なぜスクレイピングが必要なのか?
皆さん自分専用のニュースサイトを作れたら、面白いと思ったことはないですか?
自分の知りたい情報を一つ場所に集めることができれば、わざわざ複数のサイトをチェックしなくても、一度サイトを開けばそこで知りたいことがまとめて確認できます。
そのような技術をスクレイピングを使えば達成することができます。
目次
スクレイピングとは
スクレイピングを行うための環境
基本のコード
要素の指定
スクレイピングで画像urlを取得する方法
スクレイピングとは
スクレイピングとは“データを収集した上で利用しやすく加工すること”です。
スクレイピングを活用することにより、複数のwebページから自動で情報を収集することができます。
イメージとしては、ニュースアプリのように、複数のサイトから記事を取得するようなことができるようになります。
ただ、スクレイピングを利用するにあたって、著作権の問題に触れる場合もありますので、利用する際には、自己責任でお願いします。
スクレイピングを行うための環境
自分の環境としては、
・Rails 6.0.3.4
gem
・nokogiri
を利用しています。
nokogiriとは
nokogiriはスクレイピングを利用する方に愛用されているライブラリになります。
特徴としては、
-
HTMLやXMLの構造を解析して、特定の要素を指定しやすい形に加工できる
-
XpathやCSSセレクタを使った要素の抽出を行うことができる
という特徴があります。
nokogiriのインストール
nokogiriをインストールしていない人は、
①gemfileに
gem 'nokogiri'
の記述
②ターミナルで
bundle install
を実行します。
完了したら早速、スクレイピングのコードに入っていきましょう!
基本のコード
今回のコードの目的としては、ウェブサイトの記事から、タイトル名を取得し、ターミナルに表示するというところをゴールにします。
スクレイピング先のURL
url = 'https://news.yahoo.co.jp/pickup/6379353'
タイトルを表示するコードが、
puts doc.titleになります。
## URLにアクセスするためのライブラリの読み込み
require 'open-uri'
# Nokogiriライブラリの読み込み
require 'nokogiri'
# スクレイピング先のURL
url = 'https://news.yahoo.co.jp/pickup/6379353'
charset = nil
html = open(url) do |f|
charset = f.charset # 文字種別を取得
f.read # htmlを読み込んで変数htmlに渡す
end
# htmlをパース(解析)してオブジェクトを生成
doc = Nokogiri::HTML.parse(html, nil, charset)
# タイトルを表示
puts doc.title
ruby test.rb
で早速実行してみましょう
GoToトラベル 全国一斉停止へ - Yahoo!ニュース
という表示がされたら、OKです。
要素の指定
さて、ここで疑問なのですが、どうやって、
GoToトラベル 全国一斉停止へ - Yahoo!ニュース
という文章だけ取得することができたのでしょうか?
それを知るために、実際のウェブページを確認してみましょう。
https://news.yahoo.co.jp/pickup/6379353
ここを開くとを
こういうページが開きます。
この状態で、option+commnad+I(または右クリック→検証) で
検証モードに入ります。
検証モードに入ることで、そのウェブページがどういった構造で、形成されているかを確認することができます。
更に、その状態で commnad+f で検索モードに入ります。
検索モードでは、タグや、クラス名などを検索することができます。
そこで、 title と入力しましょう。
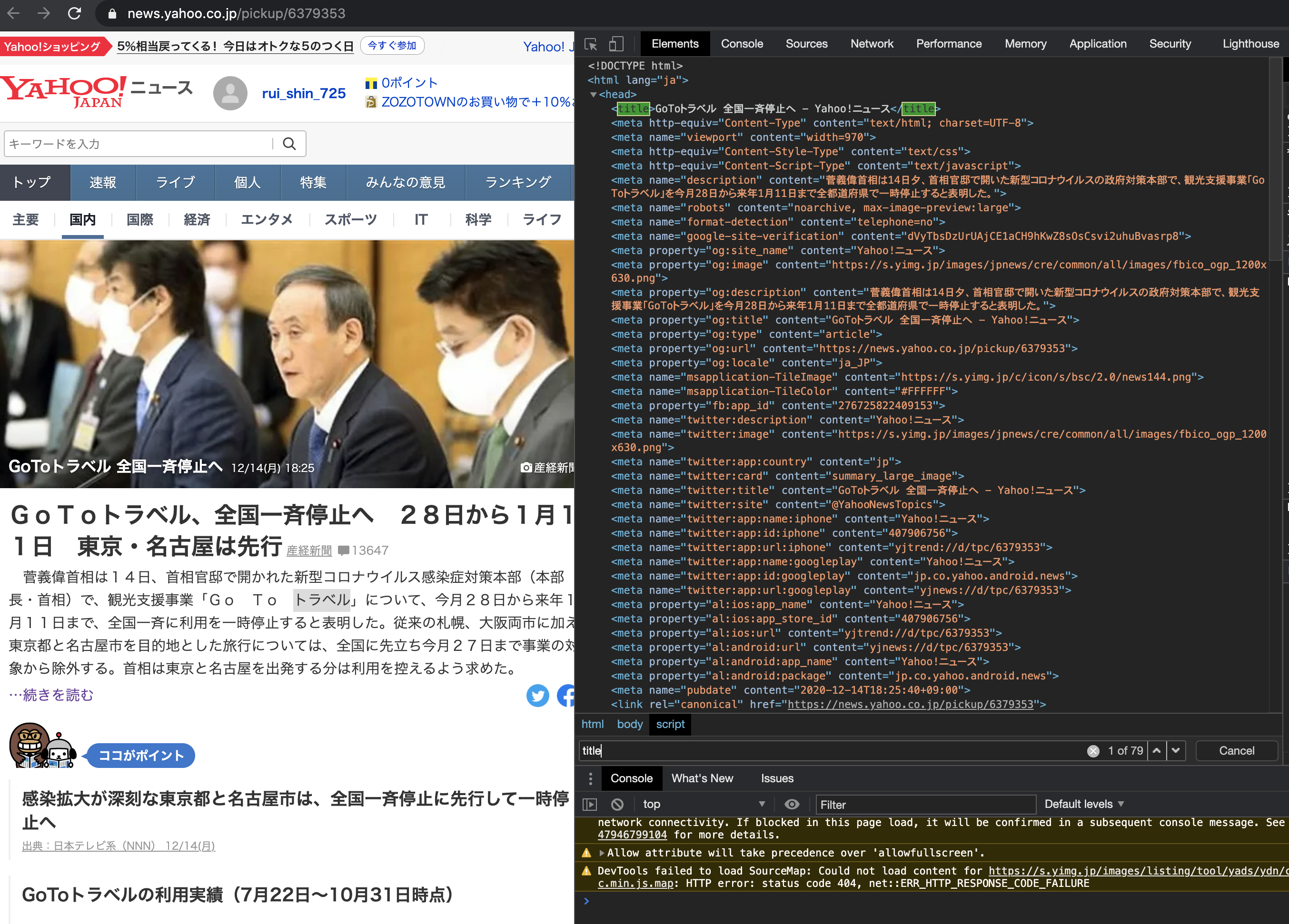
これで
<title>GoToトラベル 全国一斉停止へ - Yahoo!ニュース</title>
のところが表示されていることがわかります。
puts doc.titleのコードによってtitleタグ部分が表示されるという仕組みになります。
画像のurlをスクレイピング
①取得したいurlを探す
現状タイトルしか取得できていません。それだけだと寂しいですよね?
では、今度はこの記事の画像のurlを取得してみましょう。
この画像urlを検証モードで探すと、
pictureタグの中にurlがあります。
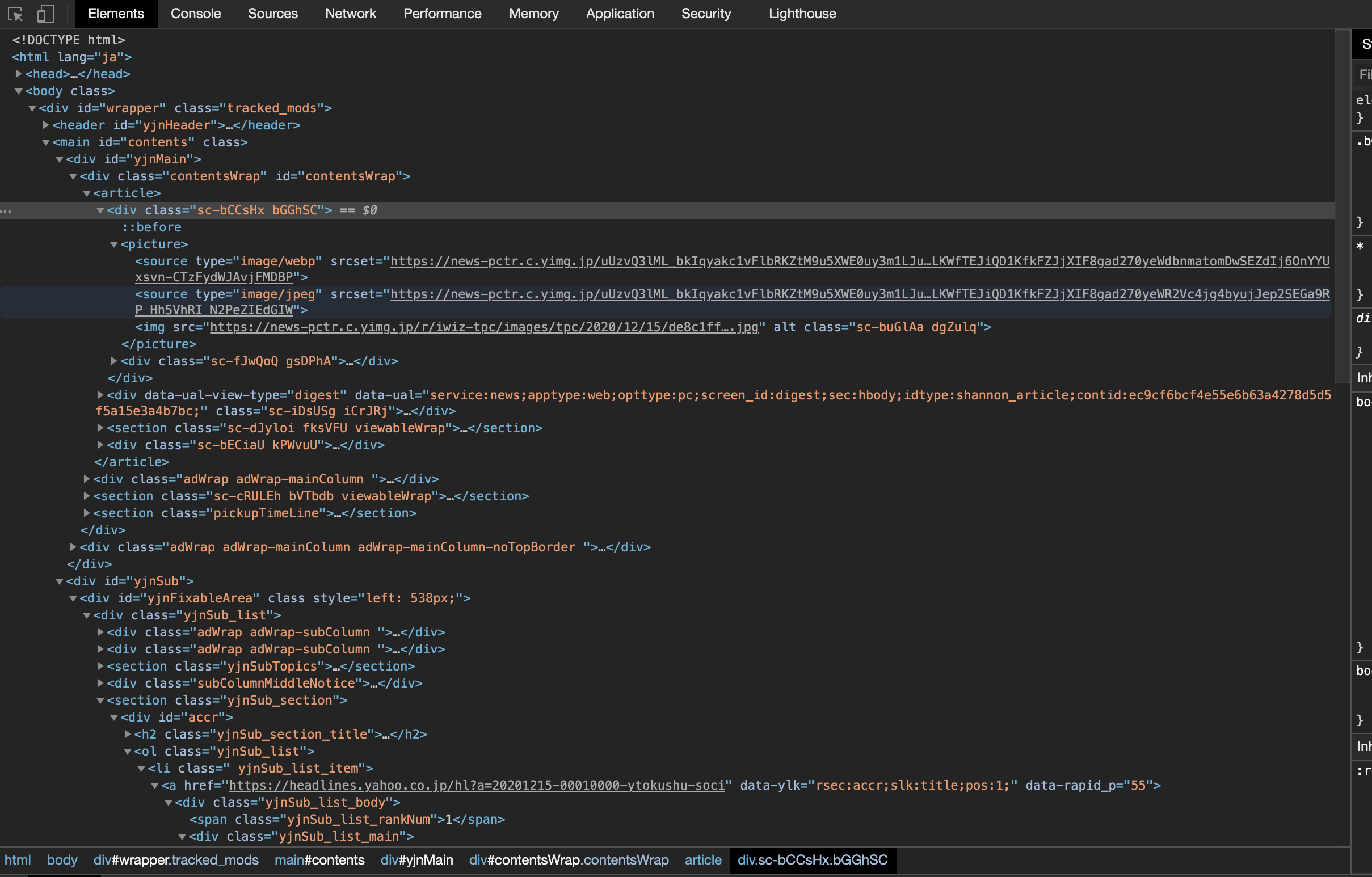
更にその中のsourceタグの srcset=から始まるurlが画像のurlになります。
https://news-pctr.c.yimg.jp/uUzvQ3lML_bkIqyakc1vFlbRKZtM9u5XWE0uy3m1LJuztN6ELHcFKk9pTEfyITR4BzJ1biS2jSO6TBCdnPY064ZSbL8zBcwbVjqsaTANu9SaNctFdKhJXbJzQWo0hYbEH_Nc43w2vFAKuJpoajK2cMY3ybCkqvM3BoAeliLf8Bc5nGoluBfd0XLKWfTEJiQD1KfkFZJjXIF8gad270yeWdbnmatomDwSEZdIj6OnYYUxsvn-CTzFydWJAvjFMDBP
これを取得してみましょう。
②doc.cssでurlを指定する
urlを取得する際に、利用するのがdoc.cssになります。
cssをつけることで、取得されたデータの内css情報で検索ができるようになります。
今回の画像urlは
<div class="sc-bCCsHx bGGhSC">が親になっていて、
その子が<picture>
更にその子が<source type="image/webp" srcset="https://news-p~~~
となっています。
なので、
doc.css("div.bGGhSC > picture > source[1]")
と記述することである程度画像urlの場所を絞り込むことができます。
ただ、まだこの状況では、画像urlだけに絞り込むことができていません。
どのような情報が含まれているのかbindig.pryで確認してみましょう。
③binding.pryで情報を絞り込む
現状url以外の情報が含まれている状況なので、binding.pryを利用して欲しい情報だけに絞り込みを行っていきます。
binding-pryをインストールしていない人は、ターミナルで
gem install pry-byebug
その後コード上に
require 'pry'を記載します。
これでbinding.pryが利用できるようになりました。
## URLにアクセスするためのライブラリの読み込み
require 'open-uri'
# Nokogiriライブラリの読み込み
require 'nokogiri'
require 'pry'
# スクレイピング先のURL
url = 'https://news.yahoo.co.jp/pickup/6379353'
charset = nil
html = open(url) do |f|
charset = f.charset # 文字種別を取得
f.read # htmlを読み込んで変数htmlに渡す
end
# htmlをパース(解析)してオブジェクトを生成
doc = Nokogiri::HTML.parse(html, nil, charset)
binding.pry
# 画像のurlを表示
puts doc.css("div.bGGhSC > picture > source[1]")
では早速実行してみましょう
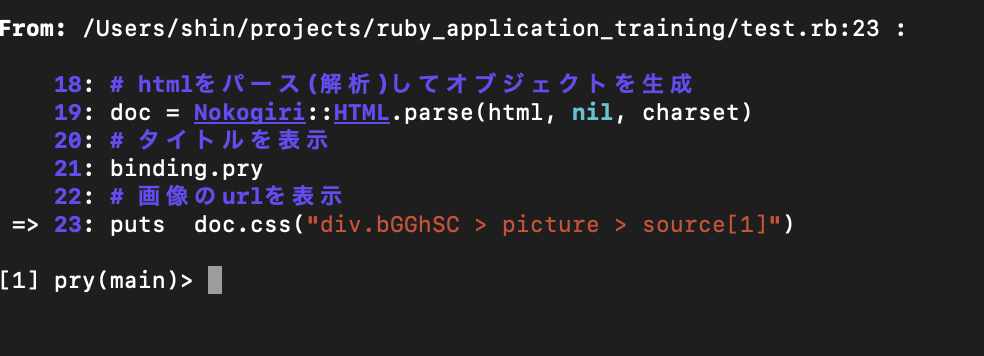
doc.css("div.bGGhSC > picture > source[1]")を入力します

すると、url以外の情報も出力されます
doc.css("div.bGGhSC > picture > source[1]").first
を入力しましょう。
.firstは配列の一番目という意味になります。先程の情報から一番目のものだけに情報を絞り込みます。

ここから更に
doc.css("div.bGGhSC > picture > source[1]").first.attributesで絞り込みます。

次にdoc.css("div.bGGhSC > picture > source[1]").first.attributes["srcset"]で絞り込みます。

最後に
doc.css("div.bGGhSC > picture > source[1]").first.attributes["srcset"].valueで絞り込みます。

これで指定する情報を画像urlだけに絞り込むことができました。
このように、binding.pryを使うことで、出力される情報をチェックし、自分が欲しい範囲の情報に絞り込むことができます。
④テストの実行
では最後にdoc.css("div.bGGhSC > picture > source[1]").first.attributes["srcset"].valueを実行し、画像のurlが出力されるかチェックします。
## URLにアクセスするためのライブラリの読み込み
require 'open-uri'
# Nokogiriライブラリの読み込み
require 'nokogiri'
require 'pry'
# スクレイピング先のURL
url = 'https://news.yahoo.co.jp/pickup/6379353'
charset = nil
html = open(url) do |f|
charset = f.charset # 文字種別を取得
f.read # htmlを読み込んで変数htmlに渡す
end
# htmlをパース(解析)してオブジェクトを生成
doc = Nokogiri::HTML.parse(html, nil, charset)
binding.pry
# 画像のurlを表示
puts doc.css("div.bGGhSC > picture > source[1]").first.attributes["srcset"].value
## URLにアクセスするためのライブラリの読み込み
require 'open-uri'
# Nokogiriライブラリの読み込み
require 'nokogiri'
require "pry"
# スクレイピング先のURL
url = 'https://news.yahoo.co.jp/pickup/6379353'
charset = nil
html = open(url) do |f|
charset = f.charset # 文字種別を取得
f.read # htmlを読み込んで変数htmlに渡す
end
# htmlをパース(解析)してオブジェクトを生成
doc = Nokogiri::HTML.parse(html, nil, charset)
# タイトルを表示
puts doc.title
# 画像のurlを表示
puts doc.css("div.bGGhSC > picture > source[1]").first.attributes["srcset"].value
これで、記事のタイトルと、画像urlが出力できるようになりました。
スクレイピングの導入部分を書かせていただきましたが、誰かのお役に立つことができたら幸いです!
また、もっと簡単に情報を取得できるなどありましたら、コメントなどで教えていただけると助かります!
以上でスクレイピングの解説を終わります。読んでいただきありがとうございます!