Research Paper Link: https://arxiv.org/pdf/1409.3215.pdf
Github Repo: https://github.com/google/seq2seq
Official Introduction: https://www.tensorflow.org/tutorials/seq2seq
Abstract
DNN(Deep Neural Network) works well on large-scale datasets. But it is not good at mapping sequences to sequences.
In this paper, they present a general end-to-end approach to sequence learning that makes minimal assumptions on the sequence structure.
And conducted the experiments on the task of English-French translation.
Finally, they found that reversing the order of the words in all source sentences (but not target sentences) improved the LSTM’s performance markedly, because doing so introduced many short term dependencies between the source and the target sentence which made the optimization problem easier.
Content
- Introduction
- The model
- Experiments
- Dataset details
- Decoding and Rescoring
- Reversing the Source Sentences
- Training details
- Parallelizations
- Experimental Results
- Related Work
- Conclusion
Body
1. Introduction
By using LSTM, they created the model for machine translation.
First reads the source sentence using an encoder to build a "thought" vector, a sequence of numbers that represents the sentence meaning; a decoder, then, processes the sentence vector to emit a translation.
This is often referred to as the encoder-decoder architecture.

Thought Vectors
This vector has been called, by various people, an "embedding", a "representational vector" or a "latent vector". But Geoff Hinton, in a stroke of marketing genius, gave it the name "thought vector".
 Link: http://gabgoh.github.io/ThoughtVectors/
Link: http://gabgoh.github.io/ThoughtVectors/
2. The model
They used the model based on the one introduced by Alex Graves.
Additionally they put some feature,
- 2 different LSTM (Encoder, Decoder)
- 4 layers of LSTM (Deep RNN)
- Feeding Reversed Sentence
- Beam Search at output layer
So to deeply understand their architecture, let's have a look at his research paper.
Title: Generating Sequences With Recurrent Neural Networks
Author: Alex Graves
Date: 5/6/2014
Abstract
shows how Long Short-term Memory recurrent neural networks can be used to generate complex sequences with long-range structure, simply by predicting one data point at a time. The approach has demonstrated for the text and online handwriting.
RNN Prediction Architecture
Image
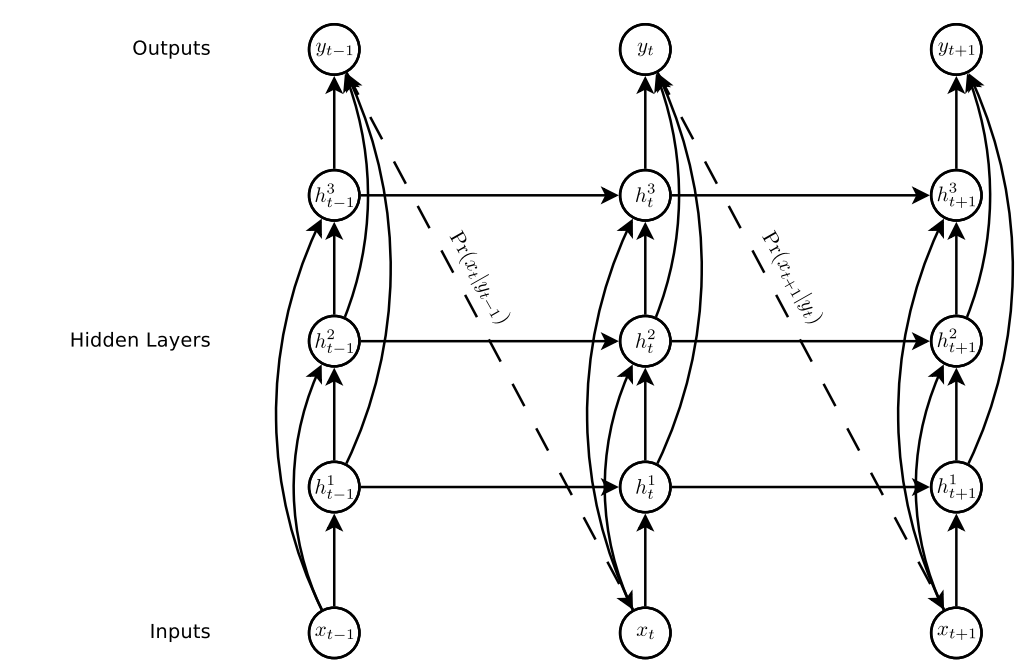
Input: $X = (x_1, x_2 , ... , x_T)$
Output: $Y = (y_1, y_2 , ... , y_T)$
Hidden: $h^n = (h^n_1, h^n_2, ... , h^n_T)$
Paramater: $P(x_{t+1}|y_t)$
- At first step(T=1), normally this should be $x_1 = 0$, hence this returns $y = x_2$
Skip Connections (from Input to all hidden layers and all hidden layers to outputs)
Input to Hidden skip connections
h^n_t = H(W^{xh}x_t + W^{h^{n-1}h^n}h^{n-1}_{t} + W^{h^n h^n}h^{n}_{t-1} + b^n_t)
Hidden to Output skip connections
Cost Function: negative logarithm cost function
Output Layer($y^k_t$): Softmax
\hat y_t = b_y + \sum ^N_{n=1} W^{h^ny}h^n_t\\
y_t = Y(\hat y_t)\\
Pr(x) = \prod^T_{t=1} Pr(x_{t+1}|y_t)\\
L(x) = - \sum ^T_{t=1} \log Pr(x_{t+1}|y_t)\\
Prediction Network
Pr(x_{t+1} = k|y_t) = y^k_t = \frac{\exp(\hat y^k_t)}{\sum^K_{k'=1} \hat y^{k'}_t}\\
Hence\\
L(x) = - \sum ^T_{t=1} \log y^k_t \Leftrightarrow \frac{\delta L(x)}{\delta y^k_t} = (y^k_t - \delta_{k, x_{t+1}})
The partial derivatives of the loss with respect to the network weights can be efficiently calculated with backpropagation through time, and the network can then be trained with stochastic gradient descent.
3. Experiments
3.1 Dataset Details
They used the WMT’14 English to French MT tasks.
We chose this translation task and this specific training set subset because of the public availability of a tokenized training and test set together with 1000-best lists from the baseline SMT.
- SMT: Statistical Machine Translation
3.2 Decoding and Rescoring
Training mainly involves to maximisation of the log probability of a correct translation $T$ given the source sentence $S$.
\frac{1}{|S|}\sum_{(T,s) \in S} \log p(T|S)\\
Once the training finishes, we do translation by finding the most likely translated words.
\hat T = argmax \space p(T|S)
Using beam search, we can reach to the most likely words.
Size of Beam Search was tested as well and turned out that size of 2 significantly outperform compared to size of 1.
- What is Beam Search
3.3 Reversing the Source Sentences

3.4 Training Details
Layer: 4
Cells per layer: 1,000
Input: 160,000 vocabulary
Output: 80,000 vocabulary => softmax over 80,000 words.....
Number of Parameters in the nets: 384M...
Weight Matrix Initialisation: Real number of (-0.08, 0.08)
Optimisation: SGD(stochastic gradient descent)
Batch Size: 128
Constraints on the gradient:
s = ||\frac{\nabla gradient}{128}||_2\\
if \space s > 5, \space then \space g = \frac{5g}{s}
3.5 Parallelisation
A C++ implementation of deep LSTM with the configuration from the previous section on a single
GPU processes a speed of approximately 1,700 words per second. This was too slow for our
purposes, so we parallelized our model using an 8-GPU machine. Each layer of the LSTM was
executed on a different GPU and communicated its activations to the next GPU / layer as soon as
they were computed. Our models have 4 layers of LSTMs, each of which resides on a separate
GPU. The remaining 4 GPUs were used to parallelize the softmax, so each GPU was responsible
for multiplying by a 1000 × 20000 matrix. The resulting implementation achieved a speed of 6,300
(both English and French) words per second with a minibatch size of 128. Training took about a ten
days with this implementation.
3.6 Experimental Results
See sec 3.3.
3.7 Performance on Long Sentences
See sec 3.3.
3.8 Model Analysis

4. Related Work
RNNLM(recurrent neural network language model)
T. Mikolov, M. Karafi´at, L. Burget, J. Cernock`y, and S. Khudanpur. Recurrent neural network based
language model. In INTERSPEECH, pages 1045–1048, 2010.
NNLM
M. Auli, M. Galley, C. Quirk, and G. Zweig. Joint language and translation modeling with recurrent
neural networks. In EMNLP, 2013.
J. Devlin, R. Zbib, Z. Huang, T. Lamar, R. Schwartz, and J. Makhoul. Fast and robust neural network
joint models for statistical machine translation. In ACL, 2014.
End-to-End Training
K. M. Hermann and P. Blunsom. Multilingual distributed representations without word alignment. In
ICLR, 2014.
5. Conclusion
They concludes that this work is quite potential and can be followed more later.