はじめに
Elixir でデータ分析を行う Explorer の v0.4.0 がリリースされました
大きな変更は以下の2点です
- Query によってより直感的なデータ操作が可能になった
- Nx のテンソルとシームレスな変換が可能になった
この記事では Query について紹介します
実装の全文はこちら
Query で大きく変わったのは以下の4つの関数です
- mutate
- filter
- summarise
- arrange
注意点
※Query を使う場合、必ず先に以下のコードを記述してください
require Explorer.DataFrame
もし require を忘れていた場合は以下のようなエラーが発生します
variable "xxx" does not exist and is being expanded to "xxx()", please use parentheses to remove the ambiguity or change the variable
列に対する変換
以下のようなデータフレームを用意します
sample_df =
%{
"labels" => ["a", "b", "c", "c", "c"],
"values" => [1, 2, 3, 2, 1],
}
|> DataFrame.new()
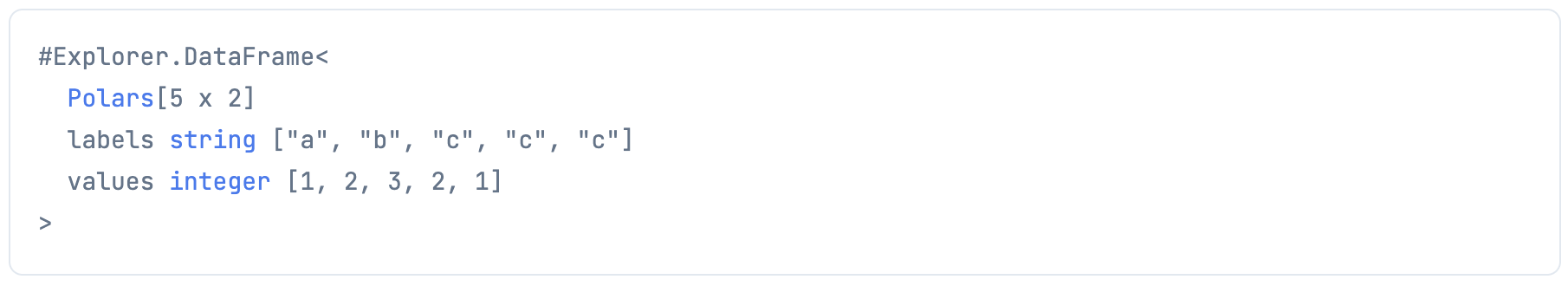
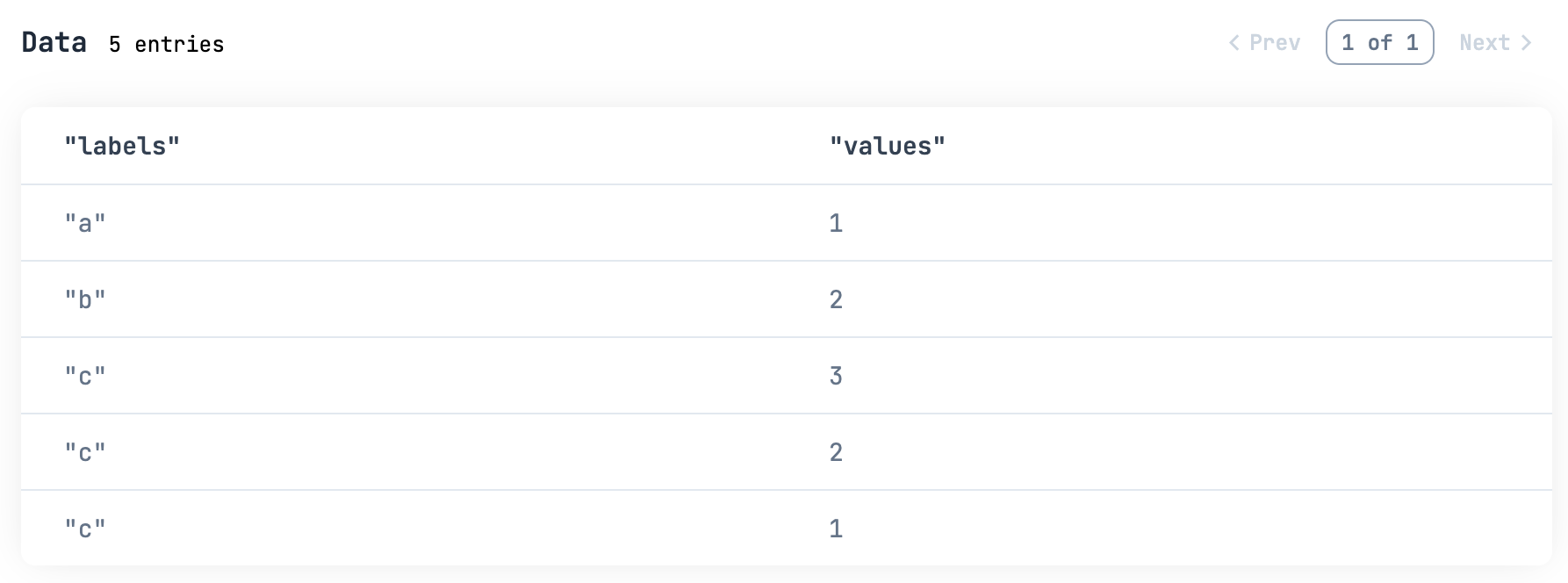
データテーブルで表示すると以下のようになります
sample_df
|> Kino.DataTable.new()
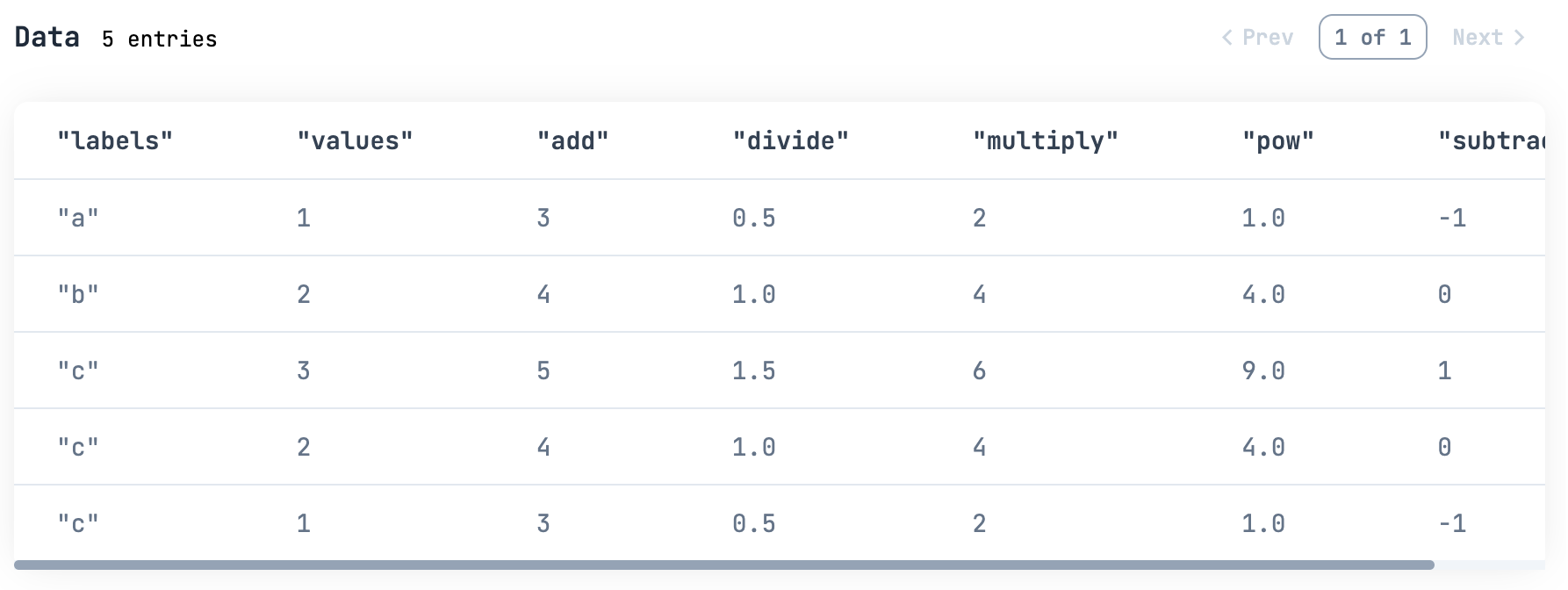
例えば values 列に何らかの計算をして、その結果を新しい列として追加する場合、今までは mutate_with を使っていました
sample_df
|> DataFrame.mutate_with(&[
add: Series.add(&1["values"], 2),
subtract: Series.subtract(&1["values"], 2),
multiply: Series.multiply(&1["values"], 2),
divide: Series.divide(&1["values"], 2),
pow: Series.pow(&1["values"], 2),
])
|> Kino.DataTable.new()
sample_df
|> DataFrame.mutate_with(&[
equal: Series.equal(&1["values"], 2),
not_equal: Series.not_equal(&1["values"], 2),
greater: Series.greater(&1["values"], 2),
greater_equal: Series.greater_equal(&1["values"], 2),
less: Series.less(&1["values"], 2),
less_equal: Series.less_equal(&1["values"], 2),
])
|> Kino.DataTable.new()

四則演算や比較を表すのに Series.add や Series.equal を使わないといけません
これらを Query を使った書き方にしてみましょう
sample_df
|> DataFrame.mutate(
add: values + 2,
subtract: values - 2,
multiply: values * 2,
divide: values / 2,
pow: values ** 2
)
|> Kino.DataTable.new()
sample_df
|> DataFrame.mutate(
equal: values == 2,
not_equal: values != 2,
greater: values > 2,
greater_equal: values >= 2,
less: values < 2,
less_equal: values <= 2
)
|> Kino.DataTable.new()
見やすさ、分かりやすさが全然違いますね
列名をそのまま変数として使える上に、記号で演算が表せるので直感的です
データの抽出
フィルターの場合も同様です
今までの filter_with を使った書き方
threshold = 1
sample_df
|> DataFrame.filter_with(&Series.greater(&1["values"],threshold))
|> Kino.DataTable.new()
Query を利用した書き方
threshold = 1
sample_df
|> DataFrame.filter(values > ^threshold)
|> Kino.DataTable.new()
かなり分かりやすいです
クエリ内で列名以外の変数を使う場合、 ^ を変数名の先頭につける必要があります
集計
集計もスッキリします
今までの summarise_with を使った書き方
sample_df
|> DataFrame.group_by("labels")
|> DataFrame.summarise_with(&[
count: Series.count(&1["values"]),
n_distinct: Series.n_distinct(&1["values"]),
min: Series.min(&1["values"]),
max: Series.max(&1["values"]),
sum: Series.sum(&1["values"]),
mean: Series.mean(&1["values"]),
median: Series.median(&1["values"]),
"quantile 1/4": Series.quantile(&1["values"], 0.25),
"quantile 3/4": Series.quantile(&1["values"], 0.75),
variance: Series.variance(&1["values"]),
standard_deviation: Series.standard_deviation(&1["values"]),
])
|> Kino.DataTable.new()
Query を使った書き方
sample_df
|> DataFrame.group_by("labels")
|> DataFrame.summarise(
count: count(values),
n_distinct: n_distinct(values),
min: min(values),
max: max(values),
sum: sum(values),
mean: mean(values),
median: median(values),
"quantile 1/4": quantile(values, 0.25),
"quantile 3/4": quantile(values, 0.75),
variance: variance(values),
standard_deviation: standard_deviation(values)
)
|> Kino.DataTable.new()
並べ替え
今までの arrange_with を使った書き方
sample_df
|> DataFrame.arrange_with(&[asc: &1["values"]])
|> Kino.DataTable.new()
Query を使った書き方
sample_df
|> DataFrame.arrange(asc: values)
|> Kino.DataTable.new()
Explorer 0.3.0 からのマイグレーション
以前、 0.3.0 で書いていたものを 0.4.0 で書き換えてみましょう
例えばこれは、、、
★0.3.0
population_df
|> DataFrame.filter(&Series.equal(&1["都道府県"], "東京都"))
|> DataFrame.select(["年齢層", "性別", "人口(千人)"])
|> DataFrame.table(limit: :infinity)
こうなります
★0.4.0
# 列名の `()` が邪魔なので `_` に変更
population_df =
population_df
|> DataFrame.rename("人口(千人)": "人口_千人")
population_df
|> DataFrame.filter(都道府県 == "東京都")
|> DataFrame.select(["年齢層", "性別", "人口_千人"])
|> Kino.DataTable.new(sorting_enabled: true)
もっと複雑なものだと、、、
★0.3.0
population_df
|> DataFrame.filter(&Series.equal(&1["年齢層"], "15歳未満"))
|> DataFrame.filter(&Series.equal(&1["性別"], "男性"))
|> DataFrame.filter(&Series.greater(&1["人口"], 300_000))
|> DataFrame.select(["都道府県", "人口"])
|> DataFrame.arrange(desc: "人口")
|> DataFrame.table(limit: 10)
★0.4.0
population_df
|> DataFrame.filter(年齢層 == "15歳未満")
|> DataFrame.filter(性別 == "男性")
|> DataFrame.filter(人口 > 300_000)
|> DataFrame.select(["都道府県", "人口"])
|> DataFrame.arrange(desc: 人口)
|> Kino.DataTable.new()
★0.3.0
elderly_rate_df =
population_df
|> DataFrame.group_by(["都道府県", "年齢層"])
|> DataFrame.summarise(人口: [:sum])
|> DataFrame.rename(人口_sum: "人口")
|> DataFrame.mutate_with(fn df ->
[
人口: Series.cast(df["人口"], :float)
]
end)
|> DataFrame.pivot_wider("年齢層", "人口")
|> DataFrame.mutate_with(fn df ->
[
合計: Series.add(df["15歳未満"], df["15~64歳"])
]
end)
|> DataFrame.mutate_with(fn df ->
[
合計: Series.add(df["合計"], df["65歳以上"])
]
end)
|> DataFrame.mutate_with(fn df ->
[
高齢者率: Series.divide(df["65歳以上"], df["合計"])
]
end)
|> DataFrame.select(["都道府県", "高齢者率"])
elderly_rate_df
|> DataFrame.arrange(desc: "高齢者率")
|> Kino.DataTable.new(sorting_enabled: true)
★0.4.0
elderly_rate_df =
population_df
|> DataFrame.group_by(["都道府県", "年齢層"])
|> DataFrame.summarise(人口: sum(人口))
|> DataFrame.mutate(人口: cast(人口, :float))
|> DataFrame.pivot_wider("年齢層", "人口")
|> DataFrame.rename("15歳未満": "young")
|> DataFrame.rename("15~64歳": "middle")
|> DataFrame.rename("65歳以上": "elder")
|> DataFrame.mutate(合計: young + middle + elder)
|> DataFrame.mutate(高齢者率: elder / 合計)
|> DataFrame.select(["都道府県", "高齢者率"])
elderly_rate_df
|> DataFrame.arrange(desc: 高齢者率)
|> Kino.DataTable.new(sorting_enabled: true)
圧倒的に見やすくなりましたね
まとめ
今後は見やすい Query を使ってデータ操作しましょう