イントロ
今回のレッスンはscikit-learnという機械学習用のライブラリについての概要の説明と実際の使い方を簡単に紹介したいと思います。
準備
コンソールやターミナルから下記のコマンドを実行して、ライブラリを取得するだけです。
pip install scikit-learn
公式サイト
一般的な評価
下記の記事にもある通り、機械学習のライブラリの中ではやはり随一の知名度を誇り、アルゴリズムのバラエティにも富んでいます。
また、使い方も非常に簡単で、理論を勉強しながら実際にそれを現実的な問題に適用してみるということを簡単に行えるようにしてくれるライブラリです。
https://www.quora.com/What-are-the-best-open-source-machine-learning-libraries-written-in-Python
機械学習のモデル構築プロセス
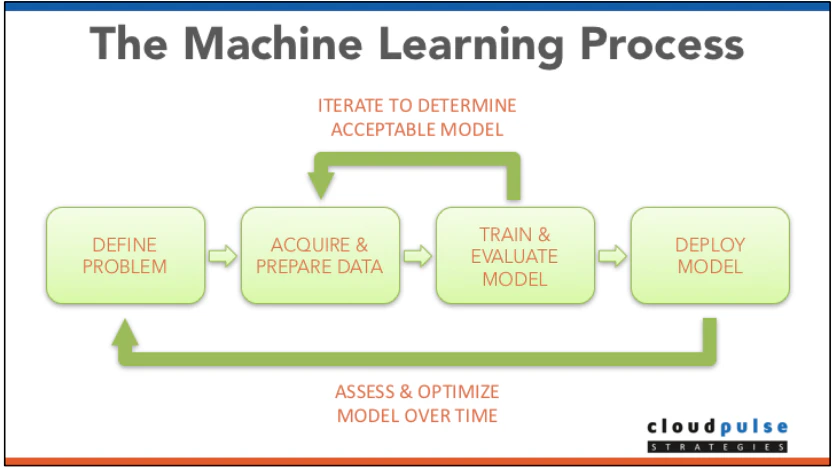
- データ・課題の整理をする
ちょっと長くなってしまいますが、一番大事な部分ですので書きます。
まず、機械学習を使って解きたい問題や実現したいサービスを定義してみます。データはあるんだけど何をして良いかわからない、という場合もあるかもしれません。例えばですが、未来の株価の予測、画像や音声の判別、欠損データの補間、異常値の特定など、これらはすべて未知の事象に対する予測問題として定義することができます。
一旦課題が決まれば、次第に必要なデータは明らかになってきます。例えば、明日の東京都全体の電力需要を予測したいのであれば、過去の需要データに加え、その日の天気や曜日の情報(平日or休日)なども予測に役に立つでしょうし、その日に起こる予定のイベントとかも考慮しておいた方が良いかもしれません。この辺りはデータの収集コストと相談する必要もあるかと思います。また、データそのものの収集に伴って、データに関する周辺的な知識(よく知られた法則、物理的な制約など)も色々仕入れておけば、後のモデル構築の段階に役立てられる可能性が高いです。 - データ収集
集めたデータの形式や粒度がバラバラだったりする場合はこの時点で揃えておくのが良いかもしれません。ただし、欠損値の補間や異常値の除去、データサイズの補正などのいわゆる「前処理」をここで行ってしまうと、後段のアルゴリズムに対する情報欠損に繋がる可能性があります。手間とコストを十分に考慮する必要があります。 - モデルのトレーニングと評価
この段階では、1と2を経て行ってきた問題定義とその課題解決をするために収集したデータを用いて実際のモデルを作ることをしていきます。トレーニングといってもまずはどういったモデルを使用していくのかを決める必要があります。一つのモデルで問題が解決できる場合もありますし、いくつかのモデルを使い分けて問題を解決していく場合もあります。例として下記のマイクロソフトの研究がわかりやすいかもしれません。
URL: https://www.microsoft.com/en-us/research/project/deep-reinforcement-learning-goal-oriented-dialogue/
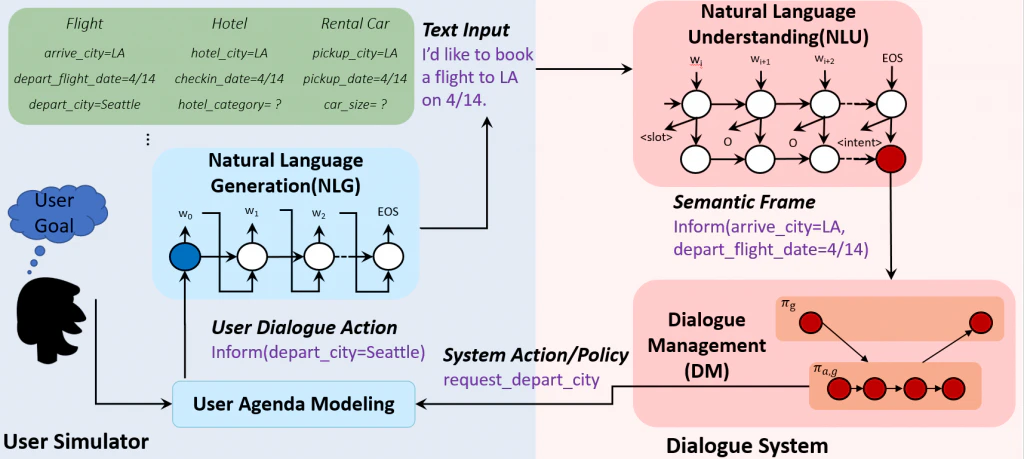
ここではチャットボットを作るためのロジックが説明をされてます。音声認識や自然言語理解、ひいては強化学習を用いてuser simulatorを作成して、作成後のモデルの検証やトレーニングを自動化するということなど、決して一つのモデルでは終わっていないことがわかるかと思います。
ここまで大規模なアプリケーションの作成にかかわることは多くはないかもしれませんが、実際の現場ではこういった大きなビジョンの元様々なモデルが使用されています。 - モデルのアプリケーション等での適用
基本的なモデルクラスの使い方
- モデルインスタンス生成
- fitさせる (学習)
- predictする (予測)
scikit-learnはAPIが統一されていて、とてもわかりやすいです。
データセット一覧
| API | 説明 | |
|---|---|---|
| load_boston | 米国ボストン市郊外における地域別の住宅価格 | 回帰 |
| load_iris | 3 種類の品種のアヤメのがく片、花弁の幅および長さ | 分類 |
| load_diabetes | 糖尿病患者の検査数値と1年後の疾患進行状況 | 回帰 |
| load_digits | 0~9の手書き文字の8×8画像 | 分類 |
| load_linnerud | 成人男性の生理学的特徴と運動能力 | 回帰 |
| load_wine | 3種類のワインの科学的特徴 | 分類 |
| load_breast_cancer | 乳がんの診断結果 | 分類 |