Introduction
I was in need to transfer the huge matrix data from A to B, and initially I was trying to do this by Websockets though, the latency was really bad.
So I have decided to use more sophisticated protocol to communicate with B, which is gRPC.
In this article, let me briefly summarise about gRPC and its use-case as well.
Official Document
https://grpc.io/docs/guides/index.html
Overview
gRPC can use protocol buffers as both its Interface Definition Language (IDL) and as its underlying message interchange format.
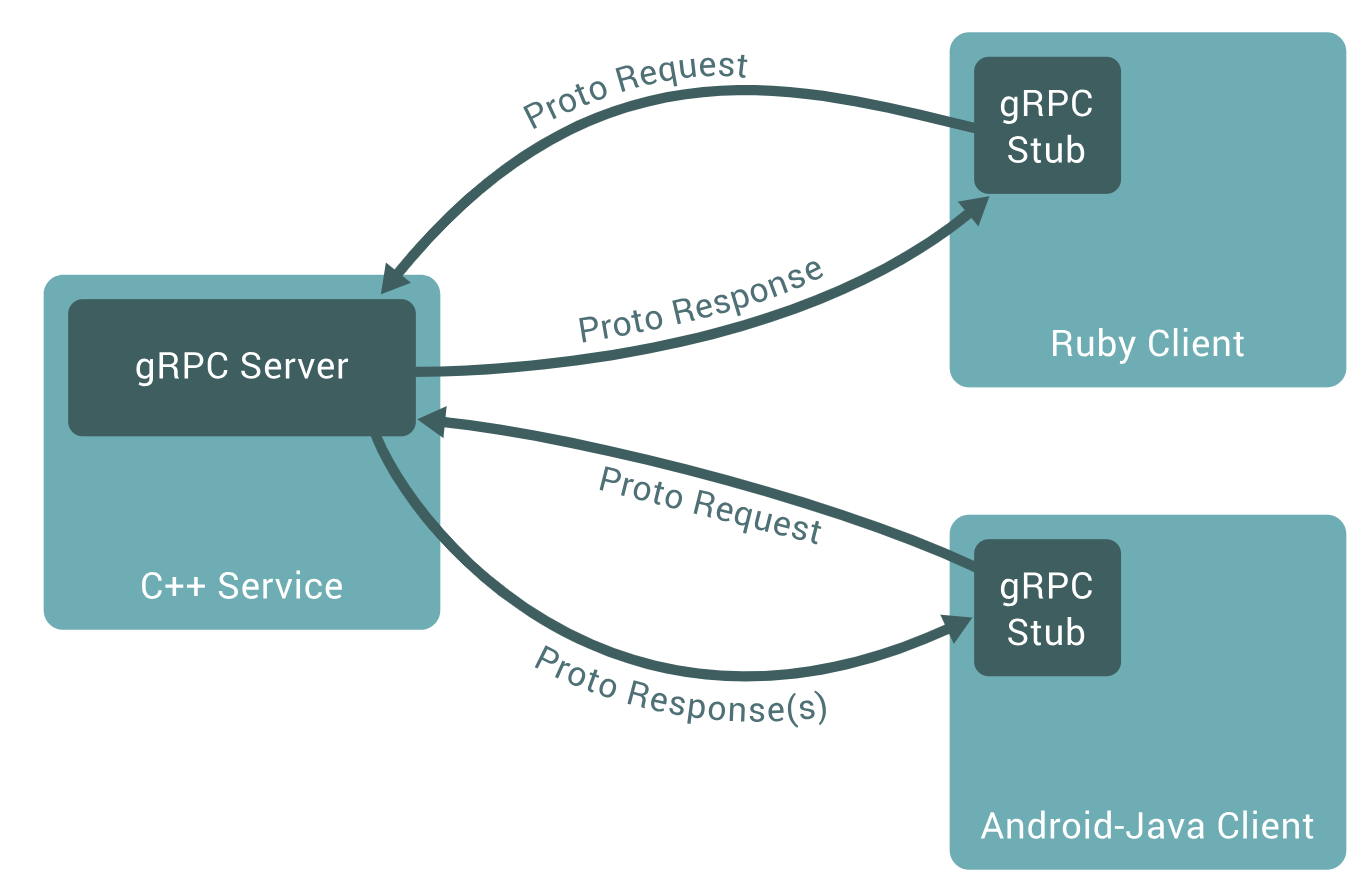
So, simply saying, the interface of client-server is same. So that means, you can programme both components in any kind of programming languages.
But, in order to utilise this function, we should be equipped with the protocol buffers more.
So let us move on to learning it.
Official Page: What are protocol buffers?
What are protocol buffers?
Protocol buffers are a flexible, efficient, automated mechanism for serializing structured data – think XML, but smaller, faster, and simpler. You define how you want your data to be structured once, then you can use special generated source code to easily write and read your structured data to and from a variety of data streams and using a variety of languages.
How do they work??
As a running example, we are going to consider the application which stores the contact profile of the person, which is an address book.
So, you might be a bit overwhelmed by a bunch of given new info.. but it's not that complicated.
What you have to do is the thing listed below.
- Define your data schema in
filename.proto - Compile the protocol file
- Program
write_info.pyto write the info tooutput.txtwith raw_input in python2 allowing you to briefly test it. - Program
read_info.pyto read the serialised and stored info inoutput.txt
So, let's get started!
1. Define your data schema in filename.proto
syntax = "proto2";
package tutorial;
message Person {
required string name = 1;
required int32 id = 2;
optional string email = 3;
enum PhoneType {
MOBILE = 0;
HOME = 1;
WORK = 2;
}
message PhoneNumber {
required string number = 1;
optional PhoneType type = 2 [default = HOME];
}
repeated PhoneNumber phones = 4;
}
message AddressBook {
repeated Person people = 1;
}
As you can see, the syntax is similar to C++ or Java. Let's go through each part of the file and see what it does.
The .proto file starts with a package declaration, which helps to prevent naming conflicts between different projects. In Python, packages are normally determined by directory structure, so the package you define in your .proto file will have no effect on the generated code. However, you should still declare one to avoid name collisions in the Protocol Buffers name space as well as in non-Python languages.
Next, you have your message definitions. A message is just an aggregate containing a set of typed fields. Many standard simple data types are available as field types, including bool, int32, float, double, and string. You can also add further structure to your messages by using other message types as field types – in the above example the Person message contains PhoneNumber messages, while the AddressBook message contains Person messages. You can even define message types nested inside other messages – as you can see, the PhoneNumber type is defined inside Person. You can also define enum types if you want one of your fields to have one of a predefined list of values – here you want to specify that a phone number can be one of MOBILE, HOME, or WORK.
The " = 1", " = 2" markers on each element identify the unique "tag" that field uses in the binary encoding. Tag numbers 1-15 require one less byte to encode than higher numbers, so as an optimization you can decide to use those tags for the commonly used or repeated elements, leaving tags 16 and higher for less-commonly used optional elements. Each element in a repeated field requires re-encoding the tag number, so repeated fields are particularly good candidates for this optimization.
Each field must be annotated with one of the following modifiers:
- required: a value for the field must be provided, otherwise the message will be considered "uninitialized". Serializing an uninitialized message will raise an exception. Parsing an uninitialized message will fail. Other than this, a required field behaves exactly like an optional field.
- optional: the field may or may not be set. If an optional field value isn't set, a default value is used. For simple types, you can specify your own default value, as we've done for the phone number type in the example. Otherwise, a system default is used: zero for numeric types, the empty string for strings, false for bools. For embedded messages, the default value is always the "default instance" or "prototype" of the message, which has none of its fields set. Calling the accessor to get the value of an optional (or required) field which has not been explicitly set always returns that field's default value.
- repeated: the field may be repeated any number of times (including zero). The order of the repeated values will be preserved in the protocol buffer. Think of repeated fields as dynamically sized arrays.
2. Compile the protocol file
you can complie the protocol file following the code below.
protoc -I=$SRC_DIR --python_out=$DST_DIR $SRC_DIR/sample.proto
In this line, $SRC_DIR means the current directory, and $DST_DIR is the source directory where you want the generated code to go.
So, in my case, I went like this.
protoc --python_out=./ sample.proto
it's simple, isn't it?
3. Program write_info.py
In order to use the generated file in previous section, we have to program the application which is able to get and store the data following the schema defined in the sample.proto.
So, let's finish it!
import sample_pb2 as connector
import sys
def PromptForAddress(person):
person.id = int(raw_input("Enter person ID number: "))
person.name = raw_input("Enter name: ")
email = raw_input("Enter email address: ")
if email != "":
person.email = email
while True:
number = raw_input("Enter a phone number: ")
if number == "":
break
phone_number = person.phones.add()
phone_number.number = number
type = raw_input("Is this a mobile, home or work place?")
if type == "mobile":
phone_number.type = connector.Person.MOBILE
elif type == "home":
phone_number.type = connector.Person.HOME
elif type == "work":
phone_number.type = connector.Person.WORK
else:
print("Unknown phone type is given")
if len(sys.argv) != 2:
print("Usage: ", sys.argv[0], "address_book_file")
sys.exit(-1)
address_book = connector.AddressBook()
try:
f = open(sys.argv[1], "rb")
address_book.ParseFromString(f.read())
f.close()
except IOError:
print(sys.argv[1] + ": Could not open file.")
PromptForAddress(address_book.people.add())
f = open(sys.argv[1], "wb")
f.write(address_book.SerializeToString())
f.close()
Hmm,, obviously I have just followed the distributed code though, let me explain a bit with this.
First thing first, we import the generated file, if you look inside the one, it looks quite messy though, I guess could get some insight from it.
Then, at the line of address_book = connector.AddressBook() , we initialise the object containing bunch of stuff defined in sample.proto. And in line of PromptForAddress(address_book.people.add()) we use the function we define above to add the obtained data from the console using raw_input.
$ python2 writer.py output.txt
4. Program read_info.py
So, it's almost there!!
In order to read the data written in the generated file in previous section, which is output.txt in this case.
We need a reader to be programmed following the schema again!
import sample_pb2 as connector
import sys
def ListPeople(address_book):
for person in address_book.people:
print("person id: ", person.id)
print("name: ", person.name)
if person.HasField('email'):
print("email-address: ", person.email)
for phone_number in person.phones:
if phone_number.type == connector.Person.MOBILE:
print("modile phone number: ")
elif phone_number.type == connector.Person.WORK:
print("work phone number: ")
elif phone_number.type == connector.Person.HOME:
print("home phone number: ")
print(phone_number.number)
if(len(sys.argv) != 2):
print("usage: ", sys.argv[0], "address_book_file")
sys.exit(-1)
address_book = connector.AddressBook()
f = open(sys.argv[1], 'rb')
address_book.ParseFromString(f.read())
f.close()
ListPeople(address_book)
python2 reader_grpc.py out.txt
So, that's it about protocol buffers!
To be continued to episode2....