はじめに
先日参加した JAWS DAYS 2024 にて紹介されていた、 Stockmark さんの日本語 LLM を Google Colab で動かしてみます
Stockmark さんのテックブログはこちら
モデルの取得元
モデルは Hugging Face で公開されています
モデルのダウンロードに Hugguing Face のアクセストークンが必要になるので、サインアップしてトークンを用意しておきましょう
設定画面の左メニューから「Access Tokens」を開き、「New token」ボタンでトークンが作成できます
Google Colab のランタイム
Google Colab の Free プランで使える T4 GPU の場合、 GPU RAM が 15 GB しかないため、 130 億パラメーターのモデルを動かすのには足りません
モデルのロード時に以下のような警告メッセージが表示されてしまいます
WARNING:root:Some parameters are on the meta device device because they were offloaded to the disk and cpu.
これはモデルのロード中に GPU RAM が枯渇しそうになり、残りを CPU で動かすように調整されるためです

この状態ではモデルの一部が CPU で動いてしまうため、動作が非常に重く、実際のところ全く使えません
お金はかかりますが、 Google Colab Pro を契約しましょう
月額千円強ですが、色々やるなら他の環境よりは安く済むと思います
Google Colab Pro になると高性能な GPU が使えるようになるので、 A100 GPU (GPU RAM: 40 GB)を使いましょう
V100 GPU は GPU RAM 不足になります
ノートブックの設定
新しいノートブックを開きます
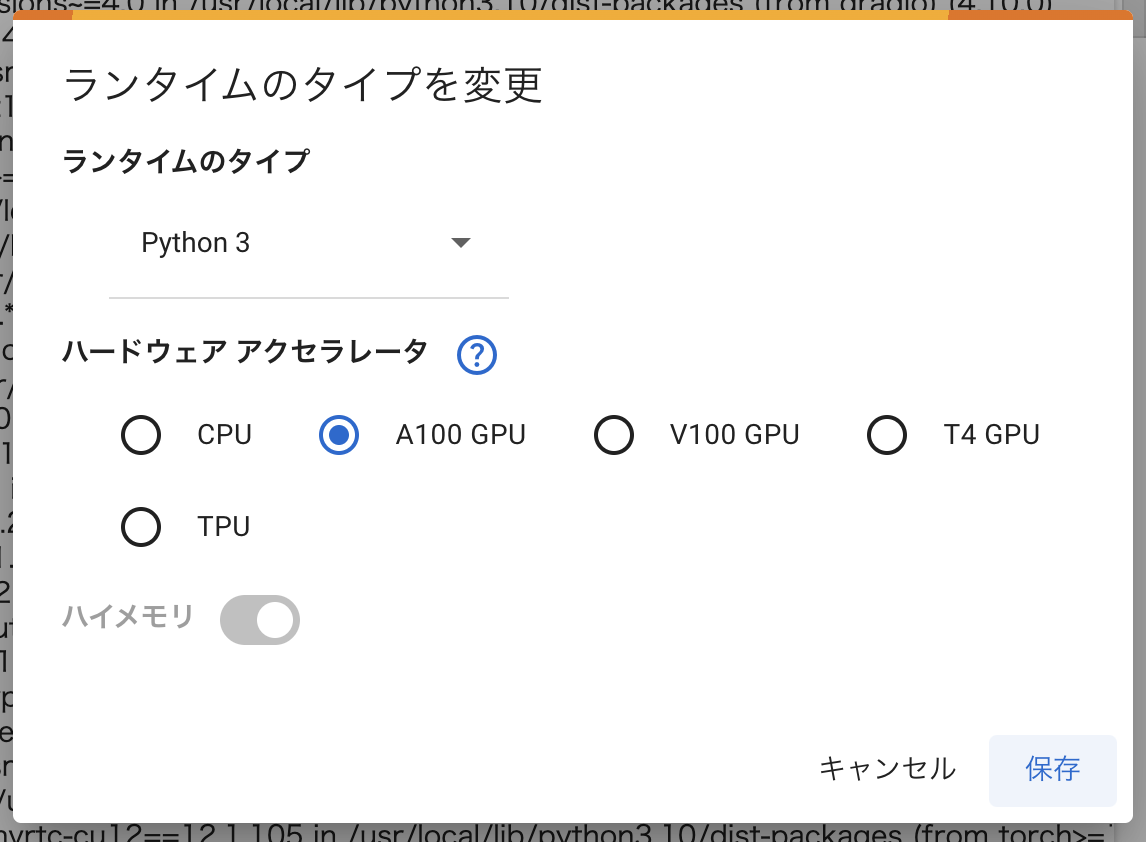
上メニューから「ランタイム」 |> 「ランタイムのタイプを変更」を開きます

ハードウェアアクセラレータで「A100 GPU」を選択し、「保存」をクリックします
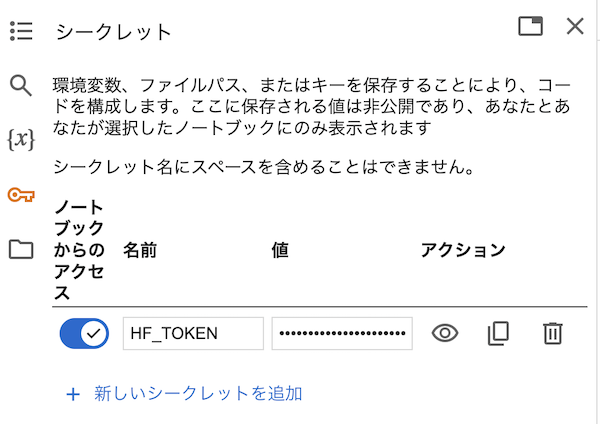
左メニューの鍵アイコンをクリックし、 HF_TOKEN という名前で Hugging Face のアクセストークンをシークレットに登録しておきます
「ノートブックからのアクセス」を忘れず ON にしておきましょう
セットアップ
以降、 Colab のセルにコードを貼り付けて実行します
初回セル実行時、場合によっては「A100 GPU」を使うことができず、「V100 GPU」で実行されてしまうことがあります
そのまま進んでも GPU RAM 不足になるため、その場合はランタイムを接続解除、削除しましょう
しばらく待ってから改めてランタイムタイプに「A100 GPU」を選択し、再度実行して A100 が使えるまでリトライします
リトライが嫌な場合は Colab のさらに上のプランを契約しましょう
pip 自体を最新化してから、必要なモジュールをインストールします
!pip install --upgrade pip
!pip install --upgrade accelerate transformers gradio
モジュールをインポートしておきます
import gradio as gr
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer
gradio は最後に UI を作るためのものなので、モデルを動かしたいだけの場合は不要です
モデルのロード
transformers の機能で Hugging Face からモデルをダウンロードし、ロードします
device_map="auto" を指定することで、自動的に環境に合った状態(GPU の有無など)でロードしてくれます
model = AutoModelForCausalLM.from_pretrained(
"stockmark/stockmark-13b",
device_map="auto",
torch_dtype=torch.bfloat16
)
上手くいっていれば実行ログに警告メッセージが出ず、 GPU RAM も余裕があります

トークナイザーも同様に Hugging Face からロードします
tokenizer = AutoTokenizer.from_pretrained("stockmark/stockmark-13b")
生成
モデルとトークナイザーを使用し、文章の生成を実行します
以下のコードの場合、「自然言語処理とは」に続く文章を生成させています
inputs = tokenizer("自然言語処理とは", return_tensors="pt").to(model.device)
with torch.no_grad():
tokens = model.generate(
**inputs,
max_new_tokens=128,
do_sample=True,
temperature=0.7
)
output = tokenizer.decode(tokens[0], skip_special_tokens=True)
print(output)
実行結果は以下のように出力されます
自然言語処理とは、人工知能(AI)研究の一分野で、人間が日常的に使っている自然言語をコンピュータに処理させる一連の技術のこと。
自然言語処理を用いて、文章の意味や内容をコンピュータで解析し、文章を要約したり自動翻訳したり、コンピュータが文章を書く支援をしたりします。
自然言語処理(Natural Language Processing)とは、人間の言語をコンピュータで解析・処理する技術のことです。
自然言語とは、人間が日常的に使っている言語のことで、英語や日本語、中国語などが挙げられます。
自然言語処理の技術は、1950年代のコンピュータの誕生以来、研究が続けられています。
自然言語処理には、いくつか
UI付きで実行
Gradio を使って簡易的な UI を用意します
まず、入力を出力に変換するための関数を用意します
def chat(input):
tokens = tokenizer(input, return_tensors="pt").to(model.device)
with torch.no_grad():
tokens = model.generate(
**tokens,
max_new_tokens=128,
do_sample=True,
temperature=0.7
)
output = tokenizer.decode(tokens[0], skip_special_tokens=True)
return output
Gradio で入出力を定義します
gr.Interface(
fn=chat,
inputs=[gr.Textbox()],
outputs=[gr.Textbox()]
).launch(debug=True)
実行すると、以下のような UI が表示されます
左側の input に適当な文言を入れてみましょう
「Submit」を押すと、右側の output に生成結果が表示されます
改行しようとして Enter キーを押すと「Submit」を押したときと同じように生成処理が実行されてしまいます
改行したい場合は Shift キーを押しながら Enter キーを押しましょう
ビジネスっぽい文章を入れてみたところ、かなりビジネスっぽく答えてくれました
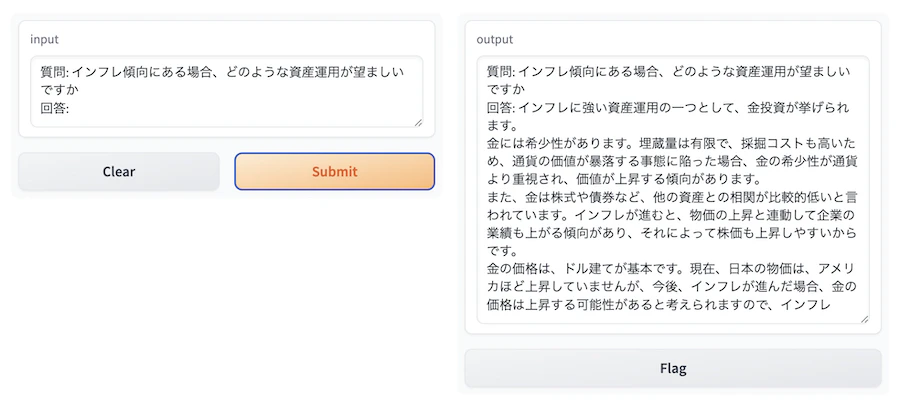
2023年9月時点の最新情報を学習しているとのことなので、2020 年の米大統領選挙について答えています

ビジネス一筋だからなのか、ジョークを言うのは苦手なようです

ビジネスっぽくない質問でもいい感じに答えてくれることもあります

数学は多少いけるみたいです

一通り遊び終わったら上メニューから「ランタイム」|>「ランタイムを接続解除して削除」を選択し、ランタイムを削除しておきましょう
ランタイムを動かし続けていると、無駄に コンピューティング・ユニットを消費してしまいます
余談
KARAKURI さんの 70b パラメーターの AI も動かそうと試行錯誤してみましたが、やはり 70b = 700億 は大きすぎて Colab Pro でも GPU RAM が足りませんでした
次は Turing さんのモデルを動かしてみたいと思っています
まとめ
Stockmark 社の stockmark-13b を Google Colaboratory で動かすことができました
ビジネス関連のことであれば、思った以上に日本語でしっかり答えてくれます
ただ、やはり 13b = 130 億パラメーターともなると、かなりのスペックが必要になりますね
用途を限定して(比較的)少ないパラメーターで動かすようにしないと、実運用は厳しそうです