はじめに
背景と目的
大規模言語モデル(LLM)の活用が進むにつれ、モデルのさらなる性能向上にはより多くのデータが必要とされています。しかし、高品質なオープンデータには限りがあり、数年以内に枯渇する可能性さえ指摘されています。[1]
一方で、医療・法律・金融といったドメイン固有の知識や企業内の業務データは、公に利用できるウェブデータには含まれていないケースが多く、モデルを専門領域に特化させるにはそうした非公開データの活用が不可欠です。
しかし企業内データは機密性が高く、社外への持ち出しが難しいため、モデル学習のためといっても安易にクラウドにアップロードすることはできません。また、Retrieval Augmented Generation(RAG)のように外部データベースから知識を検索してモデルに与える手法もありますが、モデル自体がドメイン知識を学習していない場合は期待した効果が出ないこともあります。
こうした状況で、データを手元から出さずに学習を進めることができる「連合学習(Federated Learning; FL)」は、その選択肢の一つとして挙げられます。
本記事では、この連合学習とLLMのFine-Tuningを組み合わせ、オープンソースのフレームワークであるFlowerとLoRAを用いたFederated Fine-Tuningの実装方法とその意義について解説します。
連合学習とは
連合学習(Federated Learning; FL)とは、複数のクライアント(例:スマートフォンやエッジサーバなど)がそれぞれ手元のデータを使ってモデルを学習し、更新したパラメータだけを中央サーバに送信することで、全体として一つのグローバルモデルを構築する手法です。
ポイントは「生のデータを共有しない」という点にあります。各クライアントはデータを外部に出さずに学習を行い、得られたモデルの更新情報(パラメータ)だけをサーバに集めます。サーバは集まったパラメータを統合して新しいグローバルモデルを作り、再び各クライアントへ配布します。こうしてデータの機密性を保ったまま、複数のクライアントが共同で性能の高いモデルを作り上げられることが大きな特徴です。
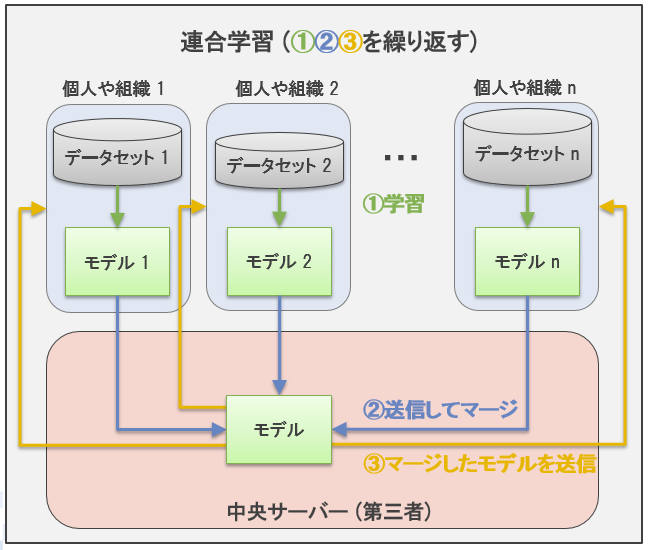
※連合学習とは?Federated Learningの基礎知識をわかりやすく解説から引用。
Flowerとは
Flowerは、Pythonベースのオープンソースフレームワークで、連合学習の構築をシンプルにしてくれるツールキットです。Flowerを使うと、サーバ・クライアント間の通信や重みの配布・集約といった処理が抽象化され、開発者は学習したいモデルやデータセットの部分に専念することができます。特徴として、非常に柔軟かつ拡張性の高い設計で、PyTorchやTensorFlowなど主要な機械学習ライブラリと簡単に統合できるフレームワーク非依存な作りになっています。[2][3]
![]()
Fine-Tuningとは
Fine-Tuningは、あらかじめ大規模データで学習されたモデルに対して、特定のタスクや目的に合わせて追加の学習を行いモデルを微調整する手法です。この中でも教師あり微調整(Supervised Fine-Tuning; SFT)と呼ばれる方法は、モデルに対してラベル付きデータで追加学習を行うことで、下流タスクへの適応を図ります。[4]
連合学習 × Fine-Tuning検証
それでは具体的な実装に移ります。ここでは、FlowerとLoRAを使い、2クライアントによるシンプルな連合学習下でのLLM SFTをシミュレーションします。各クライアントは自分のデータでLoRA付きLLMをSFTし、その重み更新だけをサーバで集約してグローバルモデルを更新します。以下では、データセットの準備からモデルへのLoRA適用、Trainer、そしてFlowerクライアントの定義まで、主要なポイントをコード抜粋とともに解説します。
実行環境と前提
- 環境:Google Colab (GPU: A100)
- データ: ichikara-instruction の一部 [5]
- モデル: deepseek-ai/DeepSeek-R1-Distill-Qwen-1.5B [6]
LoRA モデルの準備
データセットが準備できたという前提で、LoRAモデルの準備を進めます。
4bit 量子化の設定
今回は 4bit 量子化 (BitsAndBytes) を有効にして、GPU メモリを節約しながらモデルを扱います。
quantization_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_quant_type="nf4",
bnb_4bit_compute_dtype=torch.bfloat16,
)
トークナイザとベースモデルのロード
トークナイザとベースモデルをロードします。device_map="auto" で自動的に GPU に割り当てる形としています。
model_name = "deepseek-ai/DeepSeek-R1-Distill-Qwen-1.5B"
tokenizer = AutoTokenizer.from_pretrained(model_name, trust_remote_code=True)
if tokenizer.pad_token_id is None:
tokenizer.pad_token_id = tokenizer.eos_token_id
base_model = AutoModelForCausalLM.from_pretrained(
model_name,
device_map="auto",
quantization_config=quantization_config,
trust_remote_code=True,
)
LoRA 設定と適用
ハイパーパラメータは参考程度で適宜置き換えてください。
lora_config = LoraConfig(
r=8,
lora_alpha=32,
target_modules=["q_proj", "v_proj"],
lora_dropout=0.05,
bias="none",
task_type="CAUSAL_LM"
)
peft_model = get_peft_model(base_model, lora_config)
Flower クライアントの定義
連合学習で使う Flower のクライアント クラスを定義します。簡単に、以下の構造となっています。
- get_parameters(): LoRA の差分パラメータを抽出して送信する
- set_parameters(): サーバ側から受け取ったパラメータを LoRA 層に反映する
- fit(): ローカルの学習を実行し、更新後のパラメータを返す
このように 差分パラメータだけをやりとりすることで、連合学習時の通信負荷を大幅に抑えることができます。
# ==============================
# Flower クライアントの定義
# ==============================
class LoRAFlwrClient(fl.client.NumPyClient):
def __init__(self, model, tokenizer, raw_dataset):
"""
model: LoRA 適用済みのモデル (peft_model)
tokenizer: トークナイザ
raw_dataset: クライアント側で使用する「text」を含む学習データ (まだトークナイズ前)
"""
self.model = model
self.tokenizer = tokenizer
# --- ① データセットをトークナイズして Dataset 化 ---
self.train_dataset = raw_dataset.map(
self._tokenize_and_format,
batched=False,
remove_columns=raw_dataset.column_names
)
# ② SFTTrainer設定: tokenizer と train_dataset に「すでにトークナイズ済み」のデータを渡す
self.trainer = SFTTrainer(
model=self.model,
args=trainer_args,
tokenizer=self.tokenizer,
train_dataset=self.train_dataset,
)
def _tokenize_and_format(self, example):
"""各サンプルをトークナイズし、input_ids/attention_mask/labelsを作成"""
text = example["text"]
encodings = self.tokenizer(
text,
truncation=True,
max_length=512,
padding="max_length"
)
encodings["labels"] = encodings["input_ids"][:]
pad_id = self.tokenizer.pad_token_id
encodings["labels"] = [
-100 if token_id == pad_id else token_id
for token_id in encodings["labels"]
]
return encodings
def get_parameters(self, config):
# LoRA の重みだけ取り出して返す
lora_state_dict = get_peft_model_state_dict(self.model)
return [val.cpu().numpy() for _, val in lora_state_dict.items()]
def set_parameters(self, parameters: NDArrays):
# 受け取った numpy リストをもとの state_dict 形式に戻す
new_state_dict = {}
lora_state_dict = get_peft_model_state_dict(self.model)
for (k, v), np_val in zip(lora_state_dict.items(), parameters):
new_state_dict[k] = torch.from_numpy(np_val).to(v.device)
set_peft_model_state_dict(self.model, new_state_dict)
def fit(self, parameters: NDArrays, config):
# サーバから送られてきた最新パラメータを適用
self.set_parameters(parameters)
# ローカルでの学習を実行 (SFTTrainer)
self.trainer.train()
# 学習後のパラメータを返す
updated_params = self.get_parameters(config={})
num_examples = len(self.train_dataset)
return updated_params, num_examples, {}
def evaluate(self, parameters: NDArrays, config):
# 受け取ったパラメータを適用
self.set_parameters(parameters)
# 簡易的な評価: ここでは同じデータセット使っているが、本来は分けたほうが良い
eval_results = self.trainer.evaluate(eval_dataset=self.train_dataset)
loss = eval_results["eval_loss"]
num_examples = len(self.train_dataset)
return float(loss), num_examples, {"eval_loss": float(loss)}
クライアント生成関数
本番環境では実際に別々の物理クライアントで動作するイメージですが、今回のシミュレーションではデータを擬似的に切り分けて実行します。クライアントごとにベースモデルをロードし、同じ LoRA 設定を適用します。しかし実際の学習データは異なるため、各クライアントが保持するデータ分布に合わせてLoRAが局所的にアップデートされます。
def client_fn(cid: str) -> fl.client.Client:
"""
cid: クライアントID (文字列)
本来ならcidによって異なるデータセットを用意して返す
"""
# ここでは例として 100件中前半50件をクライアント0、後半50件をクライアント1とする
if cid == "0":
client_dataset = dataset.select(range(0, 50))
else:
client_dataset = dataset.select(range(50, 100))
# クライアントごとに LoRA 付きの新しいモデルインスタンスを作成
local_model = AutoModelForCausalLM.from_pretrained(
model_name,
device_map="auto",
quantization_config=bnb_config,
trust_remote_code=True
)
local_model = get_peft_model(local_model, lora_config)
# このクライアント用のLoRAFlwrClientを返す
local_trainer_client = LoRAFlwrClient(local_model, tokenizer, client_dataset)
return local_trainer_client
シミュレーション実行
最後に、Flower が提供する start_simulation を呼び出して、連合学習を始めます。ここではクライアント数を num_clients=2 にし、連合学習を 2ラウンド (num_rounds=2) だけ実行してみます。
# シミュレーション開始
history = fl.simulation.start_simulation(
client_fn=client_fn,
num_clients=2, # クライアント数
config=fl.server.ServerConfig(num_rounds=2), # ラウンド数
client_resources={"num_gpus": 1},
)
(学習ログ抜粋) 実際に上記コードを動かすと、各ラウンドで以下のようなログが出力されます:
学習ログ抜粋
INFO : Received initial parameters from one random client
INFO : Starting evaluation of initial global parameters
INFO : Evaluation returned no results (`None`)
INFO :
INFO : [ROUND 1]
INFO : configure_fit: strategy sampled 2 clients (out of 2)
(ClientAppActor pid=28014) WARNING : DEPRECATED FEATURE: `client_fn` now expects a signature `def client_fn(context: Context)`.The provided `client_fn` has signature: {'cid': <Parameter "cid: str">}. You can import the `Context` like this: `from flwr.common import Context`
(ClientAppActor pid=28014)
(ClientAppActor pid=28014) This is a deprecated feature. It will be removed
(ClientAppActor pid=28014) entirely in future versions of Flower.
(ClientAppActor pid=28014)
Map: 100%|██████████| 50/50 [00:00<00:00, 1541.12 examples/s]
Truncating train dataset: 100%|██████████| 50/50 [00:00<00:00, 13072.07 examples/s]
(ClientAppActor pid=28014) No label_names provided for model class `PeftModelForCausalLM`. Since `PeftModel` hides base models input arguments, if label_names is not given, label_names can't be set automatically within `Trainer`. Note that empty label_names list will be used instead.
(ClientAppActor pid=28014) WARNING : Deprecation Warning: The `client_fn` function must return an instance of `Client`, but an instance of `NumpyClient` was returned. Please use `NumPyClient.to_client()` method to convert it to `Client`.
0%| | 0/50 [00:00<?, ?it/s]
2%|▏ | 1/50 [00:00<00:34, 1.41it/s]
4%|▍ | 2/50 [00:00<00:21, 2.28it/s]
6%|▌ | 3/50 [00:01<00:16, 2.81it/s]
8%|▊ | 4/50 [00:01<00:14, 3.27it/s]
(ClientAppActor pid=28014) {'loss': 4.6639, 'grad_norm': 11.209097862243652, 'learning_rate': 9e-05, 'num_tokens': 10.0, 'mean_token_accuracy': 0.0, 'epoch': 0.1}
10%|█ | 5/50 [00:01<00:12, 3.57it/s]
12%|█▏ | 6/50 [00:01<00:12, 3.62it/s]
14%|█▍ | 7/50 [00:02<00:12, 3.55it/s]
16%|█▌ | 8/50 [00:02<00:11, 3.76it/s]
18%|█▊ | 9/50 [00:02<00:10, 3.88it/s]
(ClientAppActor pid=28014) {'loss': 3.5558, 'grad_norm': 15.4932222366333, 'learning_rate': 8e-05, 'num_tokens': 20.0, 'mean_token_accuracy': 0.1, 'epoch': 0.2}
20%|██ | 10/50 [00:02<00:10, 3.77it/s]
22%|██▏ | 11/50 [00:03<00:10, 3.80it/s]
24%|██▍ | 12/50 [00:03<00:09, 3.96it/s]
26%|██▌ | 13/50 [00:03<00:09, 4.07it/s]
28%|██▊ | 14/50 [00:03<00:08, 4.15it/s]
(ClientAppActor pid=28014) {'loss': 2.3708, 'grad_norm': 6.1437764167785645, 'learning_rate': 7e-05, 'num_tokens': 30.0, 'mean_token_accuracy': 0.5, 'epoch': 0.3}
30%|███ | 15/50 [00:04<00:08, 4.16it/s]
32%|███▏ | 16/50 [00:04<00:08, 4.17it/s]
34%|███▍ | 17/50 [00:04<00:07, 4.18it/s]
36%|███▌ | 18/50 [00:04<00:07, 4.19it/s]
38%|███▊ | 19/50 [00:05<00:07, 4.21it/s]
(ClientAppActor pid=28014) {'loss': 1.9954, 'grad_norm': 6.959712028503418, 'learning_rate': 6e-05, 'num_tokens': 40.0, 'mean_token_accuracy': 0.5, 'epoch': 0.4}
40%|████ | 20/50 [00:05<00:07, 4.26it/s]
42%|████▏ | 21/50 [00:05<00:06, 4.27it/s]
44%|████▍ | 22/50 [00:05<00:06, 4.29it/s]
46%|████▌ | 23/50 [00:06<00:06, 4.28it/s]
48%|████▊ | 24/50 [00:06<00:06, 4.30it/s]
(ClientAppActor pid=28014) {'loss': 1.855, 'grad_norm': 8.032913208007812, 'learning_rate': 5e-05, 'num_tokens': 50.0, 'mean_token_accuracy': 0.5, 'epoch': 0.5}
50%|█████ | 25/50 [00:06<00:05, 4.33it/s]
52%|█████▏ | 26/50 [00:06<00:05, 4.33it/s]
54%|█████▍ | 27/50 [00:06<00:05, 4.35it/s]
56%|█████▌ | 28/50 [00:07<00:05, 4.30it/s]
58%|█████▊ | 29/50 [00:07<00:04, 4.32it/s]
このようにして、データを中央に集めることなく複数拠点のデータでLLMのSFTを行うことができました。コードでは単純化のために様々な省略をしていますが、実際にはHugging FaceのTrainerやデータセットライブラリとFlowerとを組み合わせて、より大規模なモデルや現実的なデータセットを用いたFederated Fine-Tuningを行うことが可能です。
LLM × Federated Learning の可能性と課題
最後に、LLMと連合学習を組み合わせることのメリットと課題について整理します。
✅ 企業データを活かしやすくなる:
社内の秘匿データを外部に提供することなくモデル学習に組み込めるため、従来は活用が難しかった機密データから知見を引き出せることが期待できます。
✅ クライアント特化型のモデルも育てられる:
連合学習の枠組みを活かせば、グローバルモデルを共有しつつも各クライアントに特化したモデルを育成することも可能です。例えば全体で基礎能力を底上げしつつ、最終的には各クライアントが自分のLoRAアダプタを保持してローカルに最適化するような構成であれば、パーソナライズされたモデルを各社内で運用するといった柔軟な展開も考えられます。
⚠️ モデルサイズ・通信負荷の課題:
LLMはパラメータ数が膨大なため、そのモデル重みの通信コストが無視できません。LoRAのように更新パラメータを圧縮する手法はこの通信量削減に寄与しますが、それでも通信や同期に時間がかかる点は実運用上のボトルネックになりえます。またクライアント数が増えるとサーバ・クライアント間のやりとり自体が指数的に増えるため、効率的な通信戦略や分散最適化アルゴリズムの工夫が求められます。[7]
⚠️ 評価指標の設計や統合:
連合学習では各クライアントが固有のデータ分布を持つことが多く、グローバルモデルの性能を測る評価指標の設計にも注意が必要です。全体のテストデータを用意しにくい場合、各クライアントでの評価結果をどう集約するか、あるいはどの程度の性能差を許容するかといった課題があります。例えば一部のクライアントのデータに対しては性能が高いが別の一部では低い、といった場合にグローバルモデルをどう学習するかは検討すべきかと思います。
さいごに
連合学習はあくまでLLMをセキュアに学習するための選択肢の一つであり、必ずしも連合学習を使わなければならないわけではありません。実際、連合学習でも機密情報が推定されるリスクは指摘されているため、どのようにセキュリティを担保し、どう説明するかが最終的には重要になります。たとえば、オンプレミスなどセキュアな環境を自ら構築して学習するほうが、リスクを抑えられる場合もあるでしょう。
ただし、連合学習の考え方自体は、データセットが分割されて保管されていたり、知識が更新され続けたりするような状況では非常に有用です。
また、連合学習も他の手法も、あくまで目的を達成するための手段にすぎません。そのため、目的に応じて最適に使い分けることが求められます。
ここまでお読みいただきありがとうございました。本記事が、皆さまの取り組みにおける1つのアイデアとしてお役に立てば幸いです。
参考/引用文献
-
[1] "Will we run out of data? Limits of LLM scaling based on human-generated data" , https://arxiv.org/abs/2211.04325
-
[2] "Federated Fine-Tuning with Flower on Medical Datasets", https://medium.com/@massimo.scamarcia/federated-fine-tuning-with-flower-comparing-mistral-7b-instruct-v0-3-795ed88b2af5
-
[3] "Flower A Friendly Federated AI Framework", https://flower.ai/
-
[4] "Supervised Fine-tuning: customizing LLMs", https://medium.com/mantisnlp/supervised-fine-tuning-customizing-llms-a2c1edbf22c3
-
[5] "ichikara-instruction: LLMのための日本語インストラクションデータ", https://liat-aip.sakura.ne.jp/wp/llm%E3%81%AE%E3%81%9F%E3%82%81%E3%81%AE%E6%97%A5%E6%9C%AC%E8%AA%9E%E3%82%A4%E3%83%B3%E3%82%B9%E3%83%88%E3%83%A9%E3%82%AF%E3%82%B7%E3%83%A7%E3%83%B3%E3%83%87%E3%83%BC%E3%82%BF%E4%BD%9C%E6%88%90/
-
[6] "deepseek-ai/DeepSeek-R1-Distill-Qwen-1.5B", https://huggingface.co/deepseek-ai/DeepSeek-R1-Distill-Qwen-1.5B
-
[7] "Federated Learning: Risks and Challenges", https://www.edge-ai-vision.com/2025/01/federated-learning-risks-and-challenges/
-
連合学習とは?Federated Learningの基礎知識をわかりやすく解説, https://www.msiism.jp/article/federated-learning.html