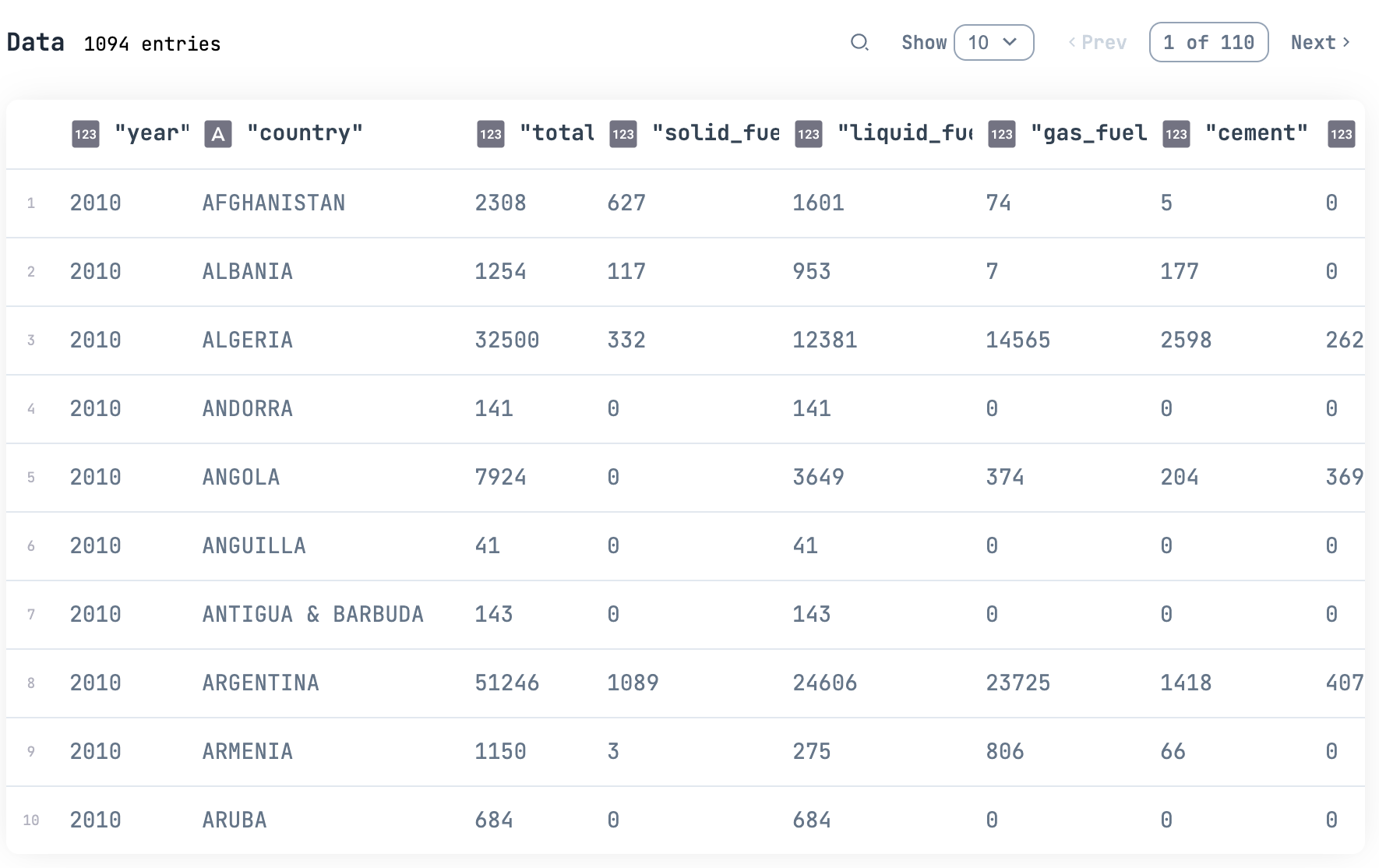
今回は Explorer から化石燃料データセットを取得し、そのデータを DynamoDB に入れてみます
df = Explorer.Datasets.fossil_fuels()
df
|> Kino.DataTable.new()
作成するテーブルの名前を定義しておきます
table_name = "fossil_fuels"
テーブルのキーを定義します
DynamoDB においては RDB と違い、キー項目だけ ちゃんと 定義しておけば、あとはどんな項目が来てもデータを追加できます
この ちゃんと が難しいわけですが、、、
DynamoDB のキーについては以下の記事を参照してください
非常にややこしいですが、今回は深いことは考えず、 fossil_fuels データセットは年毎、国毎の化石燃料データなので、 year をハッシュキー、 country をレンジキーにします
key_schema = [
year: :hash,
country: :range
]
それぞれの型も指定します
key_types = [
year: :number,
country: :string
]
テーブルの性能を指定しておきます
これもかなり分かりにくいですが、オンデマンドキャパシティーモードにしておけば、超大量データを高速に書いたり読んだりしていても、基本的にエラーになりません
その代わり、料金は青天井で、読み書きの回数に応じてどんどん高くなります
どれだけのリクエストが来るか想定できない場合に使います
それに対してプロビジョニング済みキャパシティーモードはある程度時間あたりのリクエスト数が想定できる場合に使用します
読み書きにキャパシティーユニットという数値を指定しておけば、それに応じた時間あたりの料金になります
そして読み書きそれぞれ 25 キャパシティーユニットまでは無料利用枠が適用されます
小規模データベースだったり、一時的に使うだけのデータベースならほぼ無料で使えてしまいます
というわけで、今回は読み書きそれぞれ 1 のキャパシティーユニットでテーブルを作成します
read_capacity = 1
write_capacity = 1
Dynamo.create_table でテーブルを作成します
table_name
|> Dynamo.create_table(key_schema, key_types, read_capacity, write_capacity)
|> ExAws.request(auth_config)
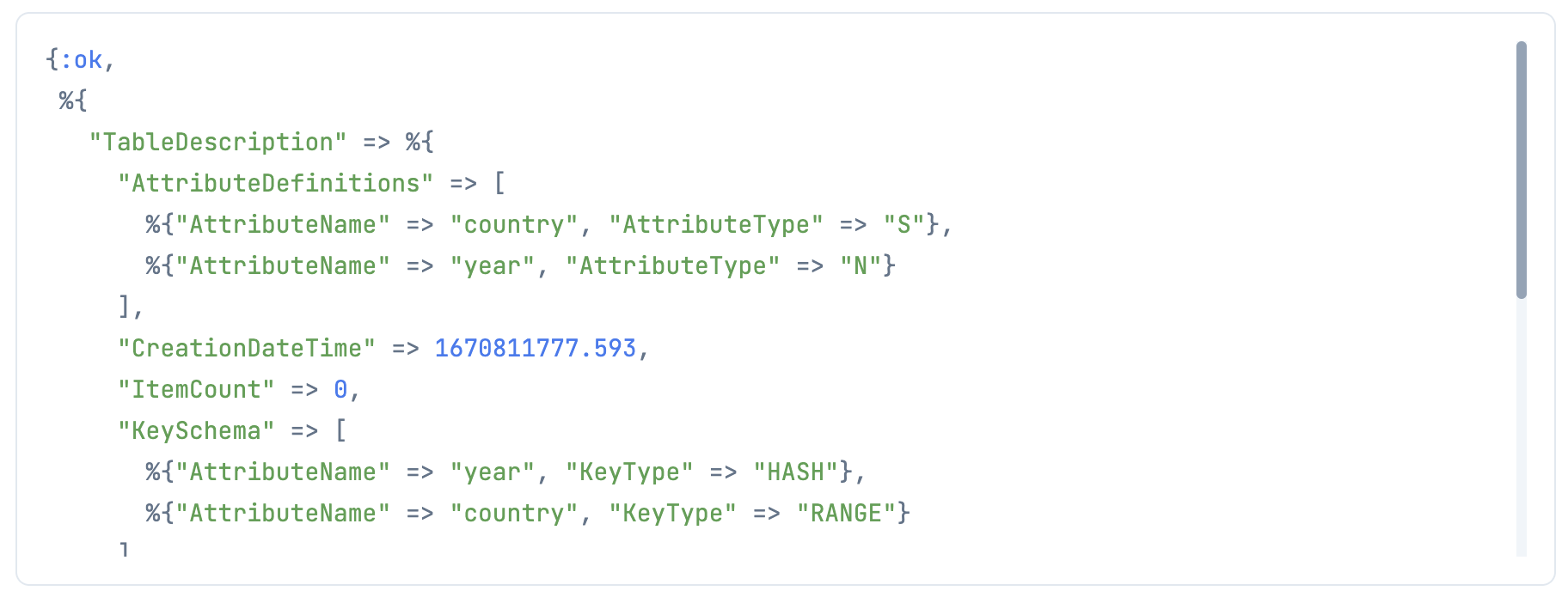
Dynamo.list_tables で作成したテーブルを確認してみましょう
Dynamo.list_tables()
|> ExAws.request(auth_config)

データ追加
まず一つだけデータを追加してみましょう
データフレームから1件データを取得します
item =
df
|> DataFrame.to_rows()
|> Enum.at(0)
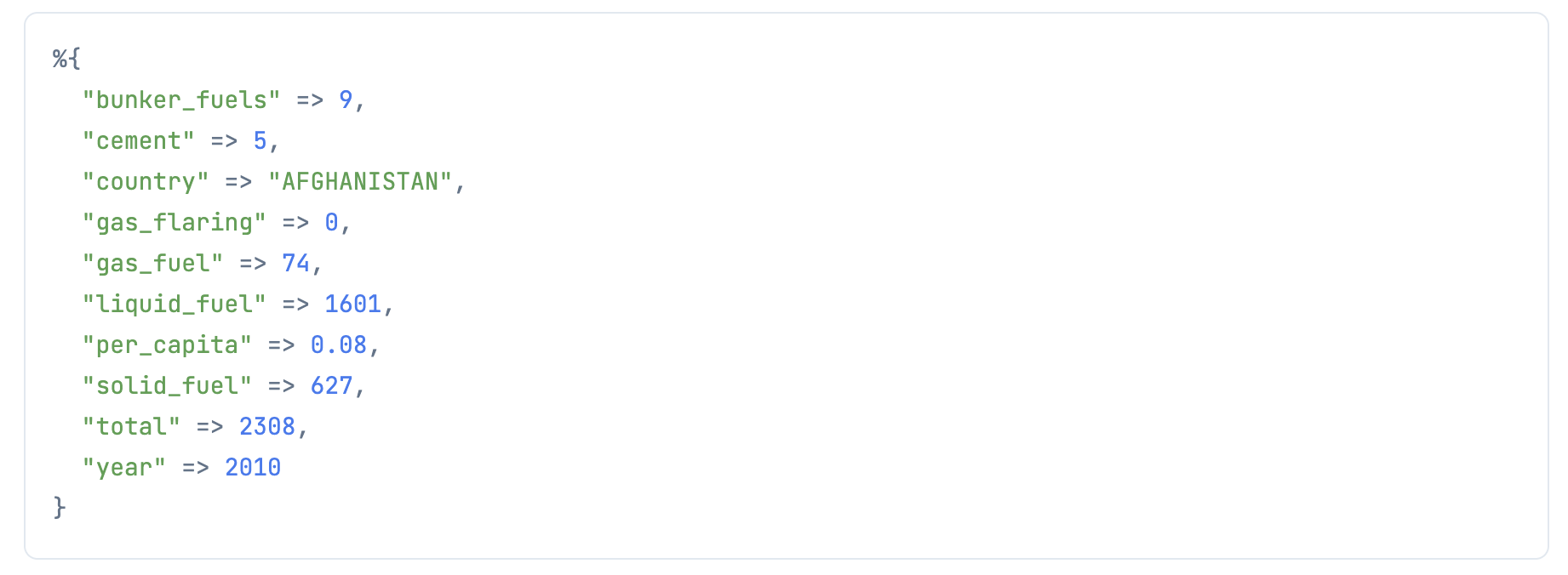
Dynamo.put_item にそのまま渡せば追加できます
table_name
|> Dynamo.put_item(item)
|> ExAws.request(auth_config)

では全件追加しましょう、と言いたいところですが、書込キャパシティー 1 で全件追加するとすごく時間がかかるため、 2012 年以降の A で始まる国のデータだけに限定します
対象データを確認します
df
|> DataFrame.put(
:initial,
Series.transform(df["country"], fn country -> String.first(country) end)
)
|> DataFrame.filter(initial == "A")
|> DataFrame.filter(year >= 2012)
|> DataFrame.select(DataFrame.names(df))
|> Kino.DataTable.new()
対象データを逐次追加します
速すぎると書き込みキャパシティーを超えてエラーになってしまうため、 Process.sleep(500) で速度を抑えます
df
|> DataFrame.put(
:initial,
Series.transform(df["country"], fn country -> String.first(country) end)
)
|> DataFrame.filter(initial == "A")
|> DataFrame.filter(year >= 2012)
|> DataFrame.select(DataFrame.names(df))
|> DataFrame.to_rows()
|> Enum.with_index()
|> Enum.map(fn {row, index} ->
IO.inspect(index)
Process.sleep(500)
table_name
|> Dynamo.put_item(row)
|> ExAws.request(auth_config)
|> IO.inspect()
end)
ゆっくり全件追加できました
データ取得
DynamoDB のデータ取得には scan と query と get_item があります
scan はキー項目による絞り込みができないときに使います
DynamoDB 上で全件読み込みが行われるため、読込キャパシティーが無駄に消費されるため推奨されません
全件取得する場合は使っても良いです
res =
table_name
|> Dynamo.scan()
|> ExAws.request!(auth_config)
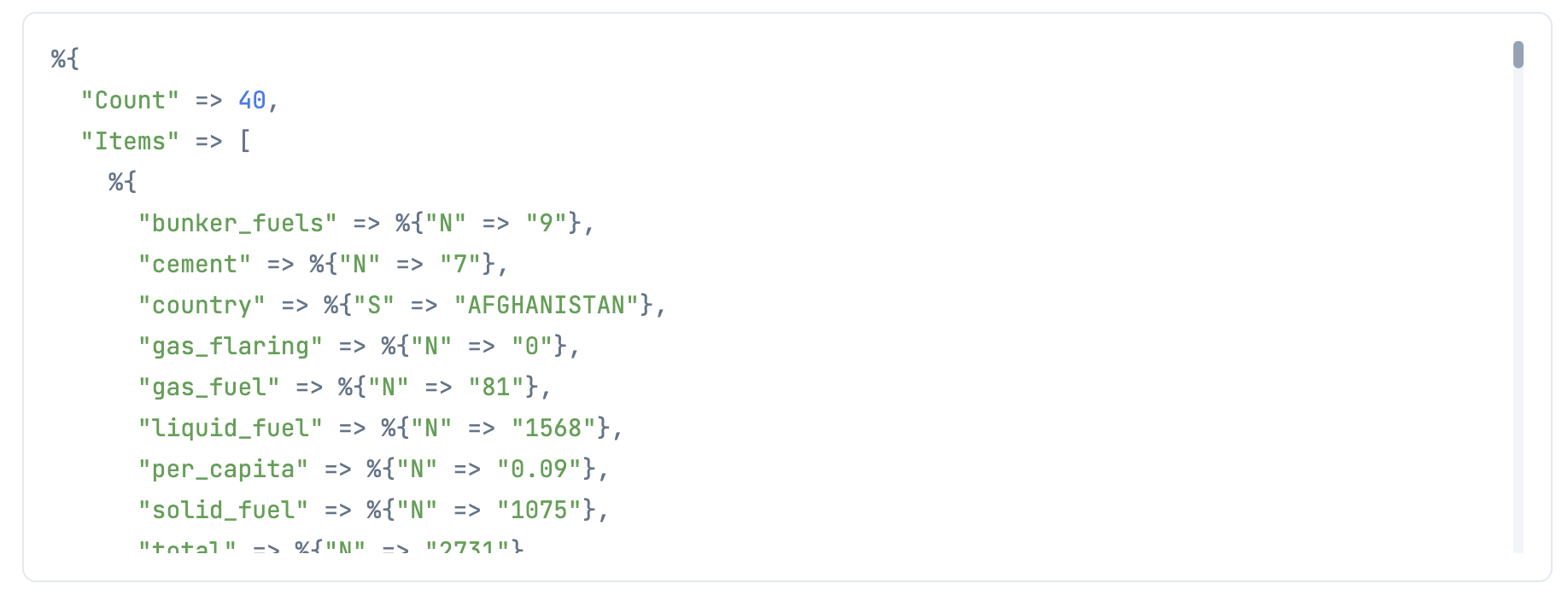
先に入れていた1件 + まとめて入れた39件で合わせて40件取得できています
ただし、取得した形式が "bunker_fuels" => %{"N" => "9"}, というように型と値をキーバリューにした特殊な形式になっているため、整形してからデータフレームに入れます
デーコード用の関数を定義します
decode = fn item ->
item
|> Enum.reduce(%{}, fn {key, type_value}, merged ->
type =
type_value
|> Map.keys()
|> Enum.at(0)
value =
type_value
|> Map.values()
|> Enum.at(0)
parsed =
case type do
"N" ->
if String.contains?(value, ".") do
String.to_float(value)
else
String.to_integer(value)
end
"S" ->
value
end
%{key => parsed}
|> Map.merge(merged)
end)
end
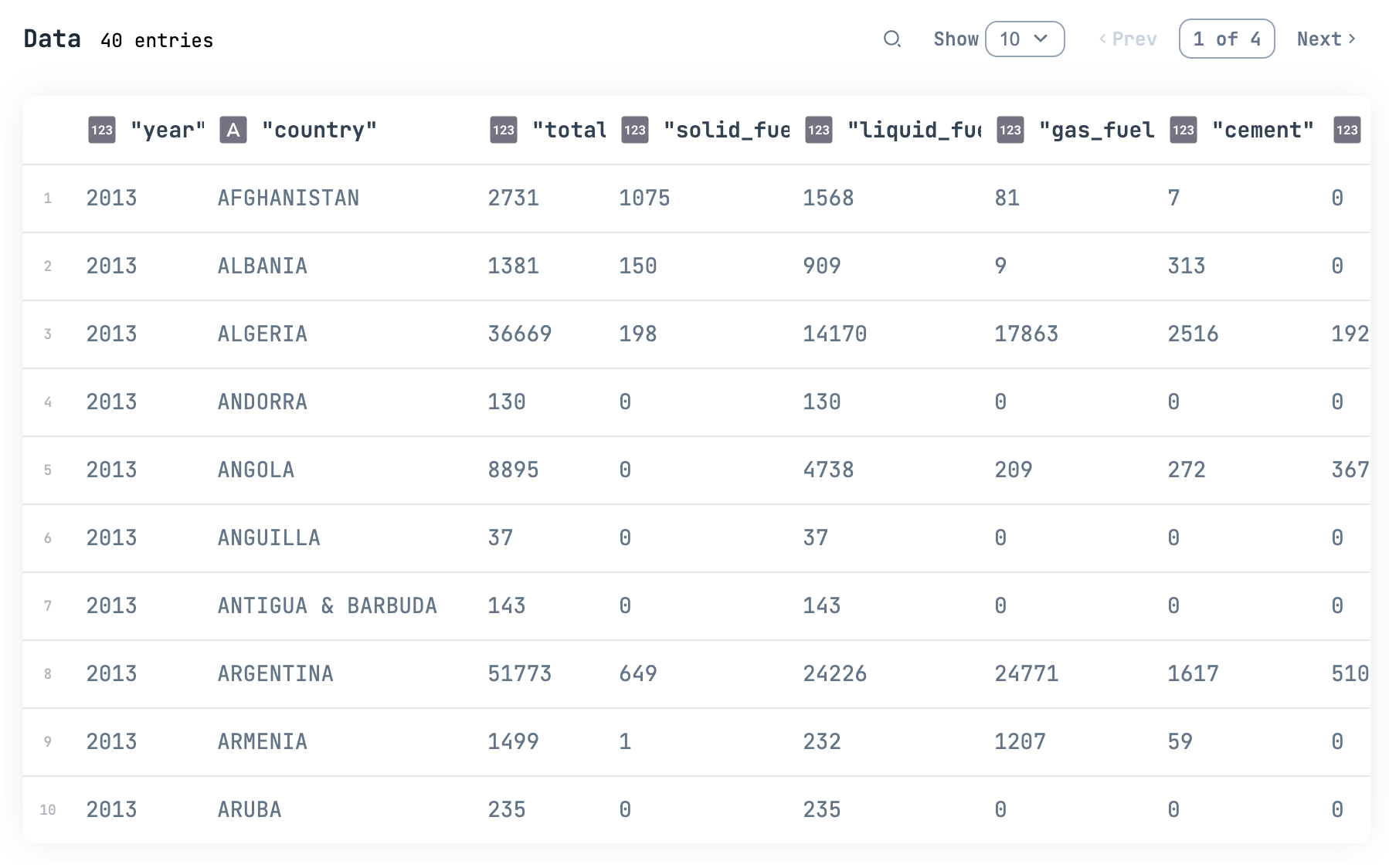
decoded_df =
res["Items"]
|> Enum.map(&decode.(&1))
|> DataFrame.new()
decoded_df
|> DataFrame.select(DataFrame.names(df))
|> Kino.DataTable.new()
scan に検索条件や上限件数を指定することもできます
decoded_df =
table_name
|> Dynamo.scan(
limit: 3,
expression_attribute_values: [value: 1_000],
expression_attribute_names: %{"#name" => "total"},
filter_expression: "#name > :value"
)
|> ExAws.request!(auth_config)
|> then(&(&1["Items"]))
|> Enum.map(&decode.(&1))
|> DataFrame.new()
decoded_df
|> DataFrame.select(DataFrame.names(df))
|> Kino.DataTable.new()
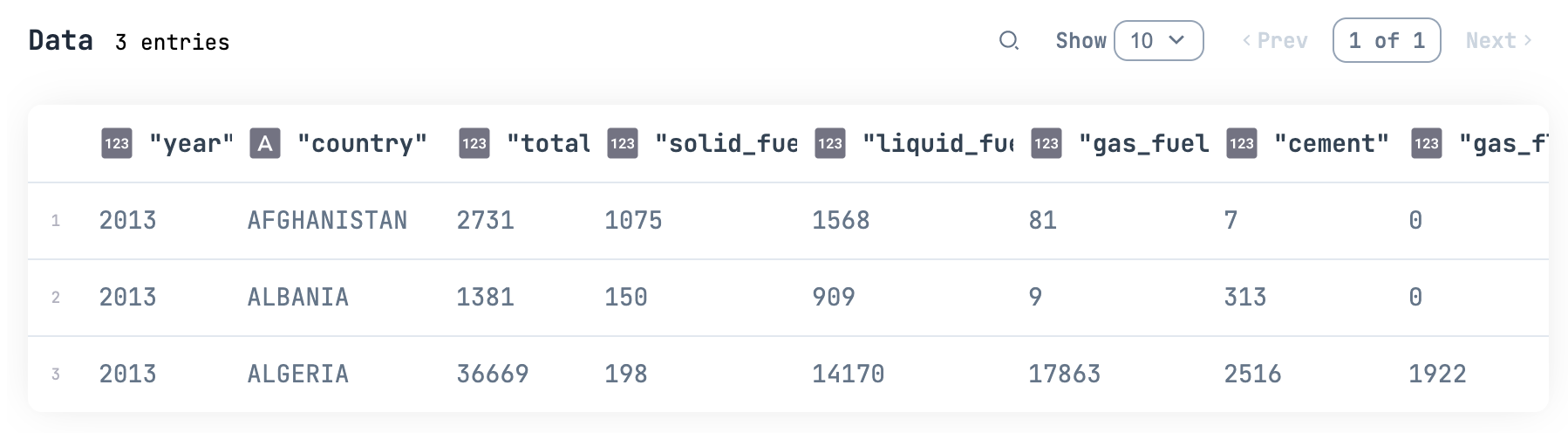
query はキー項目によって絞り込みを行います
このとき、 DynamoDB はキーによって絞り込まれたパーティションだけを読み込むため、消費される読込キャパシティーが少なくなります
decoded_df =
table_name
|> Dynamo.query(
limit: 5,
expression_attribute_values: [value: 2013],
expression_attribute_names: %{"#name" => "year"},
key_condition_expression: "#name = :value"
)
|> ExAws.request!(auth_config)
|> then(&(&1["Items"]))
|> Enum.map(&decode.(&1))
|> DataFrame.new()
decoded_df
|> DataFrame.select(DataFrame.names(df))
|> Kino.DataTable.new()
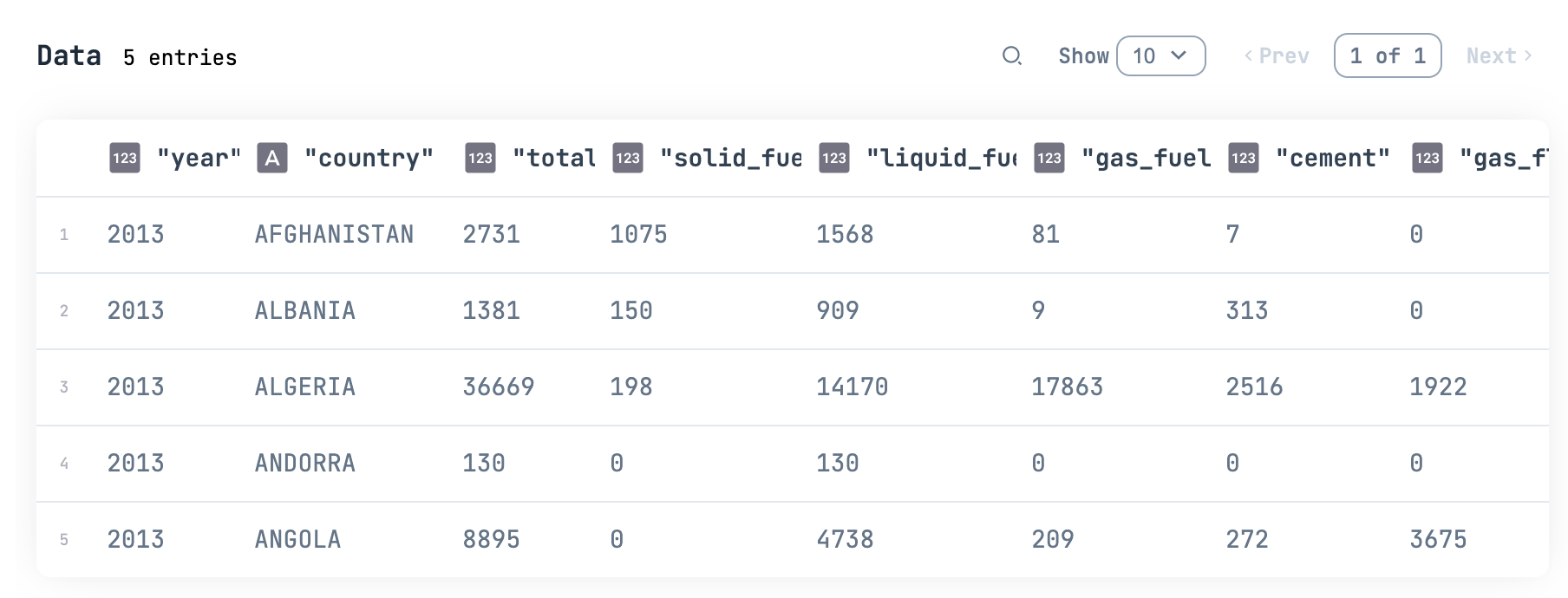
get_item はキー項目を全て指定して特定のデータ1件だけを取得します
decoded_df =
table_name
|> Dynamo.get_item(%{year: 2012, country: "AFGHANISTAN"})
|> ExAws.request!(auth_config)
|> then(&(&1["Item"]))
|> decode.()
|> List.wrap()
|> DataFrame.new()
decoded_df
|> DataFrame.select(DataFrame.names(df))
|> Kino.DataTable.new()

データ更新
データ更新には Dynamo.update_item を使います
テーブル名、キー項目、更新内容を指定します
update_expression の場合は set を付けます
table_name
|> Dynamo.update_item(
%{year: 2012, country: "AFGHANISTAN"},
expression_attribute_values: [cement_value: 6],
expression_attribute_names: %{"#cement_name" => "cement"},
update_expression: "set #cement_name = :cement_value"
)
|> ExAws.request!(auth_config)

decoded_df =
table_name
|> Dynamo.get_item(%{year: 2012, country: "AFGHANISTAN"})
|> ExAws.request!(auth_config)
|> then(&(&1["Item"]))
|> decode.()
|> List.wrap()
|> DataFrame.new()
decoded_df
|> DataFrame.select(DataFrame.names(df))
|> Kino.DataTable.new()

データ削除
削除は Dynamo.delete_item です
table_name
|> Dynamo.delete_item(
%{year: 2012, country: "AFGHANISTAN"}
)
|> ExAws.request!(auth_config)
decoded_df =
table_name
|> Dynamo.scan()
|> ExAws.request!(auth_config)
|> then(&(&1["Items"]))
|> Enum.map(&decode.(&1))
|> DataFrame.new()
decoded_df
|> DataFrame.select(DataFrame.names(df))
|> Kino.DataTable.new()
テーブル設定更新
一時的に読込キャパシティーや書込キャパシティーを変更したくなった場合は以下のようにしてテーブル設定を更新します
table_name
|> Dynamo.update_table(%{
provisioned_throughput: %{
read_capacity_units: 3,
write_capacity_units: 3,
}
})
|> ExAws.request(auth_config)

返ってくる値は更新前のテーブル設定になっています
更新後の(最新の)テーブル設定は Dynamo.describe_table で取得します
table_name
|> Dynamo.describe_table()
|> ExAws.request(auth_config)
テーブル削除
テーブルを削除します
table_name
|> Dynamo.delete_table()
|> ExAws.request(auth_config)

Dynamo.list_tables()
|> ExAws.request(auth_config)

まとめ
わざわざデータ解析のためだけに DynamoDB を使うことはありませんが、何らかのデータ(IoT機器から送られてくるセンサー値など)を DynamoDB に溜めていて、それを解析することはあると思います
DynamoDB から scan もしくは query してきたデータを Livebook 上で解析する、という用途になりそうです