はじめに
Elixir から AmiVoice API による音声認識を実行します
今回も Livebook を使っていきます
AmiVoice API の利用方法については公式のマニュアルを参照
AmiVoice とは
AmiVoice は株式会社アドバンストメディアが開発した音声認識ソフトウェアです
特長はなんと言っても 「日本語に対する精度の高さ」 でしょう
世の中に音声認識サービスは数多ありますが、グローバルに展開しているものはどうしても日本語に非対応だったり、対応していても精度がいまいちだったりします
AmiVoice は私たち日本人が使うのに最適化されています
こちらから音声認識を実際に動かして試せるので使ってみましょう
例えば、以下のような文章もバッチリ認識できました
- 拝啓春暖の候、ますますご清栄のこととお喜び申し上げます
- 国民は、全ての基本的人権の享有を妨げられない
- OECグループは、技術と信頼真心をモットーに、高い技術力を持ったICTサービス企業として、 お客様のニーズにお応えし、社会に貢献してまいります
- 大分県大分市東春日町17番57号ソフトパーク内
更に医療系や金融・保険業界に特化したエンジンも選択できます
また、 API 利用量が安く、 毎月 60 分無料 であることも魅力です
発話時間にしか課金されないため、無音が続くような場合にも無駄がありません
加えて、昨今生成 AI 周りでよく気にされることですが、いわゆる オプアウト = 学習用にデータを使わせない 指定もできます(その分費用が高くなります)
音声データがサーバーに保存されるのはちょっと、、、という場合にも使えるのは嬉しいですね
アカウント登録
AmiVoice の API を使うためには、まずアカウント登録が必要です
最初の 60 分が無料なので 0 円で試すことが可能ですが、クレジットカードの登録は必須です
公式サイトのトップページから、右下の方にある「API を無料で利用開始」のボタンをクリックしましょう
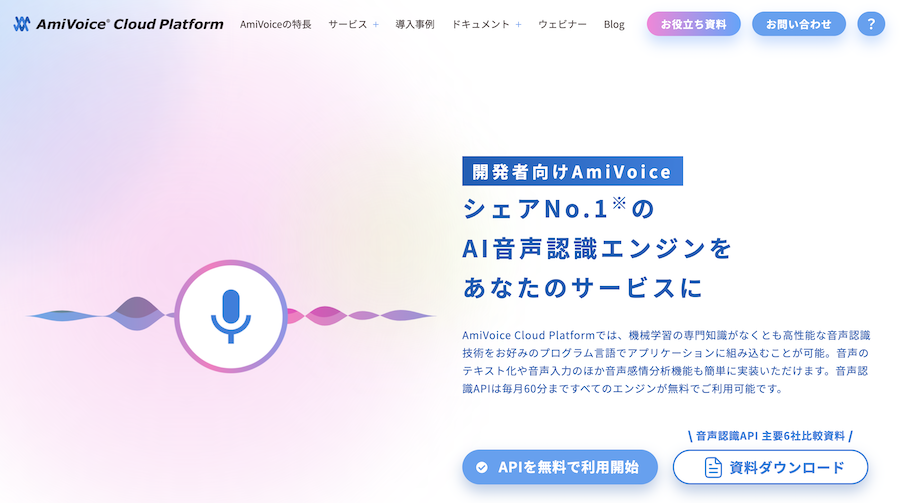
メールアドレスを入力する画面が表示されるので、あとは指示に従っていきます
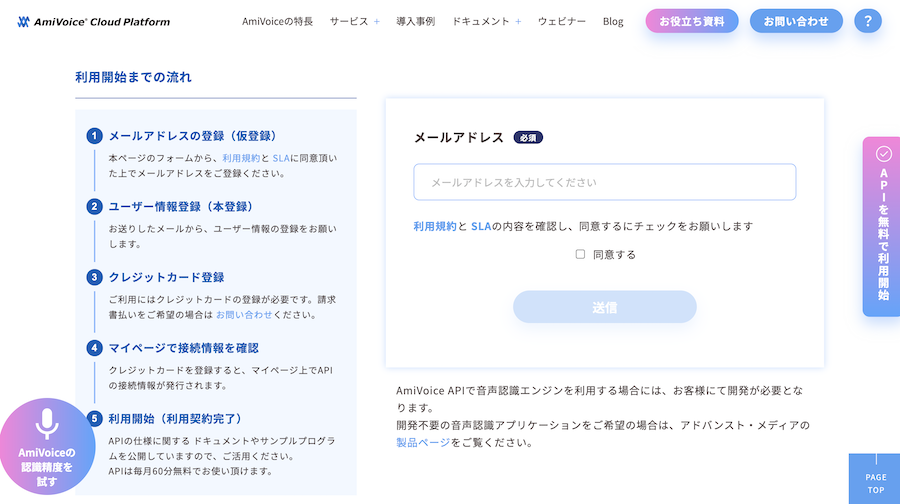
アカウントが登録できたら以下の URL からマイページにログインできます
ただし、クレジットカードを登録していないと以下のような表示になるため、クレジットカードを登録しましょう
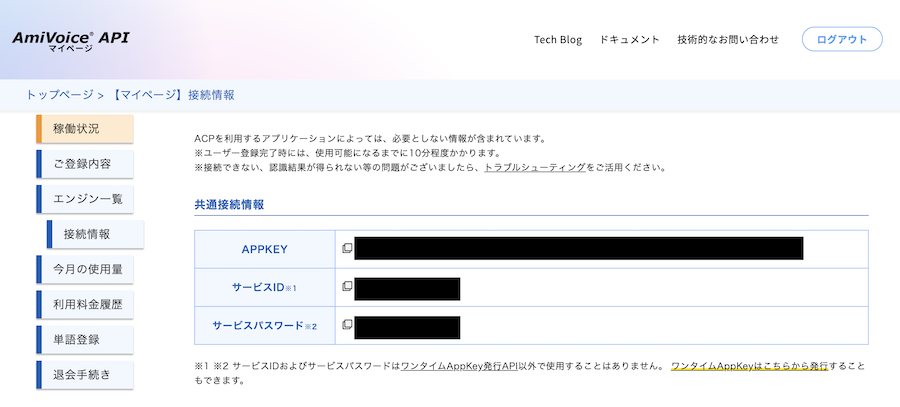
接続情報
マイページの左メニュー「接続情報」をクリックすると、 API 呼び出しに使う「APPKEY」が確認できます
環境構築
音声の形式変換のため、 Vice というモジュールを使います
Vice には以下のモジュールが必要です
- cmake
- ffmpeg
- libav
- libopencv-dev
- imagemagick
- SoX
今回は音声を扱うため、少なくとも SoX が必須になります
Ubuntu の場合は以下もコマンドでインストールできます
apt install sox
私は以下のリポジトリーにある Docker コンテナで Livebook を立ち上げています
(今回、 SoX のインストールを追加しました)
セットアップ
Livebook を起動し、新しいノートブックのセットアップセルに以下のコードを入力、実行します
Mix.install([
{:kino, "~> 0.12"},
{:multipart, "~> 0.4"},
{:req, "~> 0.4"},
{:vice, "~> 0.1"}
])
API の呼び出しに Req を使います
音声データと認証情報、オプション等をマルチパートで送信するため、 Multipart を使用します
接続情報の設定
API の認証に使う APPKEY を入力します
appkey_input = Kino.Input.password("APPKEY")
APPKEY はAmiVoice マイページの接続情報からコピーしてください

APPKEY をマルチパートのデータに格納します
Kino.nothing() はセルの出力結果に認証情報を表示しないためのコードです
auth_part =
appkey_input
|> Kino.Input.read()
|> Multipart.Part.text_field("u")
Kino.nothing()
入力データの準備
AmiVoice API のエンドポイント URL を設定します
今回はログが残らない(音声データを AmiVoice のサーバー上に保存しない)エンドポイントを指定しています
api_endpoint = "https://acp-api.amivoice.com/v1/nolog/recognize"
音声入力を用意します
AmiVoice API は wav 形式に対応しているため、形式に :wav を指定します
16k 以上のサンプリングレートは意味がない(API に送っても 16k にダウンサンプリングされる)ため、サンプリングレートを 16_000 に指定します
audio_input = Kino.Input.audio("Audio", format: :wav, sampling_rate: 16_000)

「Record」ボタンをクリックするとマイクから録音できます
初回は以下のようなアラートがブラウザに表示されるので、マイクの使用を許可してください

録音できると以下のような表示になります

以下のコードにより、音声データの保存先パスが取得できます
audio_path =
audio_input
|> Kino.Input.read()
|> Map.get(:file_ref)
|> Kino.Input.file_path()
出力結果(一例)
"/tmp/livebook/sessions/gfwl4emfac5g3ipnryin7zya57i3h236pahpnzqv5alt6z2l/registered_files/7c77otkkqjt7kjzm"
この音声ファイルはビットレート 32 になっていますが、 AmiVoice API はビットレート 16 に変換しないと「サポートしていない形式」としてエラーになってしまいます
そこで、 Vice を使ってビットレートを変換します
まず、一時ファイルとして .wav の拡張子を付けてコピーします
File.copy!(audio_path, "/tmp/input.wav")
Vice のプロセスを起動します
Vice.start()
Vice に変換を依頼します(非同期です)
{:async, worker} = Vice.convert("/tmp/input.wav", "/tmp/input_16b.wav", output_bits: 16)
worker の状態は以下のコードで確認できるので、結果が :done になるまで待ちます
Vice.status(worker)
変換した入力ファイルをマルチパートのデータに格納します
audio_content = File.read!("/tmp/input_16b.wav")
audio_part = Multipart.Part.file_content_field("audio", audio_content, "a")
認証情報、エンジンの指定、音声データをマルチパートにまとめます
公式マニュアルにある通り、必ず音声データを一番最後に追加します
multipart =
Multipart.new()
|> Multipart.add_part(auth_part)
|> Multipart.add_part(Multipart.Part.text_field("-a-general", "d"))
|> Multipart.add_part(audio_part)
Kino.nothing()
リクエスト時のヘッダーを設定します
content_length = Multipart.content_length(multipart)
content_type = Multipart.content_type(multipart, "multipart/form-data")
headers = [
{"Content-Type", content_type},
{"Content-Length", to_string(content_length)}
]
リクエストを送信します
{:ok, response} = Req.post(api_endpoint, headers: headers, body: Multipart.body_stream(multipart))
出力結果を確認してみます
response.body
出力結果
%{
"code" => "",
"message" => "",
"results" => [
%{
"confidence" => 0.998,
"endtime" => 2516,
"rulename" => "",
"starttime" => 900,
"tags" => [],
"text" => "こんにちは。",
"tokens" => [
%{
"confidence" => 0.96,
"endtime" => 2164,
"spoken" => "こんにちは",
"starttime" => 1204,
"written" => "こんにちは"
},
%{
"confidence" => 0.77,
"endtime" => 2516,
"spoken" => "_",
"starttime" => 2164,
"written" => "。"
}
]
}
],
"text" => "こんにちは。",
"utteranceid" => "20240414/10/018eda4081d80a301ee894c7_20240414_103724"
}
上記は「こんにちは」だけの例ですが、以下のような長文でも正しく認識できました
(一部、漢字がおかしい箇所がありますが、裁判に特化しているわけではないので致し方ないでしょう)
本日はこの裁判所において、被告桃太郎氏および彼の同行者犬猿雉に対する公判を改定いたします。
被告らは、不法侵入、盗難および暴力行為の罪に問われています。
まとめ
マルチパートで送信する点、ビットレートを16に変換する点で少し躓きましたが、無事、 Elixir から AmiVoice API を呼び出して音声認識を実行できました
毎月 60 分無料であるため、気軽に試すことができました
また、他の音声認識サービスと比較して、かなり日本語の認識精度が高いことも確認できました
日本向けのサービスであれば、かなり利用できそうですね