Databricks on AWSの閉域網構成
Databricksとは一言でいうとレイクハウスプラットフォームで、DWH/データレイクのデータ蓄積・管理とBI/AIのデータ分析の環境を同じシステム・UI上から利用できます。
Databricksのアーキテクチャ上の特徴の一つとして、自社データをDatabricks社管理のクラウド上には配置せずに、自社のAWS等のクラウドアカウント上にのみ自社データを配置する構成を取れる点があります。本記事では、Databricks on AWSをAWS内からインターネットに接続しない閉域網で構成することで、よりセキュリティが高い構成にすることを試してみます。
システム構成概要
今回は下図のようなシステム構成としました。図中のリソース名は、本記事内での識別名として便宜的に付けた名前です。

この構成図はあくまで一例であり、自社のAWS環境の制約や要件などに応じてカスタマイズすることができます。本システム構成では下記の特徴があります。
カスタマーマネージドVPC
Databricks on AWSの構築方法には、AWSクイックスタートを利用する方法と、自身でVPCから作成する方法(カスタマーマネージドVPC)があります。カスタマーマネージドVPCについての説明、下記ドキュメントに記載されています。
Databricks on AWSを閉域網で構成するためには、クライアント端末-databricksコントロールプレーンへの接続(フロントエンド)および、databricksのデータプレーン-コントロールプレーンの接続(バックエンド)のためにAWS PrivateLinkを利用する必要があります。AWS PrivateLinkはAWSクイックスタートで作成したVPCでは利用できないため、今回はカスタマーマネージドVPCの構成で構築します。
VPC Interface Endpointの共用
Databricks on AWSを閉域網で構成する場合、公式ドキュメントでは下記の3種類のVPCインタフェースエンドポイントが必要と記載されています。
| 項番 | 目的 | 通信の種類 | サービス名(東京リージョン) |
|---|---|---|---|
| 1 | Rest API and User Access | フロントエンド | com.amazonaws.vpce.ap-northeast-1.vpce-svc-02691fd610d24fd64 |
| 2 | Rest API and User Access | バックエンド | com.amazonaws.vpce.ap-northeast-1.vpce-svc-02691fd610d24fd64 |
| 3 | SCC Relay | バックエンド | com.amazonaws.vpce.ap-northeast-1.vpce-svc-02aa633bda3edbec0 |
しかし、今回のDatabricks on AWSの環境では、項番1と2のフロントエンドとバックエンドのRest API and User Accessエンドポイントを、1つのエンドポイントで共用する形として構成しています。
この理由として、公式ドキュメントではオンプレミス環境との専用線(AWS Direct Connect)が導入済のAWS環境を想定して記載されており、そのような環境では通常オンプレミス環境との接続を一元管理するためにトランジットVPC(ハブVPCとも言う)が準備されています。このような環境では、公式ドキュメントの記載通り、フロントエンド通信は専用線を経由するためバックエンド通信とは分離して、トランジットVPC側にフロントエンド通信専用のエンドポイントを配置することが望ましいと考えられます。
しかし、今回私がdatabricksを構築したAWS検証環境はDirect Connectが未導入でトランジットVPCが存在しない環境だったため、フロントエンド通信とバックエンド通信でエンドポイントを分ける意義がないと考えて、同じ一つのエンドポイントを経由して通信するように構成しました。本構成でのフロントエンド通信の制御は、エンドポイントのセキュリティグループ(図中のSecurity Group 01)の送信元IPアドレスの設定により接続元クライアント端末を制限しています。
システム構築手順
この章から、このシステム構成での構築内容を簡単に記載します。正確な構築手順については、下記のDatabricks公式ドキュメントをご参照ください。
1. クロスアカウントIAMロールの作成
自社のAWS環境にクロスアカウントIAMロール(Cross-Account IAM Role)を作成します。このIAMロールは、Databricks社管理のAWSアカウント上のControl Planeが自社AWS内のクラスター(Amazon EC2)の作成や削除などの管理操作を許可するためのオブジェクトです。詳細な設定方法や内容については、下記の公式ドキュメントをご確認ください。
このクロスアカウントIAMロールに設定するIAMポリシーについて、今回はカスタマーマネージドVPC構成であり特段のカスタマイズ要件はないため、公式ドキュメントに記載の「オプション2:デフォルトの制限ポリシーを使用した顧客管理VPC」のIAMポリシーのJSONの雛型を利用します。
2. ネットワーク設定
自社AWS内のVPCと、その中のサブネット, ルートテーブル, セキュリティグループ, VPCエンドポイント等のネットワークリソースを設定します。詳細な設定内容については下記の公式ドキュメントをご確認ください。
2.1. VPC
VPCを作成します。今回は検証用AWS内の既存のVPC(リージョンは東京)を使い回しました。
2.2 サブネット
下表のサブネットを準備します。Databricksのクラスター用のサブネットは、アベイラビリティーゾーンが異なる2つのサブネットを、Databricks占有(Databricksクラスター以外のリソースを含めない)のものとして準備する必要があります。
| サブネット名 | ルートテーブル名 | 占有 | サイズ | 用途 |
|---|---|---|---|---|
| Public Subnet 01 | Public Route Table | - | 任意 | VPC Interface Endpoint for Web and Rest APIを配置 |
| Private Subnet 01 | Private Route table | 占有 | /17~/26 | databricksのクラスター(Amazon EC2)を配置 |
| Private Subnet 02 | Private Route table | 占有 | /17~/26 | databricksのクラスター(Amazon EC2)を配置 |
| Private Subnet 03 | Private Route table | - | 任意 | プライベート通信用のVPC Interface Endpointを配置 |
Databricksクラスターとは、Databricks上のSpark処理等を実行するAmazon EC2のことで、databircks上でクラスターを起動/停止するとこのサブネット内でAmazon EC2が作成/削除されます。
databricksクラスター用のサブネットのサイズについて、公式ドキュメントには下記のように記載されています。
Databricksは、ノードごとに2つのIPアドレス(1つは管理トラフィック用、もう1つはSparkアプリケーション用)を割り当てます。各サブネットのインスタンスの合計数は、使用可能なIPアドレスの数の半分になります。
そのため、サブネット内に配置可能なノード(EC2インスタンス)数の上限は、IPv4の桁数が32ビットでAWSのサブネットの予約アドレス数が5個なので、サブネットのサイズをNとすると下記の式で計算することができると思います。
[1サブネット内に配置可能なdatabrickクラスターのノード数の上限] = (2^{32-N}-5)/2
例えばサブネットのサイズを/24とした場合は、この計算式では最大125個のノード(EC2インスタンス)を配置可能です。このような考え方で、databricksクラスターの必要なノード数の最大に応じて/17~/26の範囲でサイズを指定します。
2.3 ルートテーブル
下表に記載するルートを追加したルートテーブルを準備し、それぞれをサブネットに紐づけます。
| ルートテーブル名 | 紐付先リソース | 追加ルート |
|---|---|---|
| Public Routetable 01 | Public Subnet 01 | インターネットゲートウェイ |
| Private Routetable 01 | Private Subnet 01, 02 | S3ゲートウェイエンドポイント |
| Private Routetable 02 | Private Subnet 03 | - |
今回は一応分けましたが、Private Subnet 03からS3エンドポイントに接続可能でも問題ないため、Private Routetable 01と02は一つのルートテーブルにまとめてしまってもよいと思います。
2.4 セキュリティグループ
セキュリティグループは、下記のように設定しました。
| セキュリティグループ名 | 紐付先リソースのサブネット | インバウンドルール | アウトバウンドルール |
|---|---|---|---|
| Security Group 01 | Public Subnet 01 | ・クライアント端末のIPアドレスから443ポートのTCP通信 ・Security Group 02から全TCP通信 |
・0.0.0.0/0へ全TCP通信 |
| Security Group 02 | Private Subnet 01, 02 | ・自身のセキュリティグループ(Security Group 02)から全TCP,UDP通信 | ・自身のセキュリティグループ(Security Group 02)へ全TCP,UDP通信 ・0.0.0.0/0の443,3306,6666,2443,8443-8451ポートへ全TCP通信 |
| Security Group 03 | Private Subnet 03 | ・Security Group 02から全TCP通信 | ・0.0.0.0/0へ全TCP通信 |
必要最小限の通信設定ではないかもしれないので、詳細な要件については公式ドキュメントをご確認ください。
2.5 VPCエンドポイント
下記のVPCエンドポイントを作成します。S3エンドポイントはゲートウェイ型のため、サブネット内には配置しません。
| 名前 | 種類 | 配置先サブネット | サービス名(東京リージョン) | 用途 |
|---|---|---|---|---|
| S3 Gateway Endpoint | ゲートウェイ | - | com.amazonaws.ap-northeast-1.s3 | Amazon S3への通信 |
| STS 01 | インタフェース | Private Subnet 03 | com.amazonaws.ap-northeast-1.sts | databricksクラスター管理 |
| Kinesis streams 01 | インタフェース | Private Subnet 03 | com.amazonaws.ap-northeast-1.kinesis-streams | databricksクラスター管理 |
| REST API and User Access | インタフェース | Public Subnet 01 | com.amazonaws.vpce.ap-northeast-1.vpce-svc-02691fd610d24fd64 | フロントエンド&バックエンド通信 |
| Secure Cluster Relay | インタフェース | Private Subnet 03 | com.amazonaws.vpce.ap-northeast-1.vpce-svc-02aa633bda3edbec0 | バックエンド通信 |
また、REST API and User Accessのエンドポイントには、インターネット経由でアクセスできるようにするためのElastic IPを割り当てます。
4. S3バケットの作成
Databricksが利用するS3バケットを作成します。
4.1 S3バケット(ワークスペース用)
Databricksワークスペース用のS3バケットを作成します。S3バケット作成時の設定は、基本的にデフォルトのままでOKです。後の手順でdatabricksアカウントコンソールの設定で生成したバケットポリシーを、アクセス許可タブのバケットポリシーにインラインで設定します。また、S3アクセスログの監査要件がある場合は、S3のプロパティのAWS CloudTraildイベントログの記録を有効化するように公式ドキュメントで推奨されています。
構築手順については、下記の公式ドキュメントをご参照ください。
4.2 S3バケット(Unity Catalog用)
Unity Catalogを有効化する場合は、Unity Catalogで管理するデータの格納先となるS3バケットと、databricksがそのS3バケットにアクセスできるようにするためにIAMロールを作成します。構築手順については、下記の公式ドキュメントをご参照ください。
5. databricksアカウントコンソール上の設定
databricksアカウントコンソール上の設定を行います。databricksアカウントコンソールはdatabrickのアカウント全体を管理する画面で、下記リンクからdatabricksアカウントの管理者権限を持つユーザアカウントでログインできます。
5.1 資格情報の設定
アカウントコンソールにログインしたら、左ペインの「クラウドリソース」->「資格情報の設定」タブを選択します。画面右上の「資格情報の設定を追加」ボタンをクリックし、ポップアップ画面の「資格情報の設定名」に適当な名前を入力し、「ロールARN」に1.クロスアカウントIAMロールの作成のクロスアカウントIAMロールのARNをコピペして入力した後に、「追加」ボタンを押します。

5.2 ストレージ設定
次に、「ストレージ設定」タブに移動します。画面右上の「ストレージ設定を追加」ボタンをクリックし、ポップアップ画面の「ストレージ設定名」に適当な名前を入力し、「バケット名」に4.1 S3バケット(ワークスペース用)で作成したS3バケット名を入力します。S3バケット名の下部の「ポリシーを生成」をクリックするとバケットポリシーが生成されるので、それをコピペしてAWSアカウントコンソールからワークスペース用のS3バケットのバケットポリシーに設定します。最後にポップアップ画面の「追加」ボタンを押します。

5.3 ネットワーク設定
「ネットワーク」タブに移動します。画面左側に「ネットワーク設定」「プライベートアクセス設定」「VPCエンドポイント」の設定項目が確認できます。
5.3.1 VPCエンドポイント
まずは「VPCエンドポイント」の設定画面からエンドポイントを登録します。画面右上の「VPCエンドポイントを登録」ボタンをクリックし、「VPCエンドポイント名」に適当な名前、「リージョン」にVPCのリージョン、「AWS VPCエンドポイントID」に2.5 VPCエンドポイントで作成したエンドポイントのIDを入力して、最後に「新しいエンドポイントを登録」ボタンをクリックします。
AWS VPCエンドポイントIDについて、本構成ではdatabricks Private Link用のエンドポイントを2つ(フロントエンド&バックエンド通信用のREST API and User Accessのエンドポイントと、バックエンド通信用のSecure Cluster Relayのエンドポイント)作成したため、その2つのVPCエンドポイントを別々に登録します。

5.3.2 プライベートアクセス設定
次に、「プライベートアクセス設定」の設定画面からフロントエンド通信を設定します。画面右上の「プライベートアクセス設定を追加」ボタンをクリックし、「プライベートアクセス設定名」に適当な名前、「リージョン」にVPCのリージョンを入力します。「パブリックアクセス」は今回はインターネットからdatabricksへの直接の接続を拒否したいのでFalseに設定します。「プライベートアクセスレベル」のラジオボタンについて「エンドポイント」を選択し、「VPCエンドポイント」に5.3.1 VPCエンドポイントで登録したエンドポイントのフロントエンド接続用のエンドポイント名を入力します。最後に、「プライベートアクセス設定を追加」ボタンをクリックします。

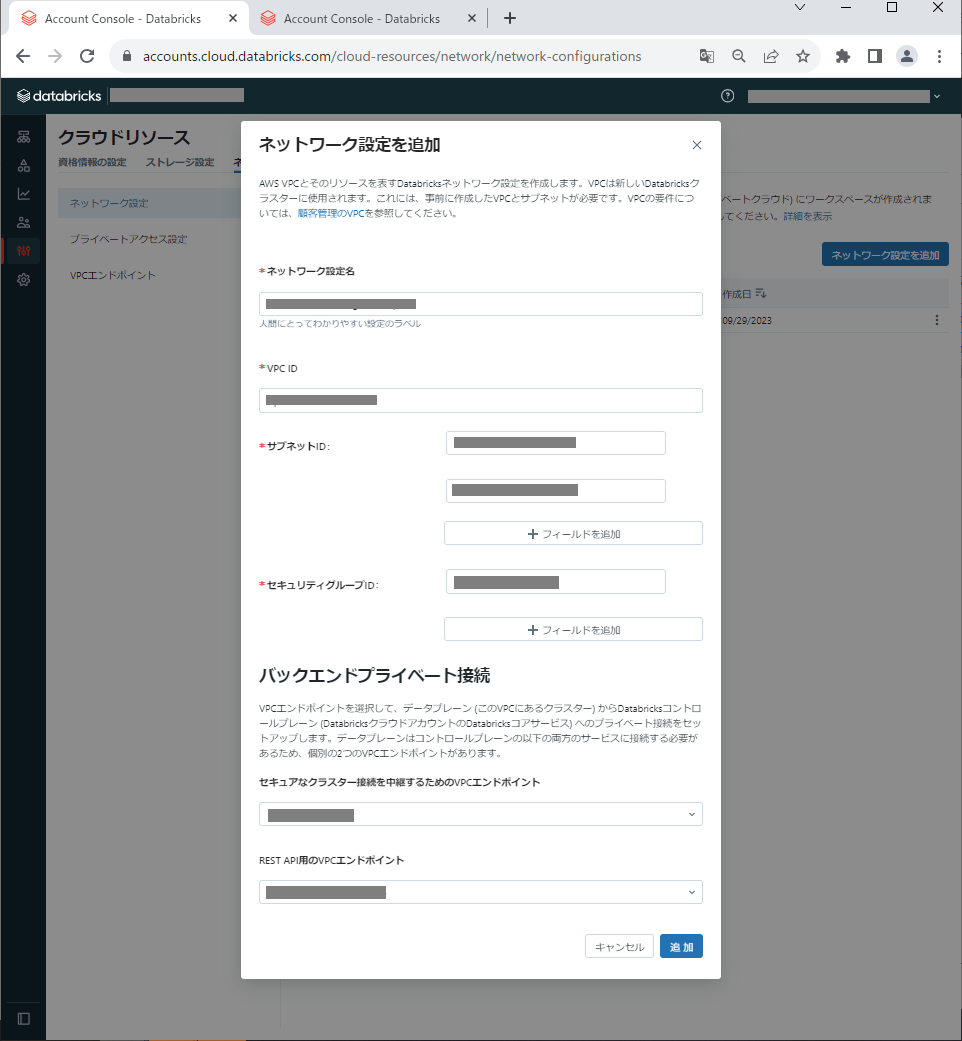
5.3.3 ネットワーク設定
最後に、「ネットワーク設定」の設定画面からdatabricksワークスペースのネットワークを設定します。画面右上の「ネットワーク設定を追加」ボタンをクリックし、「ネットワーク設定名」に適当な名前を入力します。VPC IDは2.1. VPCのID、サブネットIDは2.2 サブネットのIDのPrivate Subnet 01,02のID、セキュリティグループは2.4 セキュリティグループのSecurity Group 02のIDを入力します。
「バックエンドプライベート接続」の設定項目について、「セキュアなクラスター接続を中継するためのエンドポイント」には5.3.1 VPCエンドポイントで登録したエンドポイントのSecure Cluster Relayのエンドポイント、「REST API用のエンドポイント」にはREST API and User Accessのエンドポイントを設定します。
5.4 メタストア設定
Databricksのデータ管理機能であるUnity Catalogのメタストアを設定します。アカウントコンソール画面の左ペインの「メタストア」から設定できます。設定方法については、下記のドキュメントに記載されています。
なお、Unity Catalogは2023年11月8日からdatabricksワークスペース作成時に自動的に有効化されるようになったそうです。
Databricks は、2023 年 11 月 8 日に Unity Catalog の新しいワークスペースを自動的に有効にし、アカウント間で段階的にロールアウトを進めました。
本記事の環境は2023年11月8日以前にワークスペースを作成しており、現在の設定手順と変わっている可能性があると思われるため、詳細な手順は省略します。
Unity Catalogの設定自体はオプションですが、今回の閉域網環境ではUnity Catalogの前身ともいえるhive_metastoreの利用に制約がある(後述)ことと、Unity CatalogはDatabricksのデータ管理上非常に便利であることから設定することをお勧めします。
5.5 ワークスペースの作成
ここまで設定できたら、いよいよdatabricksワークスペースを作成します。アカウントコンソール画面の左ペインの「ワークスペース」を選択し、画面右上の「ワークスペースを作成」ボタンをクリックします。ワークスペースの作成方法については、今回はカスタマーマネージドVPC環境のため「手動」を選択します。
「ワークスペース名」に適当な名前、リージョンにVPCのリージョン、資格情報の設定に5.1 資格情報の設定で作成した資格情報設定名、ストレージ設定に5.2 ストレージ設定で作成したストレージ設定名、メタストア設定に5.4 メタストア設定で作成したメタストア名、ネットワーク構成に5.3.3 ネットワーク設定で作成したネットワーク設定名、プライベートリンクに5.3.2 プライベートアクセス設定で作成したプライベートアクセス設定名を選択して、画面下部の「保存」ボタンを押すとワークスペースを作成できます。

6. クライアント端末の設定
作成した閉域網環境のdatabricksワークスぺースに、クライアント端末からアクセスするためのクライアント側の環境を設定します。
6.1 名前解決の設定
クライアント端末からdatabricksワークスペースにアクセスするには、Webブラウザ等からAWS環境内に作成したフロントエンド接続用のVPCエンドポイント(REST API and User Access)に接続する必要があります。databricks画面操作の一部はdatabricksワークスペースのURL(http://dbc-xxxxxxxx-xxxx.cloud.databricks.com)1へのリダイレクトが発生するため、クライアント端末上でdatabricksワークスぺースのホスト名がエンドポイントのIPアドレスに名前解決されるようにする必要があります。名前解決の設定方法については、下記の公式ドキュメントに記載されています。
今回の環境では、私のクライアント端末の参照先DNSサーバの設定を容易に変更できない状況だったので、クライアント端末のhostsファイル(Windows端末の場合はC:\windows\system32\drivers\etc\hosts)に下記の行を追加することで対応しました。
[REST API and User AccessエンドポイントのElastic IPアドレス] dbc-xxxxxxxx-xxxx.cloud.databricks.com
databircks動作確認
作成したdatabricksワークスペースが正しく動作するかについてテストします。
フロントエンド接続テスト
フロントエンドの接続をテストするために、Webブラウザでdatabricksワークスペースにアクセスしてログインを試行します。ログインできれば成功です。もしAWS Private Linkではなくインターネット経由で接続していた場合は、下記のような画面が表示されてログインに失敗します。

ログインに失敗した場合は、クライアント端末の名前解決の設定やプロキシの設定に誤りがないか等について見直します。
バックエンド接続テスト
バックエンドの接続をテストするためには、databricksのクラスター画面からクラスターの上げ落としをテストします。クラスターを起動/停止できれば成功です。バックエンド接続ができない場合は、Connection Timeoutなどのネットワークエラーでクラスターの起動に失敗します。その場合は、バックエンド接続のネットワーク設定に誤りがないかを見直します。
Unity Catalog接続テスト
Unity Catalogを構成する場合は、databricksワークスペース上からUnity Catalogが管理するS3にファイルのアップロード等ができることをテストします。アップロードに失敗する場合は、S3の権限設定などを見直します。
閉域網構成の制約
完全閉域網構成のDatabricksワークスペースについて、私が確認できた範囲で下記の2つの制約がありました。これらの制約を回避したい場合は、databricksクラスター用のサブネットをNATゲートウェイに接続してインターネットへの通信を可能にした上で、AWS Firewall Services等を利用して必要な通信をホワイトリスト的に許可する等の対応が必要になります。
1. ライブラリのインストール
databricksノートブック上でpython等の新規ライブラリを利用したい時に、完全閉域網の構成では%pipコマンド等を利用してインターネット経由でインストールできません。回避方法については、下記の記事などをご参照ください。
2. Hive Metastoreの利用
閉域網構成でクラシックコンピュートのクラスターを起動すると、METASTORE_DOWNのエラーログが発生してクラスター起動に失敗する事象が発生する可能性があります。このエラーは閉域網構成特有のもので、DatabricksクラシックコンピュートのクラスターがHive Matastoreを利用するために、Databricksコントロールプレーン内のAmazon RDSに通信しようとして発生します。
このエラー回避を回避するためには、下記の設定でHive Metastoreへの通信を無効にする方法が最も簡単です。
Hive Metastoreはレガシーな機能であり、現在はUnity Catalogが利用できるため、特段の理由がない限り使う必要性がないため通常の利用方法では無効にしても問題はありません。
どうしてもHive Metastoreを利用したい場合
下記記のドキュメントの手順で、クラスターがAWS Glue Catalogにアクセスできるようにするためのインスタンスプロファイルを作成する設定を追加します。
https://docs.databricks.com/ja/archive/external-metastores/aws-glue-metastore.html
このドキュメントの手順に加えてAWS Glue用のVPCエンドポイントをPrivate Subnet 03に追加することで、ノートブックをエラーなく実行できるようになります。
Glue Catalog利用を有効化するSparkパラメータ
ドキュメント手順Step 6のreminder内に書かれているSparkパラメータの追加設定を忘れないようにしましょう(何度か設定を忘れて通信エラーになりました)。閉域網環境用のクラスターポリシーで、クラスターの高度なオプションのSpark構成に下記の設定を一行追加する方法が楽だと思います。
spark.databricks.hive.metastore.glueCatalog.enabled true
最後に
databricks環境を閉域網でも構成できることは、特にシステムのセキュリティが厳しい会社にとって嬉しい点の一つではないかと思います。なお、本手順で紹介したdatabricks on AWSの閉域網環境について、全てのdatabricksの機能をテストしたわけではないことにご注意ください。
-
http://dbc-xxxxxxxx-xxxx.cloud.databricks.comのxの部分は、databricksワークスペース作成時に自動的に決まります。 ↩