This post follows the great research blog of Google
https://ai.googleblog.com/
Introduction
Recent dramatic growth in natural language understanding research made great achievements. In this post, they have explained their approaches in two research papers recently published.
- Learning Semantic Textual Similarity from Conversations
-
Universal Sentence Encoder
And they made the pre-trained model accessible on TensorflowHub
Learning Semantic Textual Similarity from Conversations
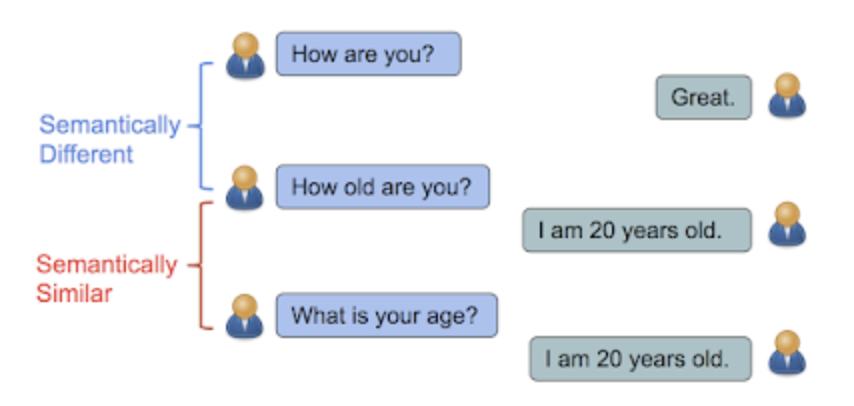
In this paper, they introduced novel approach to understand the semantic textual similarity based on the natural conversation. The concept is that the sentences are likely to be semantically similar if they have a similar distribution of responses. For instance, "How are you?" and "How old are you?" are meaning totally different and indeed the response should be different. But ""How old are you?" and "What is your age?" are meant same thing, asking age.
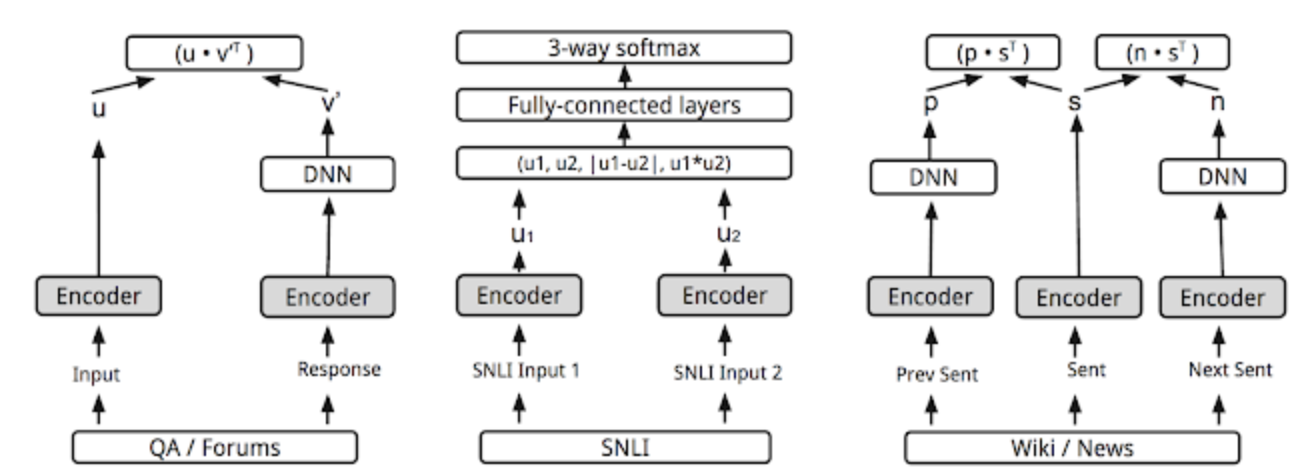
In this work, they have aimed to have learn the similarity between sentence through the response classification task; given a conversational input, we wish to classify the correct response from a batch of randomly selected responses.

However, the ultimate goal is to let a model be able to return the embeddings representing a variety of natural language relationships, including similarity and relatedness.
Universal Sentence Encoder
They have made the three models related with the sentence encoding architecture for NLP tasks on TF Lite.
Most of them are inspired by some existing reputed techniques in NN domain though, they have dispensed the decoder system and built the model with only encoders.
- Using DAN(Deep Average Network) in encoding
- Using Transformer in encoding
- Multi DAN models for encoding
Through the validation, they have found that compute time for the model using Transformer increases noticeably as sentence length increases, whereas the compute time for the DAN model stays nearly constant as sentence length is increased.
DAN
Simply averaging the input word vectors and propagate them to feed forward network.

reference: https://www.cs.umd.edu/~miyyer/pubs/2015_acl_dan.pdf
Transformer
It is the neural network architecture based on a self-attention mechanism.
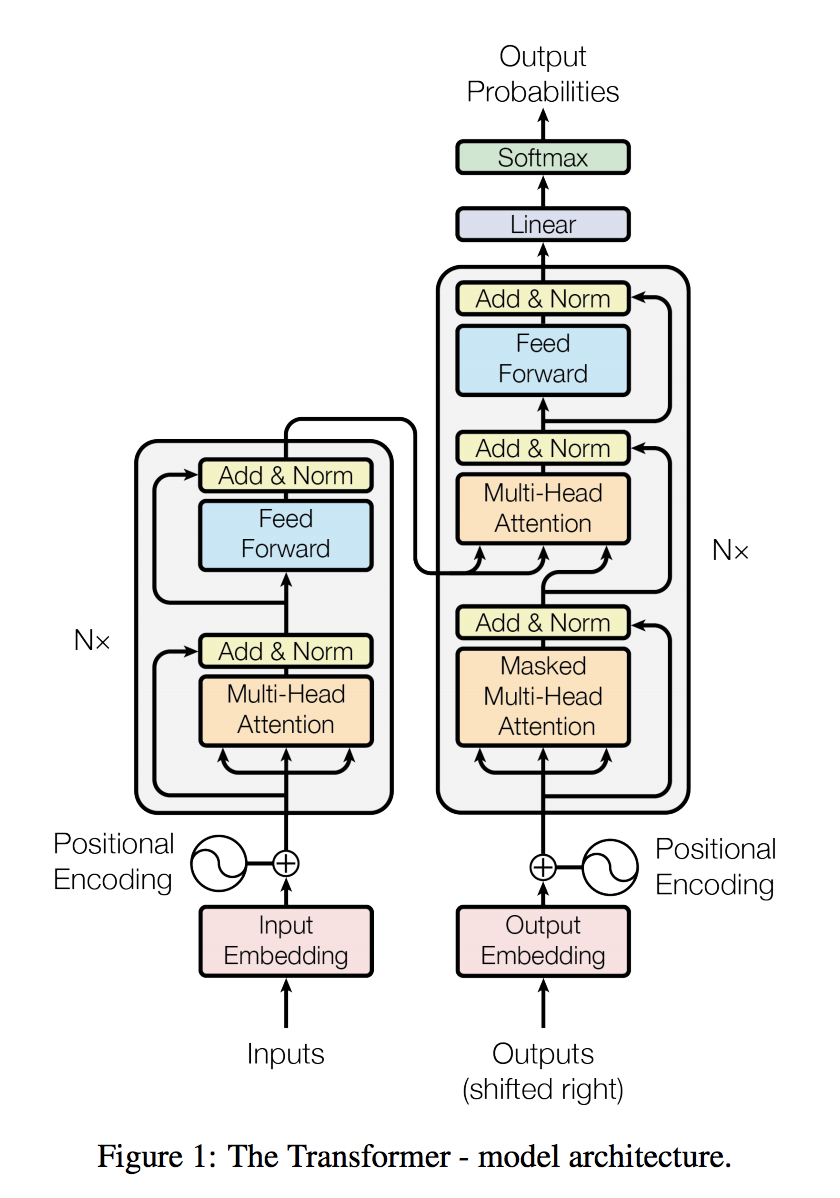
 reference: https://arxiv.org/pdf/1706.03762.pdf
reference: https://arxiv.org/pdf/1706.03762.pdf
Self dot product attention
$Attention(Q, K, V) = softmax(\frac{QK^T}{\sqrt{d_k}})$

References
Skip-Thought Vector
https://papers.nips.cc/paper/5950-skip-thought-vectors.pdf