はじめに
機械学習やDeeplearningなどを勉強していると実装モデルに目がいきがちですが、データを扱う以上、基本的な統計を知っておく必要があります。また、わざわざ難しいモデルを持ち出さなくても集計レベルでもわかることがたくさんあります。
と言いつつ、大学で勉強したことを忘れているので、手元にあった参考書を片手にPythonとそのライブラリであるpandasを使って統計の初歩を復習しようと思います。
たまたま、データ共有プラットフォーム「delika」のデータに関する記事を書こう!キャンペーンがあったので、それに乗っかることにしました。
ゴール
CSV形式の数値データに対して、基本統計量の出力、集計、散布図、単回帰分析まで行い、統計的手法の基本をおさらいします。
※個別の詳細は公式ドキュメントへのリンクを貼ります。
delikaを使う
https://delika.io/qiita_delika_article_campaign/QiitadelikaDummy/articles.csv
実行環境
- Windows10
- Python 3.8.5
- pandas 1.3.5
- matplotlib 3.2.2
- seaborn 0.11.0
- scikit-learn 0.23.2
ライブラリのインポート
pandasとは、Pythonのデータ分析ライブラリの1つであり、様々なデータを共通の型(DataFrame)で処理でき、パフォーマンスも最適化されています。表計算や、抽出などSQLのようなことが実現可能です。
特徴: https://ja.wikipedia.org/wiki/Pandas
matplotlibとは、Pythonでグラフ化、可視化ができるライブラリです。pandasで集計した結果を可視化することが可能です。今回は、matplotlib内のpyplotモジュールを使用します。このモジュールを使うことで、データを引き渡すだけでmatplotlibの機能を使って、自動的に必要なグラフを生成してくれます。
公式:https://matplotlib.org/
※seaborn、scikit-learnというライブラリも使いますが、後述します。
import pandas as pd
import matplotlib.pyplot as plt
統計入門
データの入力
使用するデータ
delika:Qiitaの投稿に関するダミーデータの内、記事に関するデータ(articles.csv)を使用します
https://delika.io/qiita_delika_article_campaign/QiitadelikaDummy/articles.csv
DataFrameとして読み込み
DataFrameとはPandasで扱うことのできる表形式のデータ(2次元)である。
公式ドキュメント: https://pandas.pydata.org/docs/reference/api/pandas.DataFrame.html
# CSVデータを読み込む
df = pd.read_csv('articles.csv')
# 読み込んだデータの最初の5行を出力
df.head()
基本統計量
データの型と、それぞれの数値項目の基本統計量を計算してみます。
# カラム別のデータ型
df.info()
""" 出力
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 1000 entries, 0 to 999
Data columns (total 7 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 id 1000 non-null int64
1 created_at 1000 non-null object
2 likes_count 1000 non-null int64
3 comments_count 1000 non-null int64
4 url 1000 non-null object
5 users 1000 non-null object
6 page_views_count 1000 non-null int64
dtypes: int64(4), object(3)
"""
# 数値カラムの基本統計量
df.describe()
""" 出力
id likes_count comments_count page_views_count
count 1000.000000 1000.000000 1000.000000 1000.000000
mean 500.500000 592.138000 5.107000 4923.165000
std 288.819436 346.712903 3.207778 2891.506148
min 1.000000 0.000000 0.000000 4.000000
25% 250.750000 290.750000 2.000000 2461.000000
50% 500.500000 584.500000 5.000000 4646.000000
75% 750.250000 888.000000 8.000000 7503.750000
max 1000.000000 1200.000000 10.000000 10000.000000
"""
IDも数値扱いなので、基本統計量が出力されています。
集計
ユーザ数を求める
SQLのGROUP BY句と同様に、pandasにもgroupbyがあります。
# usersで軸として、数を数える
df.groupby('users').count()
""" 出力
id created_at likes_count comments_count url page_views_count
users
#NAME? 15 15 15 15 15 15
-3C9Qpzb0 1 1 1 1 1 1
-6ZyxjZ08 1 1 1 1 1 1
-9LoOpKe4 1 1 1 1 1 1
-WUM6h6d- 1 1 1 1 1 1
... ... ... ... ... ... ...
"""
「#NAME?」で15人となっているので、EXCELで開いて保存した結果がdelikaのサンプルデータになっているようです。それ以外は、1なので、記事の執筆者はバラバラということがわかりました。
年別の投稿数を求める
時系列処理もpandasは得意です。groupbyではなく、resampleを使って、日別を月別、年別に変換して集計できます。
# データを読み込んだ時に、Object型だったので、日付をdatetime64型に変換する
df['created_at'] = pd.to_datetime(df['created_at'])
# 日付をIndexに設定する
df_date = df.set_index('created_at')
# 月別(引数はM)
df_date.resample('M').sum()
""" 出力
id likes_count comments_count page_views_count
created_at
2012-04-30 2291 3470 35 31789
2012-05-31 5868 5416 64 63187
2012-06-30 3407 2240 26 27859
2012-07-31 4119 3355 22 27170
2012-08-31 4295 4418 22 43066
・・・
"""
# 年別(引数はY)
df_date.resample('Y').sum()
""" 出力
id likes_count comments_count page_views_count
created_at
2012-12-31 42380 46878 395 385064
2013-12-31 49853 62701 529 440000
2014-12-31 53258 59236 516 478362
2015-12-31 51158 58024 591 480729
・・・
"""
公式ドキュメント: https://pandas.pydata.org/docs/reference/api/pandas.DataFrame.resample.html
可視化
ヒストグラム
データの全体像を観察するために使用されるグラフです。それぞれの値がどのぐらい出現するかを示します。どういう値を取りやすいか、どのくらいばらついているかの分布になります。下記は、ページビューとその回数をヒストグラムにしました。
# ページビューをヒストグラムにする
plt.hist(df["page_views_count"])
# 縦軸と横軸のラベル
plt.xlabel("page_views_count")
plt.ylabel("count")
# グリッド線の表示
plt.grid(True)
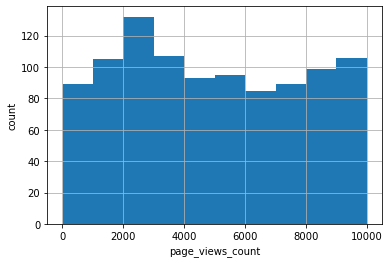
ヒストグラムの各棒の範囲(ビンという)は自動でセットしてくれますが、調整も可能です。詳しくは公式ドキュメントを参照ください。
公式ドキュメント:
https://matplotlib.org/3.5.0/api/_as_gen/matplotlib.pyplot.hist.html
散布図
2つの組み合わせデータをxy座標平面上に表したグラフです。2つの変数間の関係性などが見えてきます。回帰分析をする前には必ず実施して、線形性があるか異常値などがないかなどを確認します。ここでは、ページビュー数とLGTM数の関係を散布図に落としてみます。
plt.plot(
df['page_views_count'], # x軸
df['likes_count'], # y軸
'o' # フォーマット/'o': 点、'x': バツ印
)
plt.ylabel('likes_count')
plt.xlabel('page_views_count')
plt.grid(True)
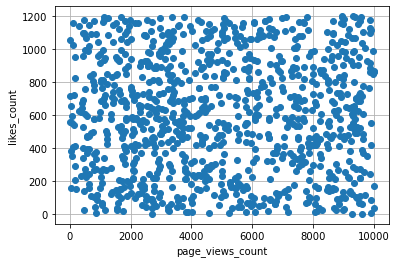
相関はなく、ランダムな感じがします。
公式ドキュメント: https://matplotlib.org/3.5.0/api/_as_gen/matplotlib.pyplot.plot.html
※plotメソッドの引数を変えるとグラフの形状を変更できる。
まとめて描くには?
変数が多いと、ヒストグラムや散布図を都度描いていくのが面倒になります。seabornというライブラリを使うと、一度にまとめて描いてくれます。
import seaborn as sns
sns.pairplot(df[['likes_count','comments_count','page_views_count']])
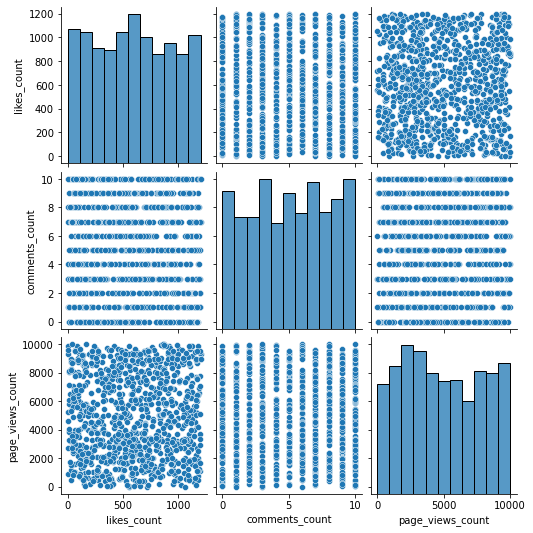
comments_countは0から10までの離散値であることから、直線的な散布図になっています。
seabornもmatplotlibと同様にPythonで使える可視化ライブラリの一つです。上記のように一気に変数の関係性を把握する際に便利です。また、matplotlibに比べてキレイな感じのグラフを作ってくれます。
公式ドキュメント: https://seaborn.pydata.org/
単回帰分析
回帰分析、つまり、数値予測をしてみます。単回帰とは、1変数から1変数を予測します。線形(直線、1次関数)的な関係式を出力します。
具体的には、page_views_count(説明変数)からlikes_count(目的変数)を予測するために、page_views_countをx、likes_countをyとしたときにy=ax+bを満たすようなa,bを求めます。
Pythonでは、scikit-learnというライブラリを使うと簡単に回帰分析を行うことが可能です。
# scikit-learnの中のlinear_model(線形モデル)モジュール
from sklearn import linear_model
# 回帰分析を行うときのおまじない
reg = linear_model.LinearRegression()
# sklearnを使う時は、numpy形式に変換する
x = df.loc[:, ['page_views_count']].to_numpy()
y = df.loc[:, ['likes_count']].to_numpy()
# 回帰分析を実行
reg.fit(x, y)
# 結果の出力
print('回帰係数:', reg.coef_)
print('切片:', reg.intercept_)
print('決定係数:', reg.score(x, y))
plt.scatter(x, y)
plt.ylabel('likes_count')
plt.xlabel('page_views_count')
plt.plot(x, reg.predict(x))
plt.grid(True)
""" 出力
回帰係数: [[0.00071635]]
切片: [588.61129734]
決定係数: 3.569087050481201e-05
"""

回帰係数がほぼ0で、決定係数も0なので、無相関だと言えます。
まとめ
色々、調べながらQiitaのデータを分析してみました。あくまでも手順を確認することを主眼に置いていたので、データからのインサイトは特に得られませんでした。与えられたデータでは、ページ見られても見られなくてもLGMTの数はランダム?でした。
一方で、データを与えられたときに、その特徴をつかむための最低限のやっておくべき手順とそのコードをまとめることができたと思います。
データを見たら、これらのことを試してから目的に応じて、分析手法を調べながら、実装してみようと思います。