Diff-SVCをWindows10環境で実行させるための作業メモ
そもそもDiff-SVCとは
簡単に言うと、機械学習を使って「ある歌声」を「別の声質」に変換させるボイスチェンジャー。
自分の声を学習させ、自分の好きな曲を歌わせてみた、ということもできるかも。
開発者については下記URLを参照↓
作業環境
| OS等 | バージョン等 |
|---|---|
| Windows | Windows 10 Pro 64bit |
| 外付けGPU | ケース:Razer Core X Chroma GPU:RTX 3060Ti 8GB |
| Python | Python 3.8.2 |
| Pycharm | PyCharm 2020.1 (Community Edition) |
| CUDA | CUDA Toolkit 11.3 |
| Torch | Torch1.12.1 |
1. 事前準備
1. CUDAのインストール
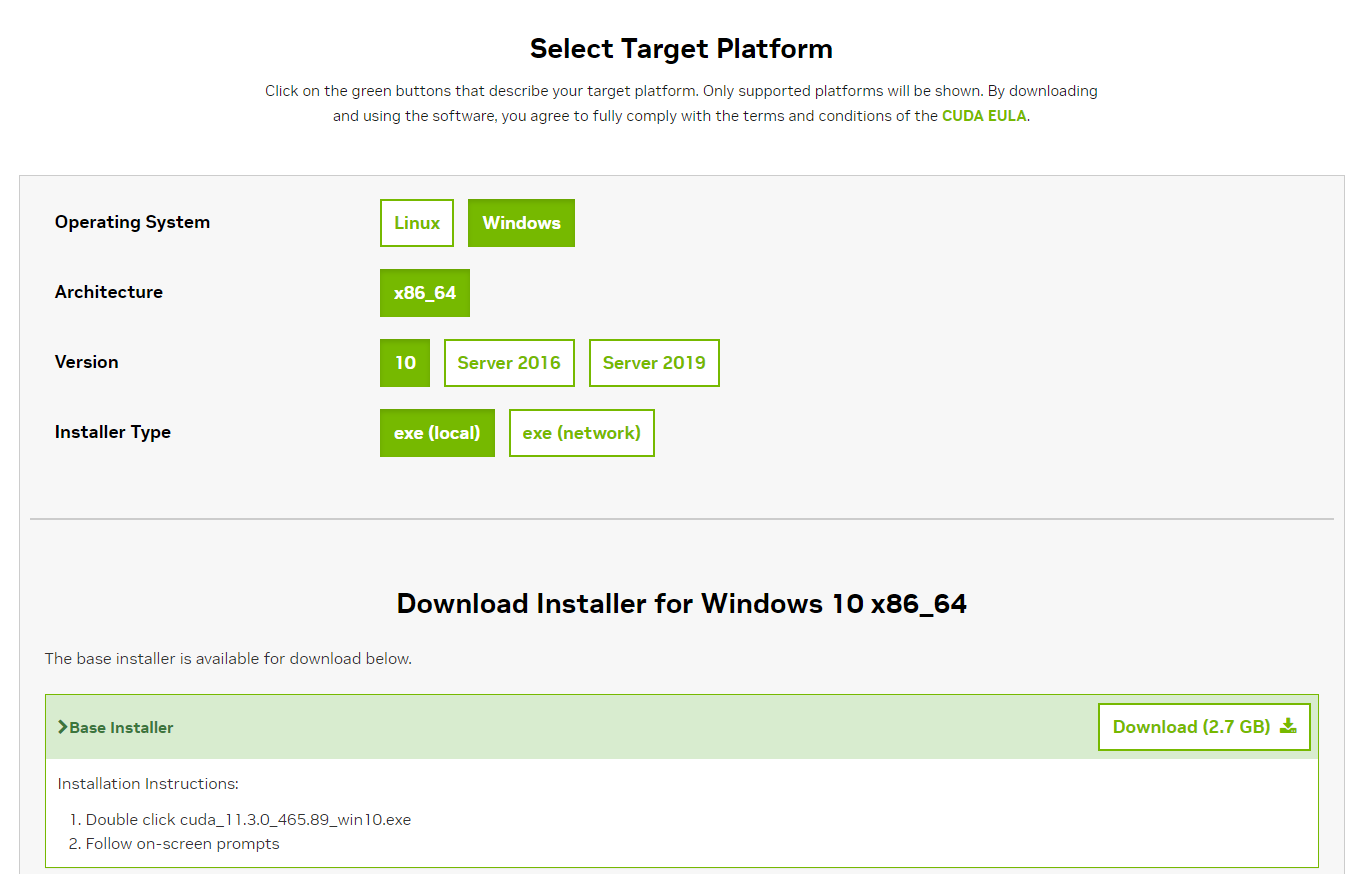
CUDA Toolkit 11.3を下記URLからダウンロードし、実行する。
指定内容は下図の通り
2. Pycharmで新規プロジェクトを作成し、Diff-SVCを配置
Pycharmで新規プロジェクト作成後、Terminal上で下記コマンドを実行
git clone https://github.com/prophesier/diff-svc.git
3. Torchのインストール
下記URLから必要なコマンドを取得し、実行する
実行コマンド:
pip install torch==1.12.1+cu113 torchvision==0.13.1+cu113 torchaudio==0.12.1 --extra-index-url https://download.pytorch.org/whl/cu113
4. 必要なパッケージをインストール
下記コマンドを実行
(注意:ここでエラー発生)
pip install -r requirements.txt
エラー内容:
note: This error originates from a subprocess, and is likely not a problem with pip.
ERROR: Failed building wheel for webrtcvad
ビルドがうまくいかなかったみたい。
解決方法:
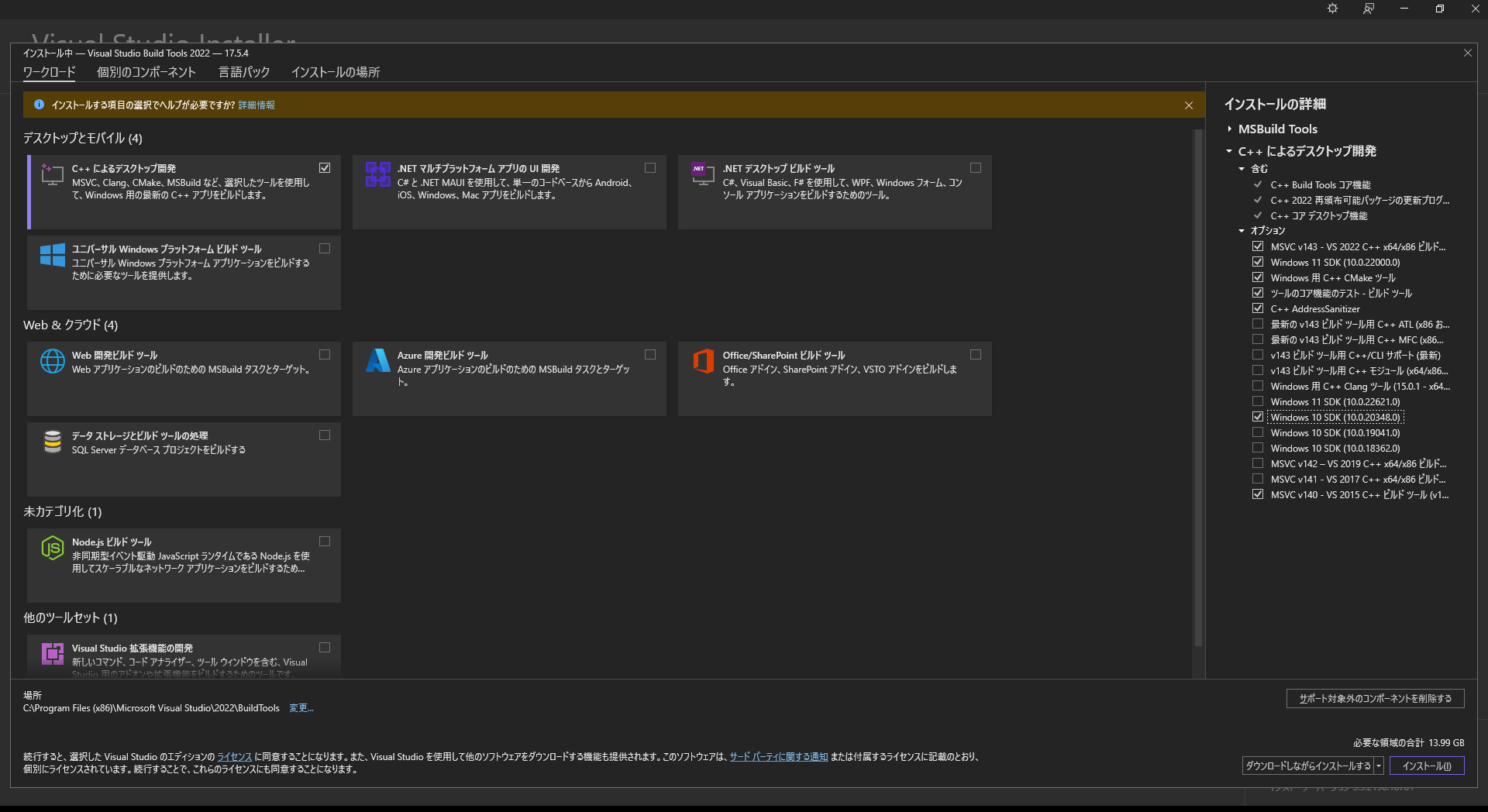
エラーメッセージの中にURLが記載されていたので、そのURL先からインストーラーをダウンロードして実行
インストール時のオプションに指定したものは下図の通り
インストール完了後、コマンドを再実行
※コマンドを再実行する前に、環境変数を追加したかもしれない
5. フォルダ作成と学習モデルの配置
Diff-SVCを配置した階層と同じ階層に下記フォルダを作成。
(このあたりは、「./training/config.yaml」を見て、必要そうなフォルダを作成した。)
・checkpoints
・checkpoints/0102_xiaoma_pe
・checkpoints/0109_hifigan_bigpopcs_hop128
・checkpoints/hubert
・data
・data/raw
下記URLから必要なモデルをダウンロード。
(とりあえず動かすために最低限必要そうなものだけ)
<ダウンロードしたモデル>
・0102_xiaoma_pe.zip
・0109_hifigan_bigpopcs_hop128.zip
<ダウンロードしたモデル>
・nsf_hifigan_20221211.zip
※解凍後の資材名を「hubert_soft.pt」にリネーム
<フォルダ階層>
※赤字が新規に追加したフォルダ 青字が新規に追加したモデル
新規プロジェクト
┣ checkpoints
┃ ┣ 0102_xiaoma_pe
┃ ┃ ┣ model_ckpt_steps_60000.ckpt
┃ ┃ ┗ config.yaml ←使用しているか不明
┃ ┣ 0109_hifigan_bigpopcs_hop128
┃ ┃ ┣ model_ckpt_steps_280000.ckpt
┃ ┃ ┗ config.yaml ←使用しているか不明
┃ ┗ hubert
┃ ┃ ┗ hubert_soft.pt
┣ data
┃ ┣ raw
┃ ┗ (任意。「training/config.yaml」の「raw_data_dir」と一致していれば良し。)
┃ ※ここに前処理で学習させる音声データを格納する
┣ preprocessing、trainingなど、Diff-SVCを配置したときダウンロードした資材
(省略)
┣ requirements.txt
┗ infer.py
2. 前処理
学習させたい音声データを「data/raw/(任意)」フォルダに格納し、プログラムを実行する。
※実行するコマンドはGitのページを参考に、Pycharmで実行できるようにConfigurationsを作成している。
実行するコマンド:
export PYTHONPATH=.
CUDA_VISIBLE_DEVICES=0 python preprocessing/binarize.py --config training/config.yaml
実行時の構成は下記の通り
| 項目名 | 設定値 | コメント |
|---|---|---|
| Name | binarize | |
| Script path | …\preprocessing\binarize.py | 実行したいPythonファイルの絶対パス |
| Parameters | --config training/config.yaml | 実行するコマンドのオプション指定の箇所を設定 |
| Enviroment variables | PYTHONUNBUFFERED=1;CUDA_VISIBLE_DEVICES=0 | 実行するコマンドの環境変数設定を追加 |
| Working directory | 新規プロジェクトのパス |
実行時に「RuntimeError: CUDA out of memory.」が発生したので、バッチサイズを少なくして再実行。
※他にもいじったかもしれないが、メモがなかった
<修正箇所>
資材名:preprocessing/data_gen_utils.py
対象行:203
修正内容:1024→512
うまく実行できていれば、「training/config.yaml」の「binary_data_dir」に設定したフォルダパスにファイルが作成されているはず。
3. モデル学習
※実行するコマンドはGitのページを参考に、Pycharmで実行できるようにConfigurationsを作成している。
実行するコマンド:
CUDA_VISIBLE_DEVICES=0 python run.py --config training/config.yaml --exp_name [your project name] --reset
実行時の構成は下記の通り
| 項目名 | 設定値 | コメント |
|---|---|---|
| Name | run | |
| Script path | run.py | 実行したいPythonファイルの絶対パス |
| Parameters | --config training/config.yaml --exp_name (プロジェクト名) --reset | 実行するコマンドのオプション指定の箇所を設定 |
| Enviroment variables | PYTHONUNBUFFERED=1;CUDA_VISIBLE_DEVICES=0;PYTORCH_CUDA_ALLOC_CONF=max_split_size_mb:128 | 実行するコマンドの環境変数設定を追加 PYTORCH_CUDA_ALLOC_CONFは「RuntimeError: CUDA out of memory.」が発生した時、試行錯誤している中で追加したかもしれない |
| Working directory | 新規プロジェクトのパス |
実行時に「RuntimeError: CUDA out of memory.」が発生。
開発者のGitページによると、下記設定値から動的に算出しているらしい。
max_frames: 42000
max_input_tokens: 6000
max_sentences: 88
max_tokens: 128000
上の「max_sentences:」を「5」に修正して実行。
※この値にしたらとりあえず「RuntimeError」は発生せずに動き続けた。
「RuntimeError」とは異なるエラーが発生
エラー内容:
OSError: [WinError 1455] ページング ファイルが小さすぎるため、この操作を完了できません。
解決方法:
下記ページを参考にした
エラーを解決し、再実行。
そして完了するまで待つ・・・・・・
・・・・・・
・・・・・・終わらない
ので、「checkpoint/(プロジェクト名)」に学習モデルが出力されているのが確認出来たら、
この処理を手動で止めて、変換処理を行ってみる。
4. 変換処理
「infer.py」の中身を少し書き換える。
修正箇所:
| 行数 | 修正前 | 修正後 |
|---|---|---|
| 76 | project_name = "yilanqiu" | project_name = "(プロジェクト名)" |
| 77 | model_ckpt_steps_246000.ckpt | (「3. モデル学習」で作成されているモデルのファイル名) |
| 81 | file_names = ["青花瓷.wav"] | file_names = ["変換したい音声データ"] |
これまでの手順と同様に、実行の構成を作成してプログラムを実行
| 項目名 | 設定値 | コメント |
|---|---|---|
| Name | infer | |
| Script path | infer.py | 実行したいPythonファイルの絶対パス |
| Parameters | なし | |
| Enviroment variables | CUDA_VISIBLE_DEVICES=0 | |
| Working directory | 新規プロジェクトのパス |
うまく実行できていたら、「result」フォルダ配下に音声変換後のファイルが作成されている。
5. 感想
変換後の音声データについては、「まあ、変わってるね」くらいの印象。学習させるデータ、学習回数、configの設定値等、色々変えればもっと劇的に変わるかもしれない。
今回は、この「Diff-SVC」をWindows10(ローカル)環境で動かせたので良しとしよう。
あとは、この開発者の方が出している論文を読んだり、プログラムの中を追ったりして理解を深めていこう。