Foreword
Recently I have been curious about the causes helping the success of DQN. Since 2015, many researchers developed the concept of the migration of DL and RL rapidly. And in my point view, We need more novel techniques to support the combination of them, usually people call this domain as Deep Reinforcement Learning. For running example, in DQN experience replay, which is the technique to store the encountered states in the memory to replay them later for efficient learning , is used. So in this article, i have developed my insight of ER more to get better understanding of deep reinforcement learning.
Paper Information
- Self-Improving Reactive Agents Based On Reinforcement Learning, Planning and Teaching
- Experience Replay for Real-Time Reinforcement Learning Control
- Real-Time Reinforcement Learning by Sequential Actor-Critics and Experience Replay
- SAMPLE EFFICIENT ACTOR-CRITIC WITH EXPERIENCE REPLAY
- Hindsight Experience Replay
- Stabilising Experience Replay for Deep Multi-Agent Reinforcement Learning
- PRIORITIZED EXPERIENCE REPLAY
- A Deeper Look at Experience Replay
- DISTRIBUTED PRIORITIZED EXPERIENCE REPLAY
1. Self-Improving Reactive Agents Based On Reinforcement Learning, Planning and Teaching
Author: LONG-JI LIN
Published Year: 1992
Notes:
Issue: RL agents need huge time to learn
Approach: Experience Replay can enhance the efficient learning and store the precious experiences for future usage.
Concept: some experiences are quite rare and costly to obtain it again.
So if we can remember all of them, the agent can efficiently learn from it. Reusing experiences to feed them to the agent as if it experiences those again.
Remaining Challenges: if the env has dynamically changed, the past experiences become meaningless.
2. Experience Replay for Real-Time Reinforcement Learning Control
Authors: Sander Adam, Lucian Bus¸oniu, and Robert Babuska
Published Year: 2012
Notes:
They have applied ER to control of the real time robots, which is a soccer game in this paper.
As they explicitly mentioned, their contribution goes mainly to the experimental evaluation of the usage of ER RL for real time control of the robots.
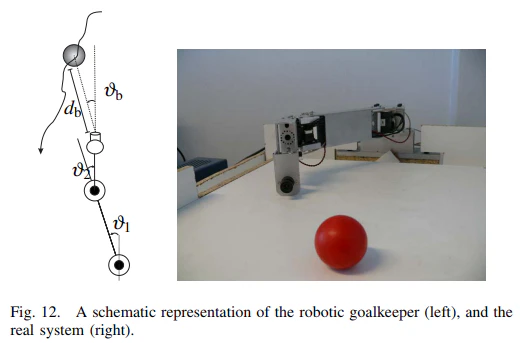
The paper is organized as follows. Section II presents the necessary background in exact and approximate RL. In Section III, we introduce and discuss our ER framework. In Section IV, the performance of the ER algorithms is evaluated in an extensive simulation and experimental study. Section V concludes the paper.
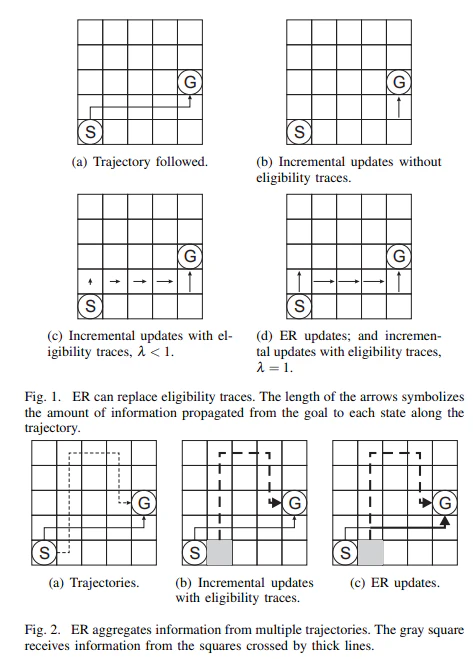
According to their deep analysis, ER has three benefits.
- Reutilisation of the past data
- Having asymptotically similar effects with eligibility traces, because it propagates similar information to that transmitted by the eligibility traces.
- Aggregation of information from multiple trajectories
3. Real-Time Reinforcement Learning by Sequential Actor-Critics and Experience Replay
Author: Pawel Wawrzynski
Publish Year: 11 May 2016
Notes:
This paper shows how Actor-Critics algorithms can be augmented by ER without degrading their convergence properties, by appropriately estimating the policy change direction. This is achieved by truncated importance sampling applied to the recorded past experiences.
The paper is organized as follows. In Section 2 the problem of our interest
is defined along with the class of algorithms that encompasses sequential
Actor-Critics. It is shown that a given Actor-Critic method defines certain improvement directions of its parameter vectors. Section 3 shows how to estimate
these directions using the data from the preceding state transition and to accelerate a sequential algorithm by combining these estimators with experience
replay. Conditions for asymptotic unbiasedness of these estimators are established
in Section 4 that enable the algorithm with experience replay to inherit
the limit properties of the original sequential method. The experimental study
on the introduced methodology is presented in Section 5 and the last Section
concludes.



4. SAMPLE EFFICIENT ACTOR-CRITIC WITH EXPERIENCE REPLAY
Authors: Ziyu Wang, Victor Bapst, Nicolas Heess, Volodymyr Mnih, Remi Munos, Koray Kavukcuoglu, Nando de Freitas
Published Year: 2017 July
Issues:
The design of stable, efficient actor-critic methods being applicable to both continuous and discrete action spaces has been a long-standing hurdle of RL.
Approaches:
Applying these three techniques to Actor-Critic learning method, they have achieved novel result.
- Truncated Importance Sampling with bias correction: (marginalisation of IS)Degris et al in 2012, (truncation of IS) Wawrzynski in 2009
- Stochastic Dueling Networks: Wang et al. (2016)
- Efficient Trust Region Optimisation Method: Schulman et al in 2015
Model Architectures:
- Basic Actor Critic Algo
 - A3C
- A3C
 check the details here! https://qiita.com/Rowing0914/items/214922c600640d143ad7
- Policy Gradient with Importance Sampling
check the details here! https://qiita.com/Rowing0914/items/214922c600640d143ad7
- Policy Gradient with Importance Sampling
 - Policy Gradient with Marginalised Importance Sampling by Degris et al in 2012
He has marginalised the importance sampling using expectation => because the product computation generates huge bias!!
- Policy Gradient with Marginalised Importance Sampling by Degris et al in 2012
He has marginalised the importance sampling using expectation => because the product computation generates huge bias!!
 - Retrace algo for discrete action space
- Retrace algo for discrete action space

 - Truncated Importance Sampling
- Truncated Importance Sampling

 - ACER update
- ACER update
 - Trust Region Policy Optimization (TRPO) (Schulman et al., 2015a)
- Trust Region Policy Optimization (TRPO) (Schulman et al., 2015a)
 - Dueling network Wang et al. (2016)
- Dueling network Wang et al. (2016)


- ACER

5. Hindsight Experience Replay
Authors:
Published Year: 2017
Concept: One ability humans have is to learn from our mistakes and adjust next time to avoid making the same mistake. And RL doesn't have it yet. So by setting multiple goals during one scenario, we can re-examine this trajectory with a different goal - while this trajectory may not help us learn how to achieve the state g, but it definitely tells us something key to solve the state $s_T$.
Base algo: DDPG(Deep Deterministic Policy Gradient) Proposed by Timothy P. Lillicrap et al.
They presented an actor-critic, model-free algorithm based on the deterministic
policy gradient that can operate over continuous action spaces.
Isseus: DQN is not applicable to continuous action spaces. So it's not for Robotics! By the way, their work was based on the deterministic policy gradient (DPG) algorithm (Silver et al., 2014)
Approaches: They advanced the DPG(David Silver in 2014) algo by adapting DQN approach.
Remaining Issues: A robust model-free approach may be an important component of larger systems which may attack these limitations (Glascher et al., 2010).
Model Architecture:

Issues:
Comparing to human beings, RL needs huge time to adjust itself to achieve the task in continuous action spaces.
Approaches:
Adapting UVFA(universal value function approximators which is proposed by Schaul et al in 2015) to DDPG(deep deterministic policy gradient which is proposed by Lillicrap et al in 2015), we store the multiple goals corresponding to each state, action in the episode to the experience memory, then replay that.
Result:
For a running example, they have evaluated DQN with/without HER(hindsight experience replay), and the result is shown below.
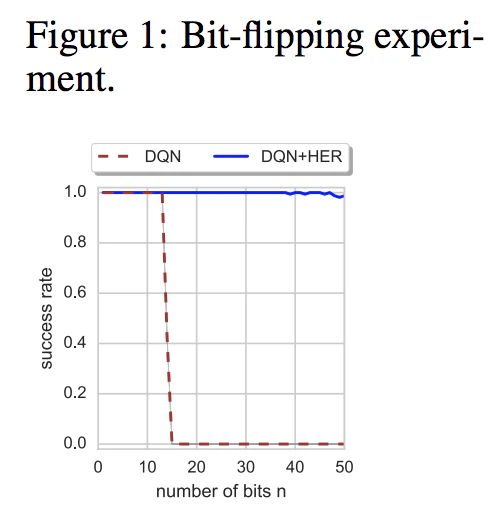
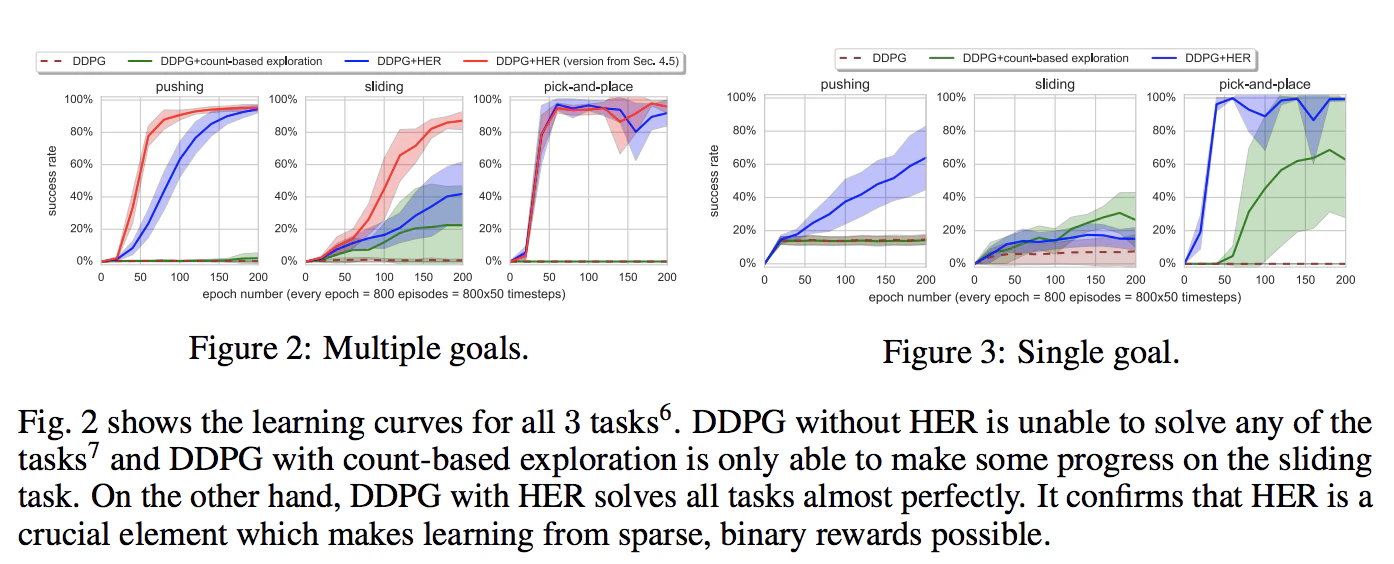
Result of the experiment, i.e. to apply HER to other off-policy learning methods, like DQN and DDPG.
Algo:

6. Stabilising Experience Replay for Deep Multi-Agent Reinforcement Learning
Authors: Jakob Foerster, Nantas Nardelli, Gregory Farquhar, Triantafyllos Afouras, Philip. H. S. Torr, Pushmeet Kohli, Shimon Whiteson
Published Year: 2018 May
Prerequisites:
check Independent Q Learning
https://qiita.com/Rowing0914/items/6467b7c82ab83eb0baae
Contents:
Issues: How to apply the success case of DL in Single RL to MARL situations. Because the currently dominant technique, which is called Independent Q Learning, is not quite applicable to Deep Reinforcement Learning like DQN. It is because, IQL considers other agents' policies as an environment and this indeed generates huge non-stationarity making the environment dynamic. Hence, the Experience Reply doesn't apply anymore.
Approaches:
They have two ways to address this issue.
- Using a multi-agent variant of importance sampling to naturally decay obsolete data
- conditioning each agent's value function on a fingerprint that disambiguates the age of the data sampled from the reply memory.
Simple fingerprint contains the information such as an index of the episode, and epsilon of the rate of the exploration.
Task:
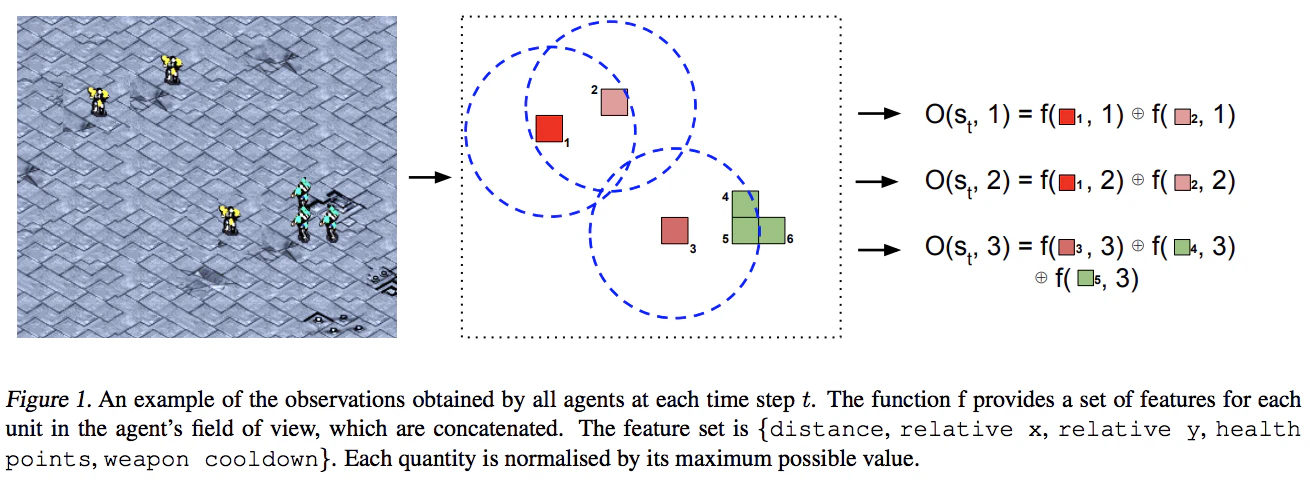
Result:
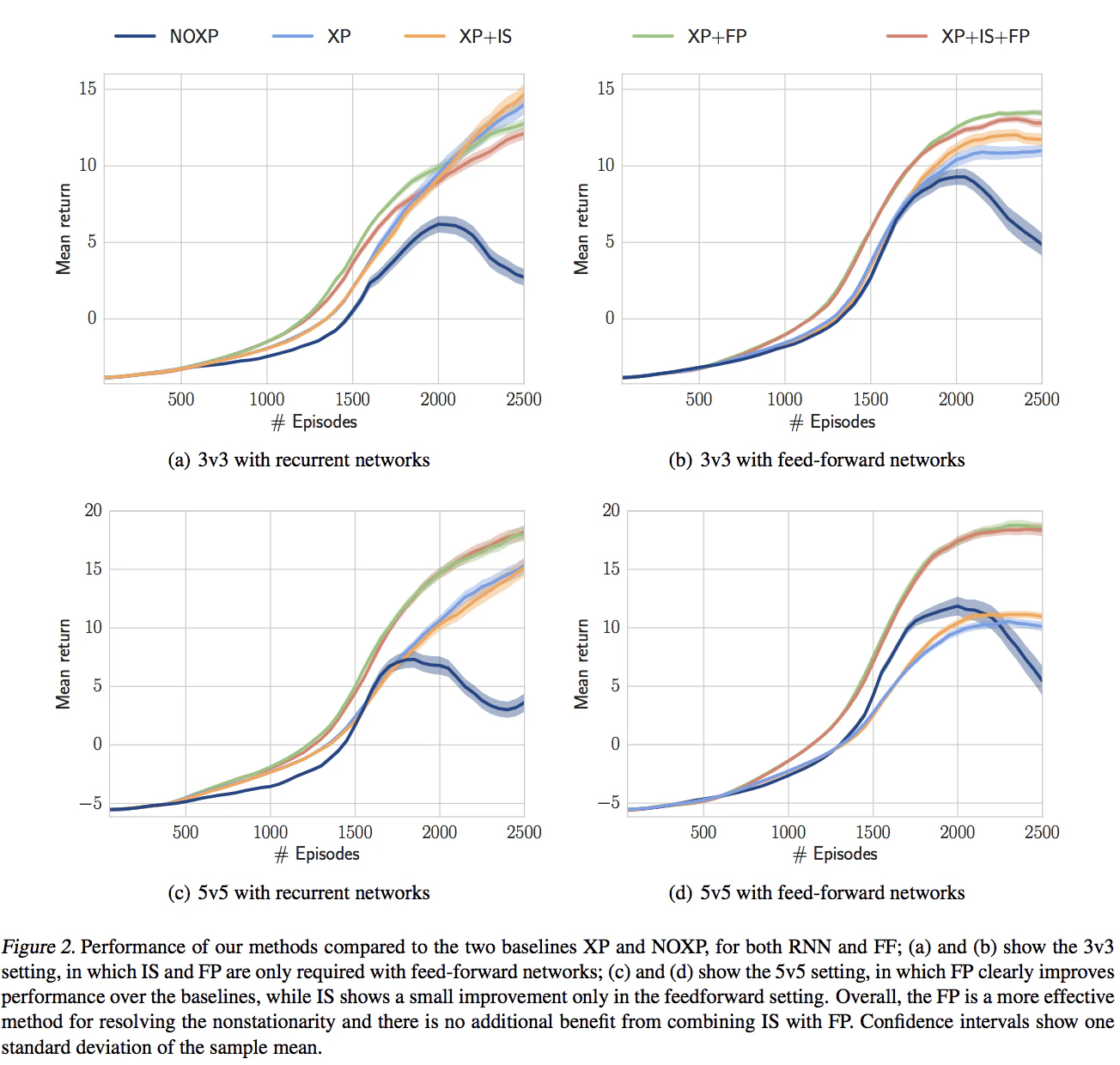
7. PRIORITIZED EXPERIENCE REPLAY
Authors: Tom Schaul, John Quan, Ioannis Antonoglou and David Silver
Published Year: 2015 November
Issues: