前回を振り返って
前回はこちら↓↓
part1では、Typical DP ContestのA問題を、典型的な全探索でコーディングした。
その結果として、TLEという、時間内にプログラムが終了しなかったという評価がされ、不合格となった。
それもそのはずで、問題数が$N$問とした時の、$2^N$通りの全ての解答パターンに対する合計点を算出していたpart1のやり方では、その合計点のほとんどが重複しているのにも関わらず、全て計上し、それ故問題数に対して計算量が指数関数的に増えるためとても効率が悪かった。
問題で提示されている例では3問、10問程度だったが、これが30問とかになると爆発的に時間がかかってしまう。
その為、今回は動的計画法を用いて効率的にこの問題を解決していきたいと思う。
考え方
前回は全ての解答パターンに該当する合計点を全て算出していたが、今回は合計点にのみ着目して考えてみる。
ちなみにA問題はこちら↓↓
この問題の実行例として渡されている1つ目のパターンで考えてみたいと思う。
Sample Input 1
3
2 3 5
Sample Input 1で渡されている数値の意味は、全3問の問題で、その配点は1問目から順に2点、3点、5点という意味だ。
この時考えられる合計点を、各問題が解答された時点で考えてみる。
まず、1問目を解答した時点では、考えられる合計点は当然0点か2点になる。
2問目の配点は3点なので、考えられる合計点は、1問目時点での合計点から足されるか、足されないかの2択なので、0点、2点、3点、5点となる。
同じく、3問目の配点は5点であるため、その時点では0点、2点、3点、5点、7点、8点、10点の8パターンが考えられる。
多少見づらいかもしれないが、この考え方を図示すると下図のようになる。
(説明では1問目から始まっているが、この図ではi=0から開始していることに注意されたし)
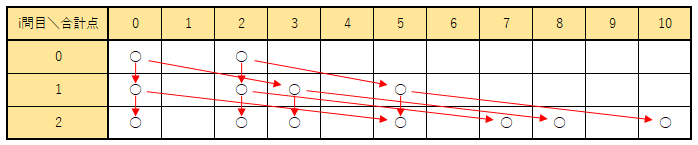
この図から見ると、$i$問目時点での合計点の集合$S_i$から見た $i+1$ 問目解答時点での合計点の集合$S_{i+1}$は、$S_i$と、$S_i$の各要素に $p_{i+1}$ を足した集合の和であるといえる。
また、Sample Input 2の場合も同様に
Sample Input 2
10
1 1 1 1 1 1 1 1 1 1
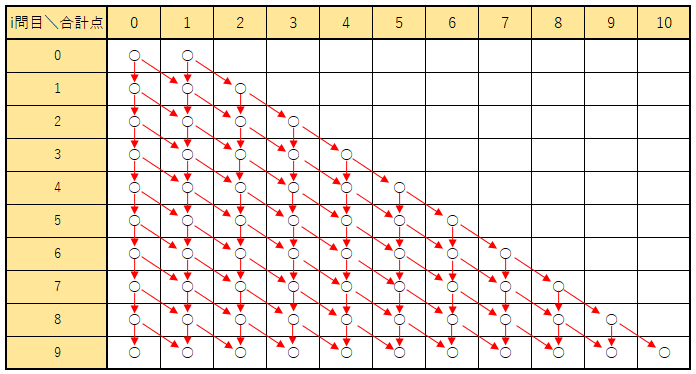
少し冗長ではあるが、このような状態遷移図で考えることが出来る。
コーディング
上のような状態遷移で考えた処理をコードにすると以下のようになった。
N = int(input())
p = list(map(int, input().split()))
total_list = {0}
for i in range(N):
for total in list(total_list):
total += p[i]
if total not in total_list:
total_list.add(total)
print(len(total_list))
$i$問目まで解答した時の考えられる合計点の集合$S_i$を出す処理を、$N$問分までループして全問題解き終えた時の合計点の集合を算出している。
内側のループ処理では、既にある合計点の集合total_listの要素一つ一つに$i$問目の配点$p_i$点を足して、まだtotal_listに含まれていない場合のみ新規にtotal_listに追加する、という処理をしている。
>>3
>>2 3 5
7
>>10
>>1 1 1 1 1 1 1 1 1 1
11
結果も問題なく表示された。
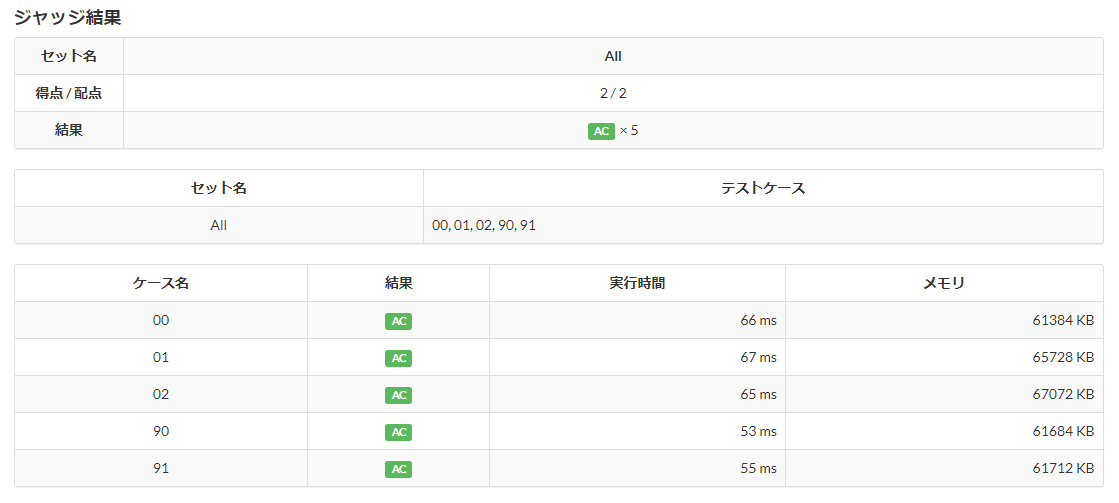
このコードを提出したところ、全てのテストケースでAC判定となり無事合格であった。
計算速度の比較
前回の全探索型のものと今回のコードの速度を比較するために、両者とも関数化して実行してみた。
なお、時間計測に使っている関数は自作のものです。
from Sudoku_Project.stopwatch import measure_time1
N = int(input())
p = list(map(int, input().split()))
total_list = {0}
# 前回作った全探索型の関数
def exh_search():
for i in range(2 ** N):
total = 0
for j in range(N):
if i >> j & 1:
total += p[j]
total_list.add(total)
# 今回作ったボトムアップ方式の関数
def bu_search():
for i in range(N):
for total in list(total_list):
total += p[i]
if total not in total_list:
total_list.add(total)
まずは全探索型の関数exh_search()で実行
print(measure_time1(exh_search))
print(len(total_list))
>>20
>>1 1 1 1 1 1 1 1 1 1 2 2 2 2 2 3 3 3 4 5
1.5043708 s
39
全20問を想定して実行した結果、1.5秒かかった(ちなみに30問で計算したところ、5分経っても終わらなかったため断念)
続いて、今回の関数bu_search()で実行
print(measure_time1(bu_search))
print(len(total_list))
>>20
>>1 1 1 1 1 1 1 1 1 1 2 2 2 2 2 3 3 3 4 5
30.4 μs
39
一つ目と比べると滅茶苦茶早い。
計算速度は20問の時、49486倍となった。
この差は、問題数が増えれば増えるほど広がる。
次↓↓