Foreword
Recently I got much interests on ML-Agents by Unity, which is the platform for training the agent with reinforcement learning approaches. In fact, as a running example, they have introduced PPO as a de fact standard method.
Hence, I have realised that without understanding PPO, I could not proceed anymore. So in this article, I would like to summarise my understanding on PPO.
Profile of the paper
Authors : John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, Oleg Klimov from OpenAI
Published Year: August in 2017
Link : https://arxiv.org/pdf/1707.06347.pdf
Introduction
This novel approach named PPO(Proximal Policy Optimisation) is actually a family of policy gradient methods. In general, when we deal with the complicated task in reinforcement learning, the policy gradient methods are the best practice.
However, in this paper, they have carefully analysed the issues arose in existing approaches like TRPO, and propose the improvement.
Advantage : PPO
- PPO recorded new state-of-the-art performance on continuous action spaces tasks.
- PPO is far straightforward than other algorithms, like ACER or TRPO.
Background
1. Policy Gradient Methods
PGM work by computing an estimator of the policy gradient and plugging it into a stochastic gradient ascent algorithms.
\hat{g} = \hat{E_t} \big[\nabla_{\theta}log π_{\theta}(a_t | s_t) \hat{A} \big]
where
- $π_{\theta}$ : stochastic policy
- $\hat{A_t}$ : an estimator of the advantage function
- $\hat{E_t[.]}$ : empirical average over a finite batch
and $\hat{g}$ can be quoted by differentiating the objective function below.
L^{PG}(\theta) = \hat{E_t} \big[log π_{\theta}(a_t | s_t) \hat{A} \big]
2. Trust Region Policy Optimisation
As a matter of fact, $L^{PG}(\theta)$ often suffers from destructively large policy updates. Hence, in TRPO, they have adapted two options to control the updating policy.
- Constraint on the update ratio
- Penalty for updating
Let me cover one by one.
1. Constraint on the update ratio
Based on the concept which is putting the constraint on the size of the policy update.
max_{\theta} \space \hat{E_t} \big[\frac{π_{\theta}(a_t | s_t) }{π_{\theta_{old}}(a_t | s_t) } \hat{A} \big]\\
constraint\\
\hat{E_t} \biggl[KL \big( π_{\theta}(. | s_t) , π_{\theta_{old}}(. | s_t) \big) \biggl] \leq \delta
In this case, $\delta$ is a hyperparameter, hence, we have to manually decide it.
2. Penalty for updating
Indeed, in the paper, they have mentioned that TRPO justifies to be applied a penalty for policy updating, however, it turned out that the selection of penalty coefficient was incredibly difficult. So, in the end, it didn't go well. But I would like to briefly describe it here.
max_{\theta} \space \hat{E_t} \biggl[\frac{π_{\theta}(a_t | s_t) }{π_{\theta_{old}}(a_t | s_t) } \hat{A} - \beta KL \big( π_{\theta}(. | s_t) , π_{\theta_{old}}(. | s_t) \big) \biggl]
Contribution: PPO
In order to construct their approach, let me cover two important concept here.
- Clipped Surrogate Objective
- Adaptive KL Penalty Coefficient
1. Clipped Surrogate Objective
Let $r(\theta)$ be
\frac{π_{\theta}(a_t | s_t) }{π_{\theta_{old}}(a_t | s_t) }\\
L^{CPI}(\theta) = \hat{E_t} \big[\frac{π_{\theta}(a_t | s_t) }{π_{\theta_{old}}(a_t | s_t) } \hat{A} \big] = \hat{E_t} \big[ r(\theta) \hat{A} \big]
where CPI stands for conservative policy iteration.
L^{CPI}(\theta) = \hat{E_t} \biggl[ min \big( r(\theta) , clip(r(\theta), 1-\epsilon, 1 + \epsilon) \big ) \hat{A} \biggl]\\
With this approach, the second term modifies the surrogate objective by clipping the probability ratio, which remove the incentive for moving $r_t$ outside of the interval $[1 - \epsilon, 1 + \epsilon]$.
With this scheme, we only ignore the change when it would make the objective improve, but we include it when it makes it worse.
2. Adaptive KL Penalty Coefficient
Another approach which can be hopeful to improve the TRPO is to use a penalty on KL divergence. Adapting the penalty coefficient achieve some target value of the KL divergence $d_{target}$ each policy update. in their experiment, they have found that it got worse than Clipped Surrogate Objective.

Regarding to the hyperparameter $\beta$, they have analysed the optimal value for it through the experiment and decided to assign 2 to it, yet, according to their research, it is said that essentially it doesn't matter what kind of number you assign to it.
Algorithm
To efficiently reduce the bias arising in the neural function approximate, they have combined the $L^{CLIP}, L^{KLPEN} and \space L^{PG}$.
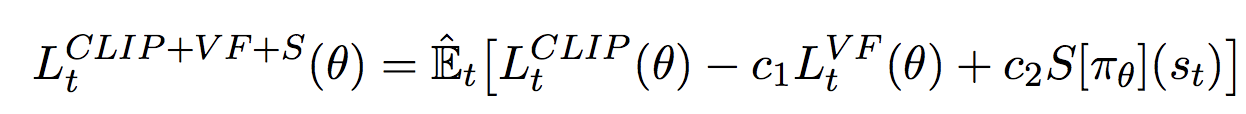 where $c_1, c_2$ are coefficients, s denotes an entropy bonus and
where $c_1, c_2$ are coefficients, s denotes an entropy bonus and
L^{VF}_t = (V_{\theta}(s_t) - V^{target}_t)^2
Then applying the truncated policy gradient method introduced by Minh in 2016, it is well suited. In this scheme, it requires an advantage function not to look beyond timestep $T$.
- Normal advantage function
\hat{A_t} = - V(s_t) + r_t + \gamma r_{t+1} + ... + \gamma^{T-t+1} r_{T-1} + \gamma^{T-t}V(s_T)
- Truncated advantage function

