概要
CSVファイルの特定の列のデータを置換&列名を変更して書き出すという処理が必要になったので、Pythonで実装しました。
少しならエクセルとかでパパッと置換作業してしまえば良いですが、たくさんあったり何回も実施する必要があるときは面倒ですよね。ということで以下のPythonコードで、指定のディレクトリにある指定のCSVファイルのデータを置換することができたので紹介します。
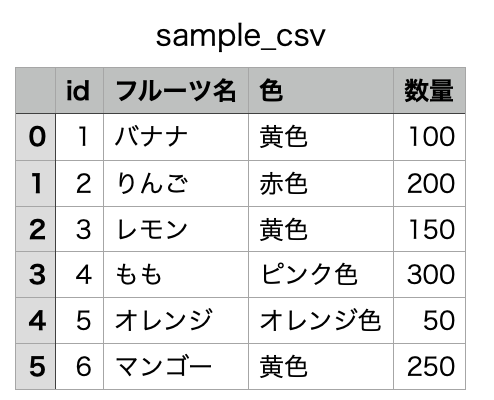
BEFORE

AFTER

サンプルコード
import pandas as pd
import os
filtered_csv_dir = './'
filtered_csv_filename = 'sample_csv.csv'
filtered_csv_path = os.path.join(filtered_csv_dir, filtered_csv_filename)
# CSVファイルの読み込み
df = pd.read_csv(filtered_csv_path)
# name列のデータを置換
fruit_name_mapping = {
1: "バナナ",
2: "りんご",
3: "レモン",
4: "もも",
5: "オレンジ",
6: "マンゴー"
}
df['name'] = df['name'].map(fruit_name_mapping)
# color列のデータを置換
color_mapping = {
1: "黄色",
2: "赤色",
3: "ピンク色",
4: "オレンジ色"
}
df['color'] = df['color'].map(color_mapping)
# 列名を変更
df.rename(columns={
'name': 'フルーツ名',
'color': '色',
'quantity': '数量'
}, inplace=True)
# 結果を同じCSVファイルに書き出し
df.to_csv(filtered_csv_path, index=False)
サンプルコード解説
1. read_csv関数を使用してDataFrameとして読み込む
まず、データ分析を行うライブラリpandasのread_csv関数を使用して、指定したパスのCSVファイルを読み込み、それをpandasのDataFrameにしています。DataFrameとは、pandasで扱うデータ構造です。
Pandas DataFrame とは、表形式のデータを表示、操作する方法の一つです。二次元のデータ構造で、データを行と列に整理してテーブルとして表示します。DataFrame は、ゼロから作成することも、NumPy 配列のような他のデータ構造を利用することも可能です。
引用元:pandas DataFrame - Databricks
2. map関数と辞書を利用してマッピングを作成する
その後、特定の数値をフルーツの名前や色(置換したい言葉)にマッピングするため、辞書を作成。
そしてdf['name'].map(fruit_name_mapping)とdf['color'].map(color_mapping)を使用して、'name'列と'color'列の数値をそれぞれ対応するフルーツの名前や色に置換します。ここで使われたmap関数とは、各要素に対して辞書に基づいて値を変換したりできる関数。辞書のキーが列の元の値と一致し、そのキーに対応する辞書の値が新しい値となります。
つまり、上記の例で言えば、'name'列の1がバナナに置換される、ということです。
3. renameメソッドで列名を変更する
列名の変更については、df.renameを使用します。これはDataFrameの行名や列名を変更するために使用されるメソッドです。ここでも置換したい言葉を辞書型で指定してあげます。
ここのinplace=Trueとは、新しいDataFrameを返さずに元のDataFrameを直接変更することを意味しています。つまり、CSVファイルの列名を直接置換したい場合は、ここでTrueを指定してあげないといけません。
4. to_csvメソッドでCSVファイルに書き出す
最後に、df.to_csvを使用して、変更を加えたDataFrameを同じCSVファイルに書き出します。ちなみに、index=Falseは、DataFrameのインデックスをCSVファイルに書き出さないことを指定しています。
index=Trueにして書き出すと以下のようになります。
インデックスが必要な際はこちらを指定すると良いですね。