記事概要
■作成までの経緯、状況
「インデックスは、辞書の目次みたいなものだから。使えば検索が早くなる」
SQLを使い始めてまだ間もないころ、先輩に言われた言葉です。
「お!なるほど!とりあえず貼ればいいのかあ」
と馬鹿の一つ覚えのようにテーブルにインデックスを貼りまくった結果、
その後のパフォーマンスチュー二ングにとても苦しみました。
インデックスの作成はできる。けれどしくみが説明できない。。
当時の自分への備忘録として、本記事の作成に至りました。
使用する用語はMySQLに準じます。
■発生した問題
インデックスの作成方法はわかるが、なぜ効果があるのかがわからない。
■期待する効果
インデックスのしくみを説明できるようにする。
■問題を解決するための用法
Qiitaで記事を書く。
■しくみ、動作原理
以下のポイントでインデックスのしくみを説明します。
- テーブルを用意する。
- データ検索の流れを理解する。
- インデックスのしくみを理解する。
- インデックスが使えない場合を理解する。
ポイント1 「テーブルを用意する」
インデックスを作成するには、テーブルが必要です。
今回は、あるアニメの「登場人物」テーブルを用意します。
| 登場人物 |
|---|
| イカリ シンジ |
| アヤナミ レイ |
| スズハラトウジ |
| カツラギ ミサト |
| アカギ リツコ |
| カジ リョウジ |
| イカリ ゲンドウ |
| ・・・ |
| ヒュウガ マコト |
| ナギサ カヲル |
2020/06/27 楽しみだなー( ´∀` )
ポイント2 「データ検索を理解する」
テーブルを検索する流れは以下の通りです。
① HDD上のデータがページ単位でキャッシュメモリに載る。
② キャッシュメモリに載ったテーブルをCPUが処理する。
③ メモリがパンパンになったら削除され、①に戻る。
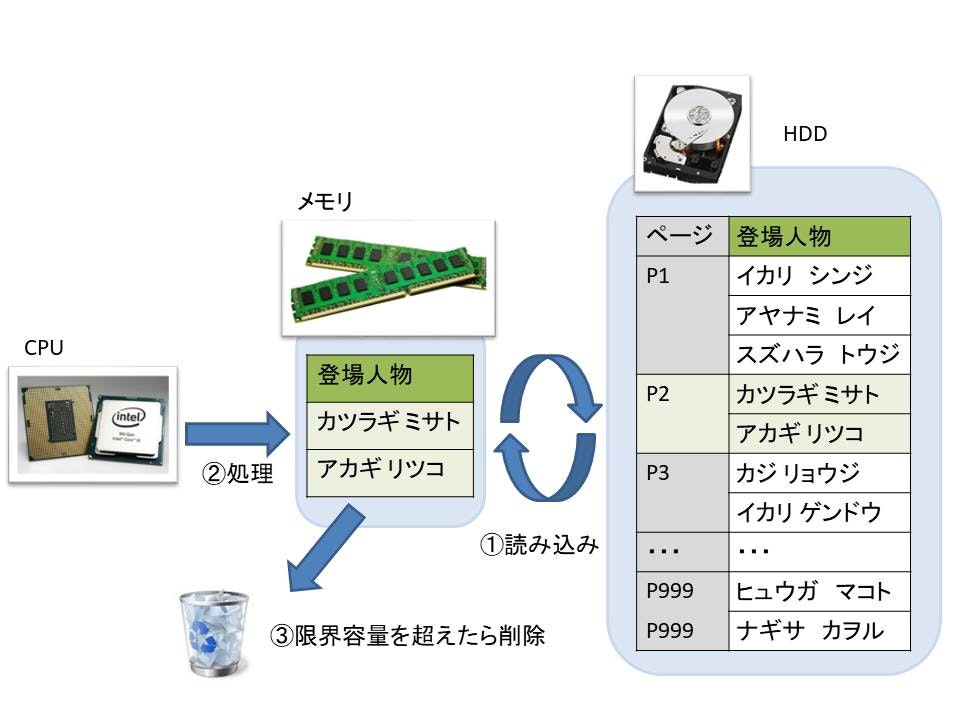
①の「ページ」とは、データをかたまりで見た時の単位を意味します。
上記では、P2のデータをメモリに載せています。
Oracleでは「ブロック」と言います。
この図を見たときの疑問点として以下のものが挙げられます。
「②の時に検索したいデータがあれば、その時点で検索が終わるんじゃない?」
これに対する答えは**「検索は続くよどこまでも」**です。
インデックスを作成していないと、データがソートされません。
そのため、「ほかにも同様のデータがあるんじゃ。。」
となり、結局テーブル全体が検索されます。これがフルスキャンです。
(メモリにキャッシュされている部分は除く)
だからパフォーマンスが落ちるのですね!!![]()
ポイント3 「インデックス作成ロジックを理解する」
数あるインデックスの中で、MySQLで使用されているのはB+treeです。
B-treeとも呼ばれますが、厳密には、B-treeを実用的扱いやすく改良したものがB+treeです。
B-treeインデックスについての説明は以下の記事がとても分かりやすいです。
「B-treeインデックス入門」
以下はメモリやHDDページを省略した簡単な図解です。
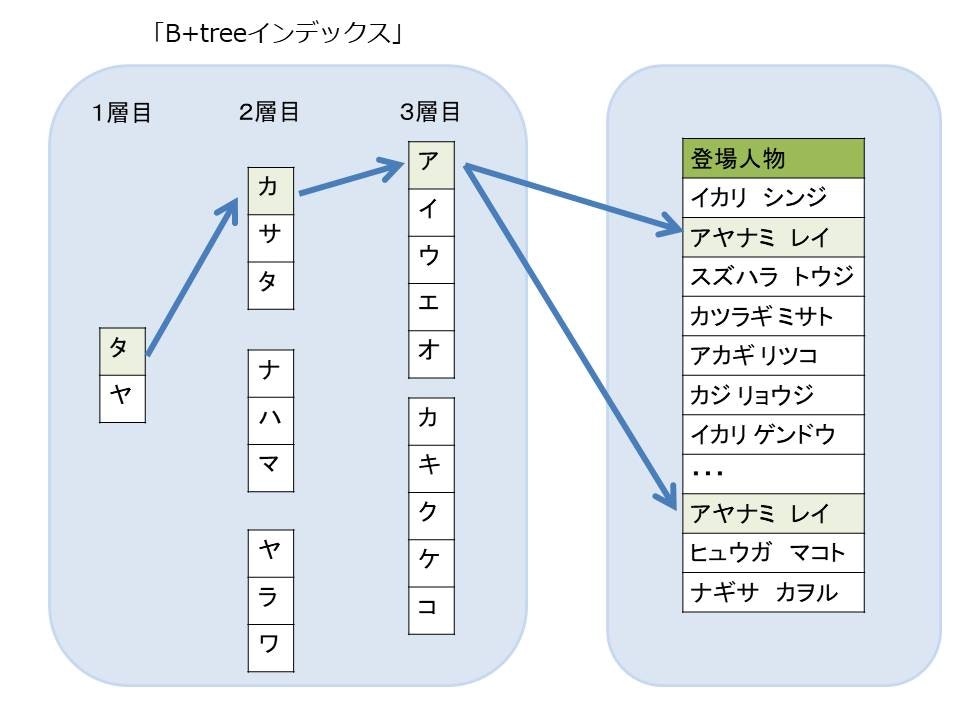
ここでは検索対象として「アヤナミ レイ」を2件用意しました。
HDD全体を検索するフルスキャンでは、検索終了までに何回もHDDを読み込む必要があります。
しかし、B-treeインデックスを使用した場合、図からもわかるように2か所のHDDページだけを直接読み込むことで検索が終了します。
インデックスのデータ構造はただテーブルがソートされていただけでなく、
このようなしくみで検索されていたから早くなるのです。![]()
ポイント4 「インデックスが使えない時を知る」
インデックスが役に立たない場合は以下の通りです。
・データ数が少ないとき
・後方一致検索
・前方一致検索(検索結果が多いときのみ)
後方検査でインデックスが使用できない理由は、上記の図からもわかりますね。
要は**「データは頭文字から照合されていくため、中間地や後方一致検索にインデックスを使用できないから」**です。
前方一致検索でインデックスが使用できない理由は、**「頭文字が同じものが多数ある場合、結局検索する対象が多くなるから」**です。
おわりに
最後までお読みいただき、ありがとうございました!
本記事の作成を通して、インデックスのしくみが理解できました。
内容に誤りがありましたら、ご指摘ください。
参考書籍
オススメの技術書籍を楽天Roomで紹介しています。
「SQLの苦手を克服する本 データの操作がイメージできれば誰でもできる」
https://room.rakuten.co.jp/room_39a28b3432/items#!