1. はじめに
この一年間Slackでやり取りされたメッセージはどのような内容がメインだったのかを確認しようと思います。今回はSlackメッセージからワードクラウドを作成し可視化します。Tableauでワードクラウドを作成するためには、頻出単語とそのカウント数をリスト化する必要があります。Pythonと自然言語処理で用いられる日本語の形態素解析エンジンとして知られているMeCabを使用しました。
2. 今回の対象データ
【対象データ】
自社のSlackの「パブリックチャンネルメッセージ」を対象。
【抽出対象と方法】
データは全従業員メッセージ(返信を含む)を抽出し、テキストファイルとして出力。
- 全従業員
- 抽出期間 1年
- データ件数 30,000
- リアクションの絵文字は対象外
3. 前処理
3.1 MeCabのセットアップ
3.1.1. MeCabをインストール
セットアップ方法は割愛。
【参照先】https://techacademy.jp/magazine/22052
3.1.2. Python環境のセットアップ
Python上からMeCabを使用するためにmecab-python3をインストール。
※pip install でOK。
pip install mecab-python3
3.1.3. Pythonコーデイング
処理としては以下の手順。
- モジュールのインポート
- テキストファイルの読み込み
- MeCabで形態素解析し、名詞のみをリストに格納
- 頻出順に出力
- CSVファイルとして書き出し
最終的なコードがこちら。
import csv
import MeCab
import sys
import re
from collections import Counter
\# テキストファイル読み込み
with open('<ファイルのパス>', encoding='utf-8') as f:
data = f.read()
\# 解析
mecab = MeCab.Tagger('/usr/local/lib/mecab/dic/mecab-ipadic-neologd/')
parse = mecab.parse(data)
lines = parse.split('\n')
items = (re.split('[\t,]', line) for line in lines)
\# 名詞をリストに格納
words = [item[0]
for item in items:
if (item[0] not in ('EOS', '', 't', 'ー') and
item[1] == '名詞' and item[2] == '一般')]
\# 頻度順に出力
counter = Counter(words)
header = ['word','count']
\# データをCSVに書き出し
with open('sample_slack.csv','w',newline='',encoding='utf-8') as f:
writer = csv.writer(f)
writer.writerow(header)
for word, count in counter.most_common():
writer.writerow([word,count])
Slack抽出結果の頻出名詞トップ20がこちら。
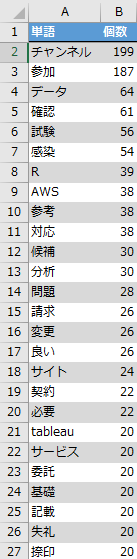
上位の「チャンネル」と「参加」はSlackにメンバーが登録された時に自動的に作成されるメッセージで、メンバー間のコミュニケーションではないため分析から外します。また意味不明な単語も外しました。
4. Tableau側の設定
4.1. データソースに接続
Tableau Desktop を開き、先程書き出したCSVファイルに接続してデータを確認。
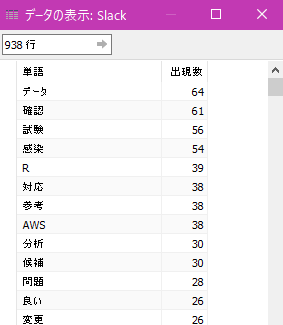
これでワードクラウドを作るためのデータが準備完了。
実際にワードクラウドを作成します。
4.2. ワードクラウドの設定
- ディメンションから「単語」を[マーク]カードの[テキスト]にドラッグ。
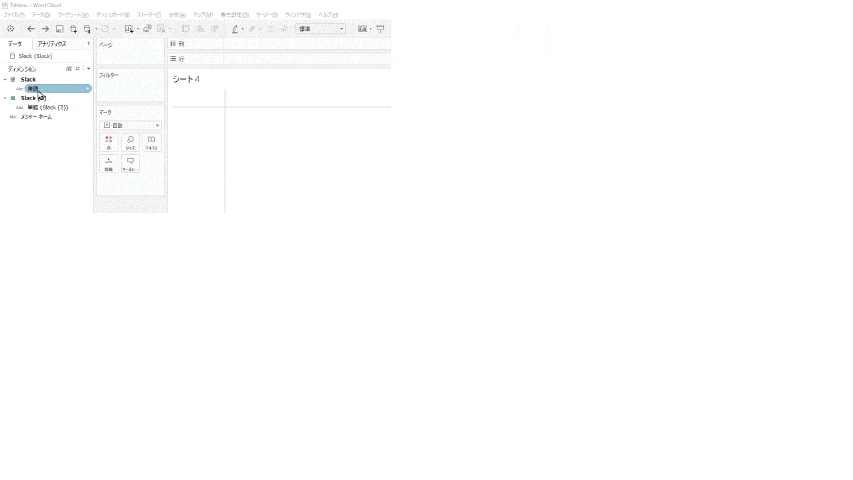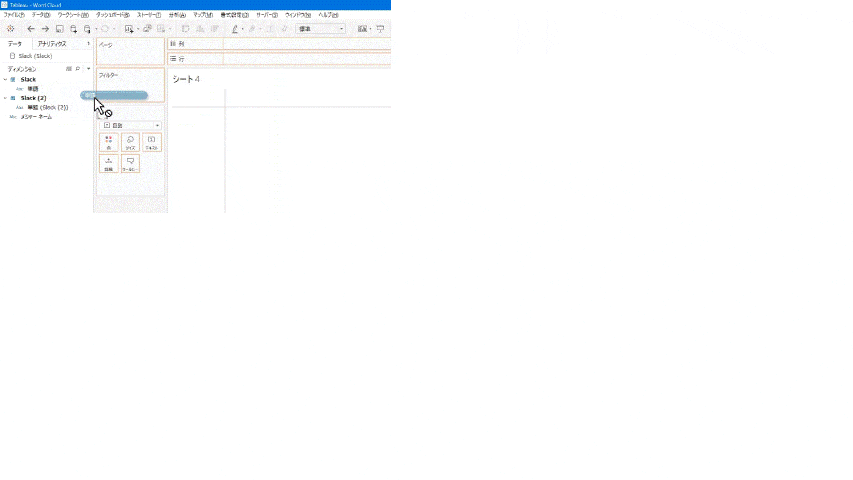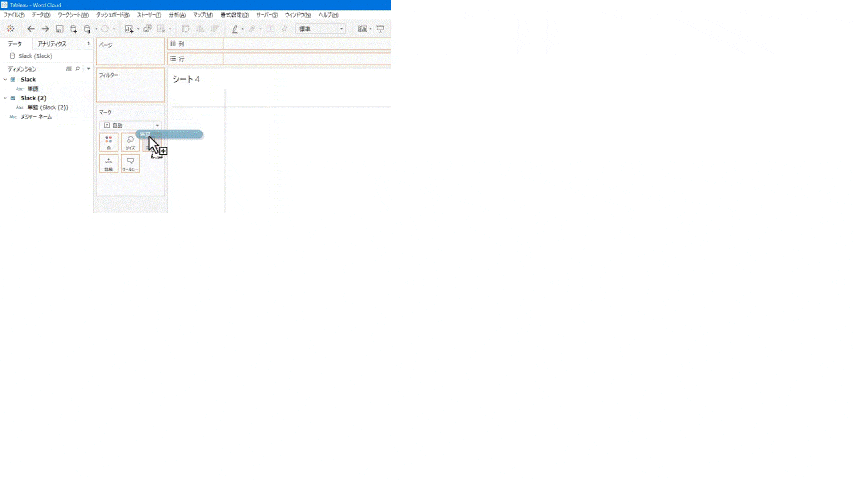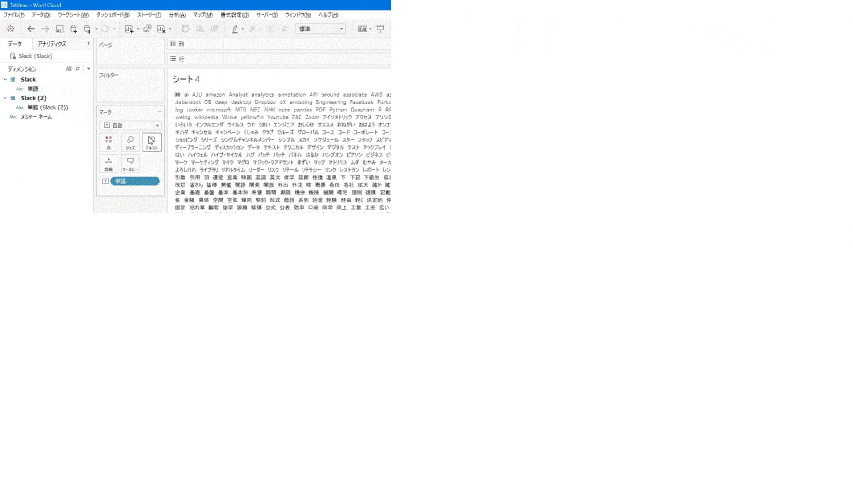
- メジャーから「出現数」を[マーク]カードの[サイズ]にドラッグ。
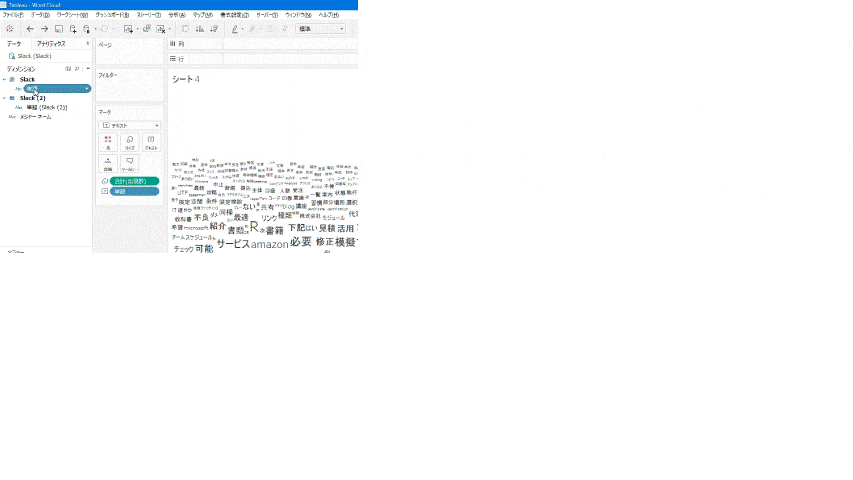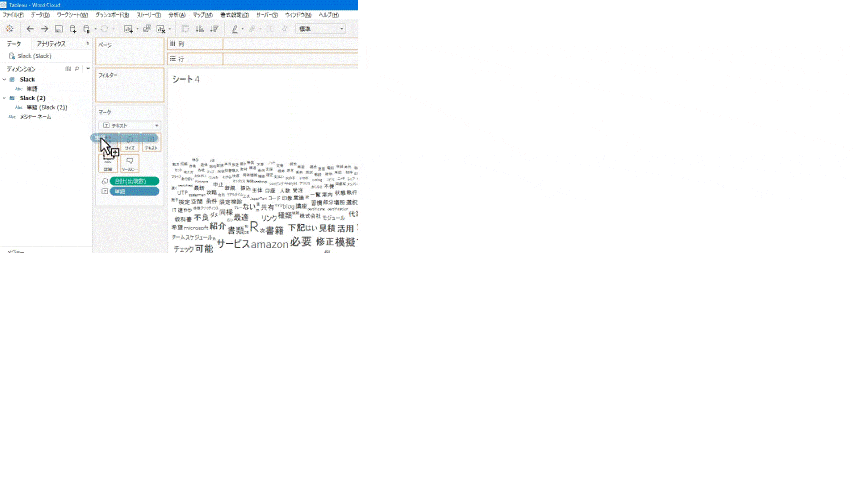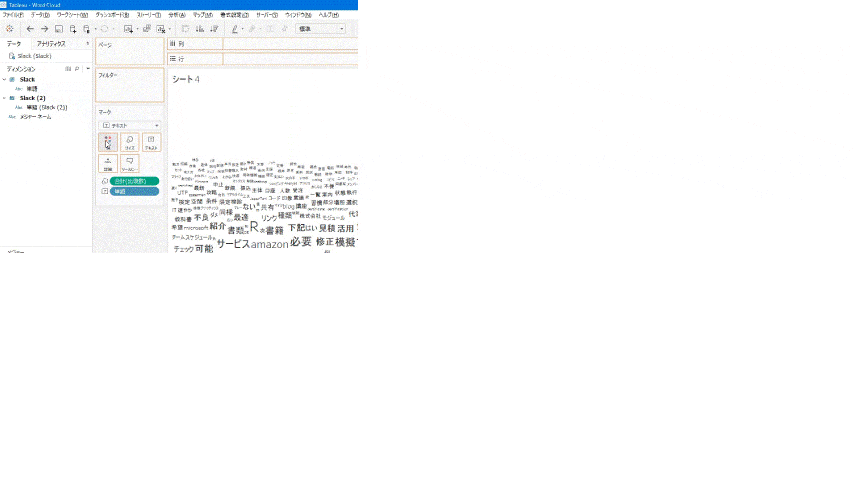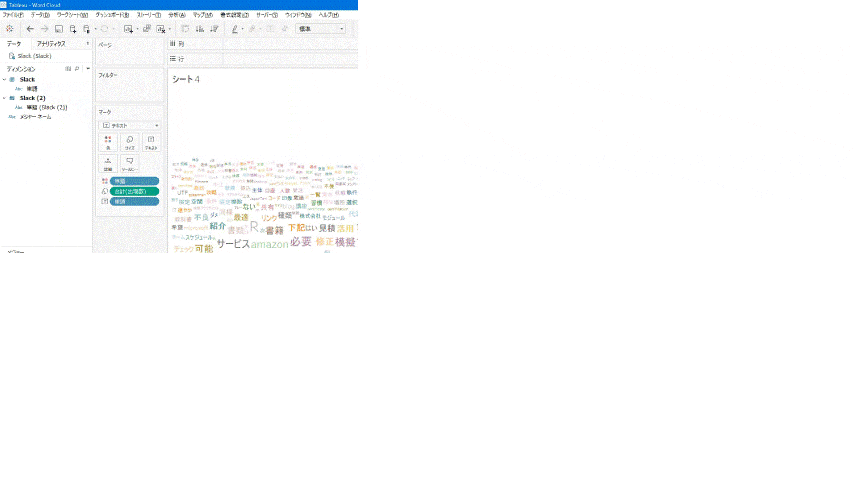
- Vizがデフォルトでは「ツリーマップ」になったので、マークタイプを[自動]から[テキスト]に変更。

- 色を追加するには、ディメンション「単語」を[マーク]カードの[色]にドラッグ。
- Viz右側の凡例は不要なので、非表示。


データ数が930あると出現数が少ない単語はほとんど見えません。見やすくするために、出現数をフィルターで3回以上に絞ります。

データ数は381と半分以下になり、スッキリと見やすくなりました!
ところで、私が現在担当しているプロジェクトでは「Sisense」を使用しており、Slackで頻繁にメッセージに使用しているのですが、プライベートチャンネルのため今回は対象外です。プライベートチャンネルも対象にすると違った結果となると思いますので、次回チャレンジします。Sisenseについては、こちらをご参考ください。
Sisense Japan: https://www.sisense.com/ja/
Insight Lab Sisense ナレッジ: https://knowledge.insight-lab.co.jp/sisense
4.3. まとめ
今回は、ワードクラウドを作成しました。
Pythonを使った前処理が必須となりますが、なかなか綺麗なVizです。
それではまた!