はじめに
背景と目的
「RAG から AI Agent へ」「2025 年は AI Agent 元年」といったフレーズを耳にすることが増え、この一年で企業の実運用例も少しずつ現れ始めました。AI Agent が急速に身近になりつつある一方で、実は私自身、AI Agentをきちんと実装したことはまだありません。そこで今回はキャッチアップを兼ねて、実際に動くプロトタイプを自分の手で作ってみることにしました。
Agent開発を支援するフレームワークは数多くありますが、今回はワークフローを有向グラフとして宣言的に記述でき、LangChain エコシステムとの親和性も高い LangGraph を採用しています。
題材は、日常生活で役立ちそうな「朝の情報収集」タスクです。生成 AI 関連のニュースや最新論文は毎日のように増え続けており、私もキャッチアップに多くの時間を割かれていました。そこで 情報収集 → 要約 → 音声化 の一連の流れを完全自動化し、起床直後や通勤前に音声でサクッとインプットできる仕組みを構築した過程を紹介します。
グラフ構成と詳細
まず全体像からお伝えします。以下はLangGraphで構築したワークフロー(グラフ)の全体像を示したものです。各ノードがそれぞれの処理ステップ(機能)を表し、矢印は処理の流れ(依存関係)を示しています。本システムでは、状態付きのエージェントをLangGraphで実装しており、ノード間で共有される state(状態)にニュース記事や要約結果などのデータを保持しながら処理が進みます。
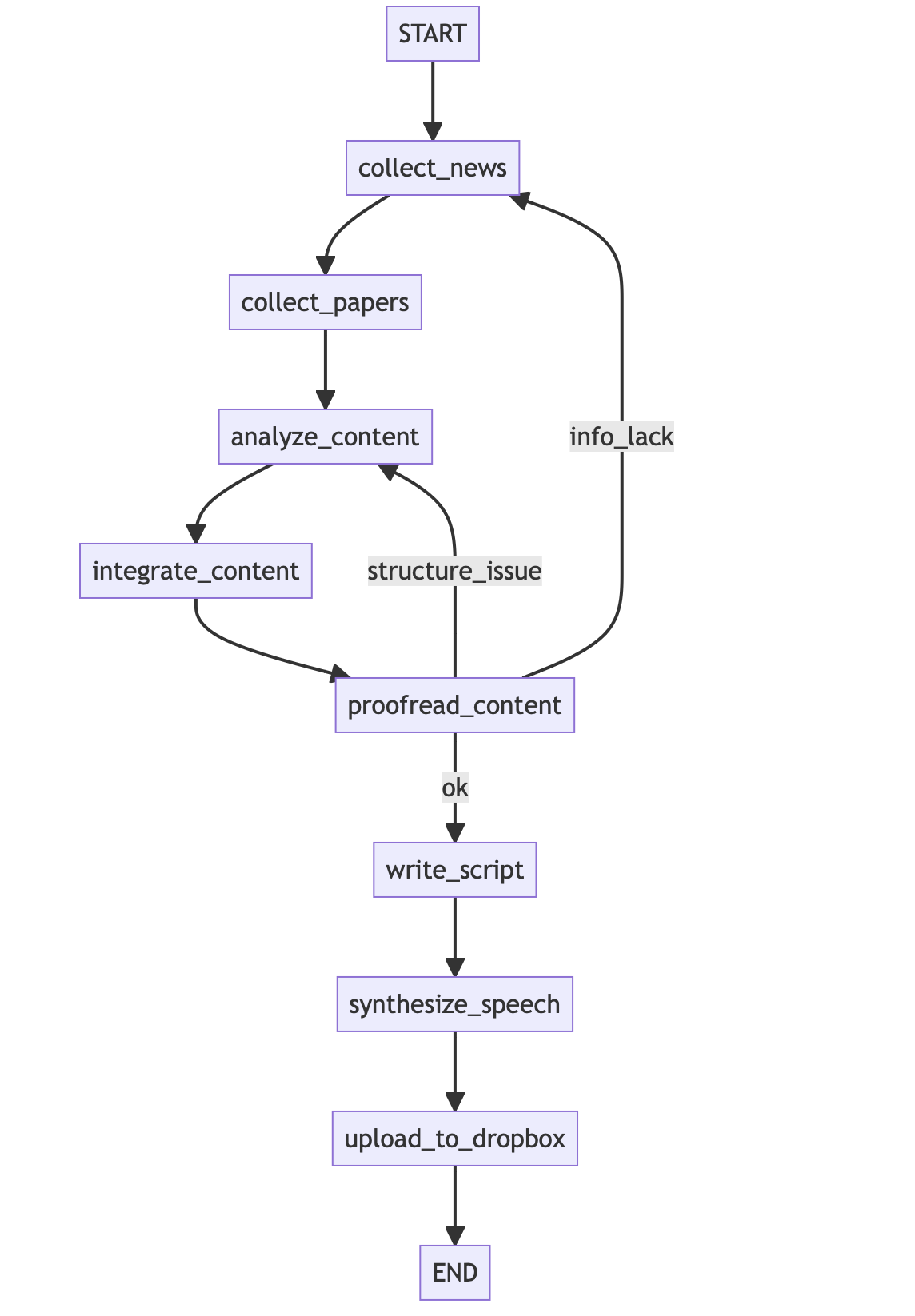
主な処理の流れは次のとおりです。少し長いのでトグルで記載します。
1. collect_news_情報収集(ニュース)
- 最初のノードcollect_newsでは、NHKや日経新聞、ITmediaなど複数のニュースサイトのRSSフィードから記事を取得します
- ここでは事前に設定したキーワードやテーマ(例:「生成AI」)にマッチするニュースのみを抽出しています。
2. collect_papers_情報収集(論文)
- 次のノードcollect_papersでは、学術文献データベース(PubMed)とプレプリントサーバ(arXiv)から、指定したキーワードに関する最新の論文要旨を取得します
- PubMedとarXivそれぞれに対してREST APIやフィードを用い、生成AIに関係する論文タイトル・概要を上位数件ずつ収集します
3. analyze_content_要約
- ノードanalyze_contentでは、収集したニュース記事本文や論文概要を1件ずつLLMに送り、2~4文程度の短い要約を生成します
- OpenAIのAPIを利用し、各アイテム(ニュース・論文)について「JSON形式で要約文のみ出力せよ」というプロンプトを与えることで、後段で扱いやすい構造化データとして要約結果を取得しています
- この要約ステップにより、生データが簡潔なポイントだけのリストに変換され、後続の処理がシンプルになります
4. integrate_content_統合
- ノードintegrate_contentでは、ニュース要約と論文要約を統合するとともに、付加情報として天気と株価を取得してstateに追加します
- 具体的には、Open-MeteoのAPIから当日朝の東京の天気予報・気温を取得し、日本経済新聞社の株価指数(日経平均)をyfinance経由で取得します(前日終値を読み上げる)
- 取得した天気・株価情報は短いテキスト文にまとめ、要約コンテンツ群(ニュース・論文)と一緒にstate内へ格納します
5. proofread_content_内容チェック
- ノードproofread_contentでは、集められた情報量や構成に問題がないかを確認します
- ニュース件数が極端に少ない場合は info_lack(情報不足)フラグを立て、またニュースと論文の一覧タイトルを列挙しGPTに「構成に違和感があるか?問題なければok、違和感あればstructure_issueと答えて」と指示するプロンプトを送ります
- GPTから返された結果に応じて、構成上の問題が検出された場合は後続フローを分岐させます(後述)
6. write_script_原稿作成
- ノードwrite_scriptでは、以上でまとめられた情報をもとに 最終的なニュース原稿テキスト を生成します
- ここでもOpenAI APIを活用し、「おはようございます」で始まり天気→株価→ニュース→論文の順に内容を紹介し、最後は「今日も一日頑張りましょう。」といった締めで終わる、一連のニュース原稿を作成します
- プロンプトには箇条書き形式のデータ(天気・株価情報、各ニュースタイトルと要約、各論文タイトルと要約)を与え、朝のニュース番組アナウンサーになりきって原稿を書くよう指示しています
- こうすることで、単なる箇条書きの羅列ではなく文脈が通った自然な読み上げ原稿を得ることができます
7. synthesize_speech_音声合成
- ノードsynthesize_speechでは、完成したニュース原稿テキストを音声ファイル(MP3)に変換します
- ここで OpenAIのText-to-Speech API を使用し、モデルtts-1と音声スタイル"fable"を指定して日本語テキストから合成音声を生成しています
- OpenAIのTTSモデルでは複数の話者スタイル(声質)が提供されており、好きな音声を選択できます [1]
- 生成された音声データはファイルmorning_news.mp3に保存します
8. upload_to_dropbox_共有
- 最後のノードupload_to_dropboxでは、生成された音声ファイルをクラウドストレージ(Dropbox)にアップロードし、共有用の公開リンクを取得します
- Dropbox APIを使用してファイルをアップし、古いファイルは自動削除して常に最新の1件のみを保存、続いて共有リンク(URL)を生成してstateに保持します
LangGraphとOpenAI API(tts-1)の補足
LangGraph

LangGraphはLLMを用いた複雑な処理をグラフ構造で記述するためのフレームワークです。今回のように「情報を集めて→要約して→チェックして→別のAIに文章化して…」といった一連の処理をモジュール化し、かつ状態管理(メモリ)を伴うケースでは、単純な関数の呼び出しよりもLangGraphのような仕組みが威力を発揮します。
LangGraph上で定義した各ノードは、内部ではPython関数(今回作成した各nodes/*.pyモジュールの関数)として実装されており、ノード間のデータ受け渡しはすべて一つのstateオブジェクト(辞書型)経由で行われます。これにより、処理の途中経過や最終結果までを含めて 全体の状態を一箇所で管理できるため、長い処理フローでも見通しがよく、再現性のある処理が可能になります。 [2]
OpenAI API

OpenAI APIは、テキスト生成(チャット補完)と音声合成の双方に対応しています。テキストの要約や原稿作成にはGPT-4を使用しました。
一方、音声合成にはOpenAIのText-to-Speechモデル(今回はtts-1)を利用しています。なお、音声モデルは話者のキャラクターをある程度指定可能です。[3]
日本語テキストも問題なく合成可能で、今回も日本語のニュース原稿をそのままAPIに渡して音声出力しています。
実装
APIキーや環境構築の事前準備
本システムを動作させるために必要な事前準備としては以下が挙げられます。
- OpenAI APIキーの用意:
- APIキーを取得し、環境変数OPENAI_API_KEYにAPIキーを設定するか、.envファイルに記載しておき、コード内で読み込むようにします
- Dropboxアクセストークンの用意:
- 音声ファイルをアップロードする先としてDropboxを使う場合、予めDropboxのAppを作成し発行されたアクセストークン(DROPBOX_TOKEN)を取得しておきます。これも環境変数か.envでコードから参照できるようにします [4]
- ライブラリのインストール:
- 以下の必要なライブラリをインストールします
-
requirements.txt
langgraph openai dropbox feedparser typing_extensions dotenv yfinance IPython
- ファイル構成:
- Pythonスクリプトを機能ごとに分割して作成します。main.pyから各ノード用関数をインポートする形でディレクトリ構成しました
- 実行環境の整備:
- テスト時は手動でスクリプトを実行すれば動作確認できます。本番運用として毎朝自動実行する場合、今回はmacOSのlaunchdを使いました
各Pythonファイルの役割
それでは、実装した各Pythonスクリプトの役割を簡単に整理します。今回は処理内容ごとにファイルを分け、ノード名=関数名 となるよう構成しました。以下にファイル名とその機能を表形式でまとめます。
| ファイル名 | 役割・機能概要 |
|---|---|
| main.py | LangGraph のグラフ定義と実行を行うメインスクリプト。各ノード関数をインポートして StateGraph に追加し、エッジを定義。 |
| nodes/collect_news.py | ニュース記事収集ノード。複数の RSS から記事を取得し、テーマ/キーワードに合致したものを抽出。結果を state["news_items"] に格納。 |
| nodes/collect_papers.py | 論文情報収集ノード。PubMed と arXiv からキーワード検索し、タイトルと Abstract を取得。結果を state["papers"] に格納。 |
| nodes/analyze.py | コンテンツ要約ノード。ニュース本文と論文要旨をで要約し "summary" フィールドを追加して上書き。 |
| nodes/integrate.py | 情報統合ノード。天気・株価を取得して state["weather_info"] と state["stock_info"] に保存。ニュース・論文を統合し state["combined_items"] に格納。 |
| nodes/proofread.py | 内容チェックノード。件数不足なら info_lack、構成違和感なら structure_issue を判定し state["review_result"] に保存。 |
| nodes/write_script.py | 原稿作成ノード。天気・株価・要約を入力に GPTでニュース原稿を生成し state["final_script"] に保存。 |
| nodes/text_to_speech.py | 音声変換ノード。OpenAI TTS で原稿を MP3 に変換し state["audio_path"] に設定。 |
| nodes/upload_dropbox.py | アップロードノード。音声ファイルを Dropbox にアップし共有リンクを state["share_url"] に保存。旧ファイルを自動クリーンアップ。 |
スクリプトの一部 (main.py)
上記の実装の中からポイントとなるコードスニペットやプロンプトの例をいくつか紹介します。 まず、LangGraphのグラフ定義部分のコードです。main.pyでは、前述の通りノードとエッジを定義してワークフローを構築しています。以下はその一部抜粋です。
# ノードの登録
graph_builder = StateGraph(MorningNewsState)
graph_builder.add_node("collect_news", collect_news)
graph_builder.add_node("collect_papers", collect_papers)
... # 中略: 他のノードも同様に登録
graph_builder.add_node("upload_to_dropbox",upload_to_dropbox)
# エッジの定義(処理フローの順序)
graph_builder.add_edge(START, "collect_news")
graph_builder.add_edge("collect_news", "collect_papers")
graph_builder.add_edge("collect_papers", "analyze_content")
... # 中略: 一連の直線的なフロー
graph_builder.add_edge("synthesize_speech","upload_to_dropbox")
graph_builder.add_edge("upload_to_dropbox",END)
# 条件分岐の定義
graph_builder.add_conditional_edges(
"proofread_content",
decide_next, # 関数:stateから次ノード名を返す
{"analyze": "analyze_content", "collect": "collect_news", "ok": "write_script"}
)
iPhoneおよびPCの設定
PC側(スクリプト実行の自動化)
毎朝決まった時刻に自動でmain.pyを実行するため、macOSの launchd を利用しました。LaunchAgent用のプロパティリストファイル(例:com.user.morningnews.plist)を作成し、StartIntervalやStartCalendarIntervalで実行時間(例えば毎朝7:30)を指定します。
作成したplistファイルを~/Library/LaunchAgents/に配置し、ターミナルからlaunchctl load -w ~/Library/LaunchAgents/com.user.morningnews.plistでロードすればスケジュール実行が登録されます。
iPhone側(音声の自動再生)
私はiPhoneユーザーなのでiPhoneで毎朝鳴らせるような設定を記載します。
生成された音声ニュースをiPhoneで手軽に再生するために「朝のAIニュースを再生」といったカスタムショートカットを作成します。
このショートカットを個人用オートメーションで「朝8時になったら実行」のようにスケジューリングしておけば、時間になると自動でDropboxから最新の音声ニュースを取得して再生してくれます。今回はDropboxを介しましたが、iCloudドライブへ出力するようにしてショートカットから読み上げても同様のことが可能です。
以上により、朝起きてから人手を介さずに 「最新のAIニュース音声」を聞く という流れが実現しました。AI Agentにより自動で情報収集・要約・音声化まで行い、スマートフォンが自動でそれを取得して再生してくれるため、自身もコーヒーを淹れている間に今日のトピックをざっと把握できて非常に快適です。
生成されたスクリプト
以下はdropboxに保存されたmp3の例です。ここでは2~3分程度の音声ファイルが生成され、dropboxを介してiPhoneから聞くことができました。

Agent設計の重要性
AI Agent を組むうえでは「どのような処理を、どの順序で、どの粒度で回すか」などの設計思想が非常に重要です。とりわけLangGraphのようにフローを有向グラフとして記述できる環境では、ノード(処理)をどこでループさせるか、ループの終了条件をどこまで厳密に定義するか、失敗時にどのノードまで巻き戻すかなど、分岐や再試行の設計がそのまま回答速度と結果品質に跳ね返ります。実際に今回の実装もまだまだ改良の余地がありそうです。
また、設計段階からグラフの可視化ツールを並行して使い、実際の処理経路を目で追える状態にしておくことも重要です。可視化があると、ループや条件分岐を増減させたときの影響範囲を即座に把握でき、チューニングの試行錯誤が格段に効率化します。
一方で、AI Agent にすべてを任せきりにするのではなく、取得した情報源や生成された文章をバージョン管理し、人間が判断できるフローを挟むことも欠かせません。ソースの信頼性を確認できるなどのフローを用意しておくことで、品質担保と監査性の両立が図れます。
今回は「LangGraphに慣れる」ことが主目的だったため最小構成にとどめましたが、将来的には Model‑Context Protocol (MCP) や Agent2Agent (A2A) といった周辺技術を組み合わせることで、エージェント同士の協調や複雑なリソース操作をさらに効率化できるだろうと思います。
参考URL
[1] https://platform.openai.com/docs/guides/text-to-speech
[2] https://www.langchain.com/langgraph
[3] https://openai.com/index/introducing-our-next-generation-audio-models
[4] https://www.dropbox.com/developers