Foreword
Recently I have started reading the paper about Asynchronous Advantage Actor-Critic in reinforcement learning. And this paper is referred by that paper on the subject of distributed learning in reinforcement learning.
So in this article I would like to briefly summarise it.
Author:
Arun Nair, Praveen Srinivasan, Sam Blackwell, Cagdas Alcicek, Rory Fearon, Alessandro De Maria, Vedavyas
Panneershelvam, Mustafa Suleyman, Charles Beattie, Stig Petersen, Shane Legg, Volodymyr Mnih, Koray
Kavukcuoglu, David Silver
Published Year: 2015
Link: https://arxiv.org/pdf/1507.04296.pdf
Introduction
They have presented first massively distributed learning in deep reinforcement learning and the generated agent did outperform the normal DQN agent on Atari 2600 games. They quoted the success case of distributed learning by (Coates
et al., 2013; Dean et al., 2012) in deep learning domain.
However in traditional reinforcement learning, many great schemes or theories have mainly focused on a single agent learning. Hence they have prepared multiple servers for each learning agent to store their learning history and the encountered experiences. This is called Distributed Experience Replay memory in the paper.
Applying the asynchronous stochastic gradient descent (ASGD), distributed learners can efficiently learn from the experience memory.
DQN Architecture

Gorila (General Reinforcement Learning Architecture)
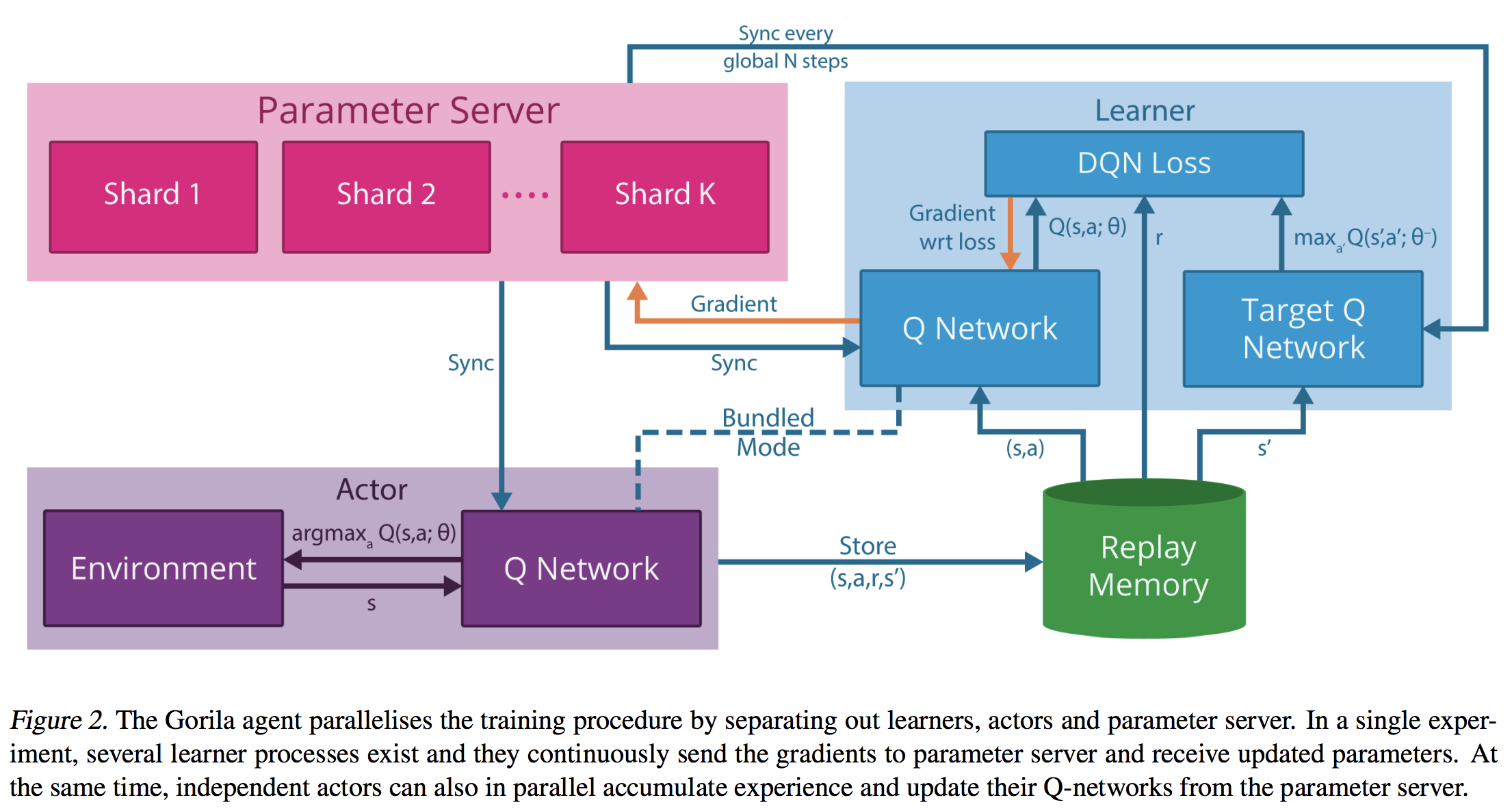
Algorithm

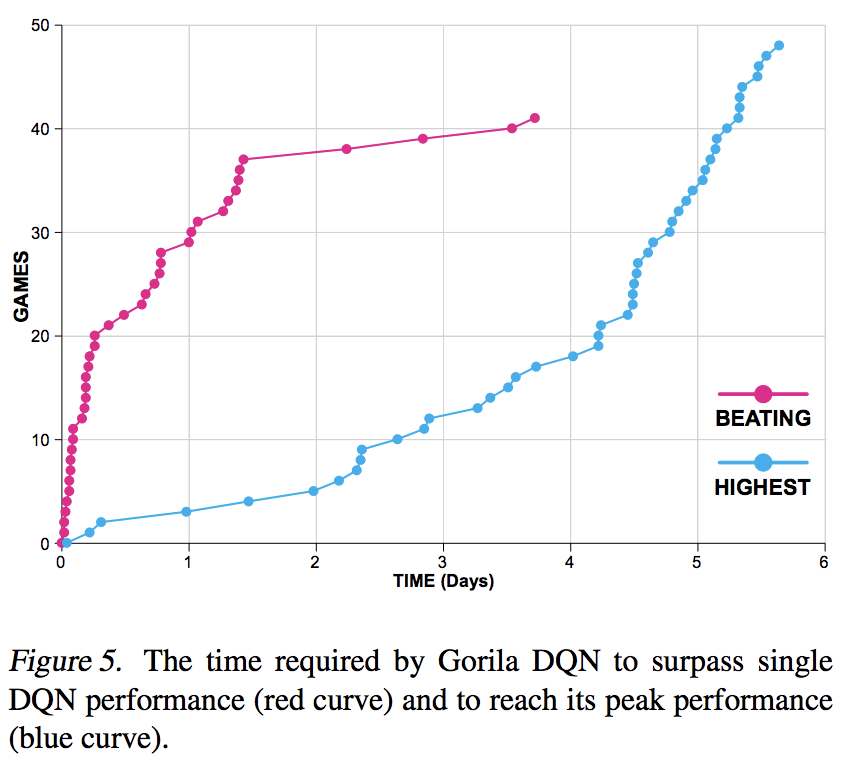
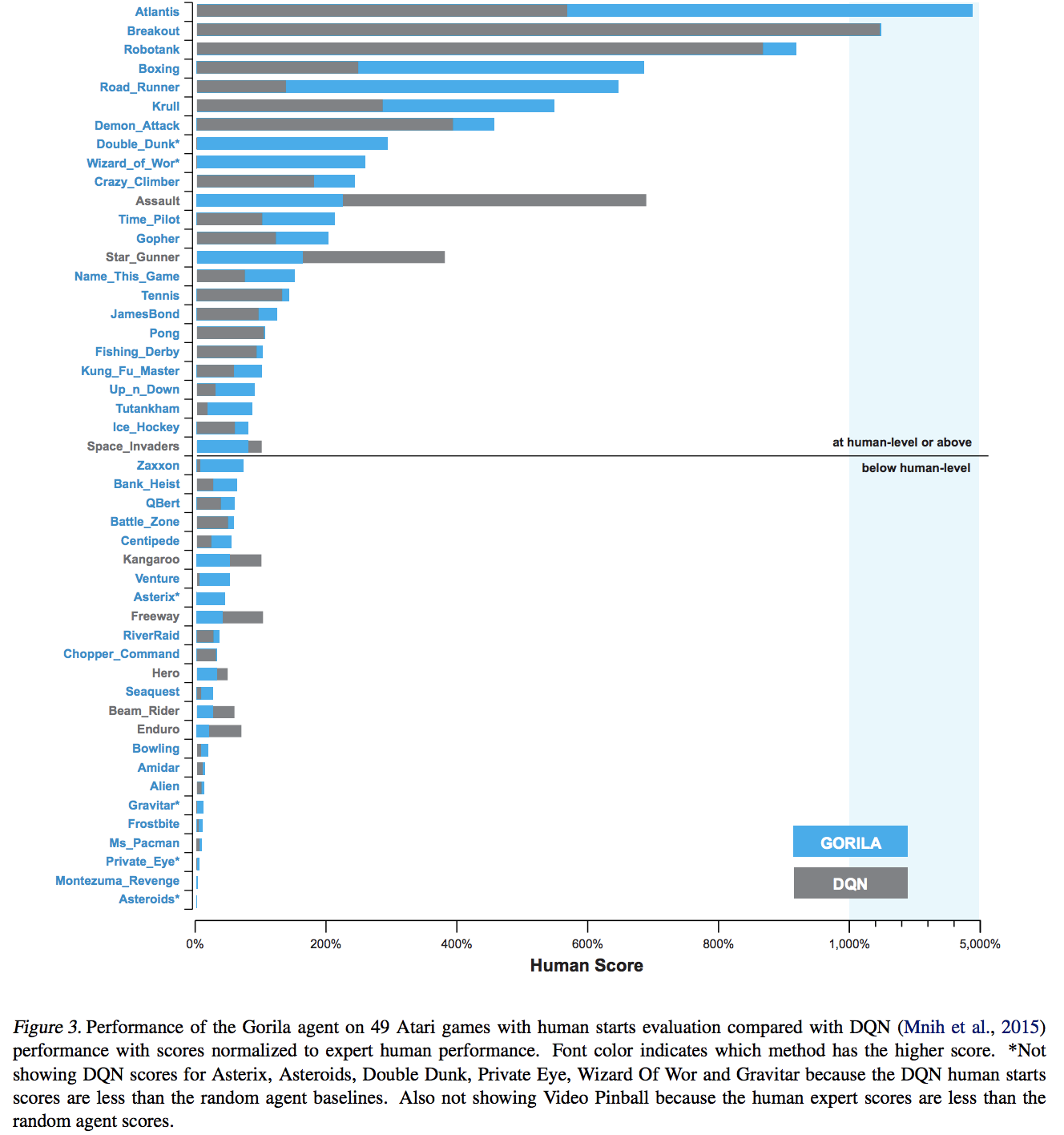
Experiments
They evaluated Gorila by conducting experiments on 49 Atari 2600 games using the Arcade Learning Environment.