概要(タイトルの通り)
Google CloudのコンピューティングリソースであるCloud Runから、同一プロジェクト内にあるCloud SQLインスタンスへ接続する。
開発目的でローカルからクラウド上のSQLインスタンスに接続する場合、Google Auth Proxyを用いて接続することが可能。これは本記事のスコープ外なので、下記記事を参照されたい。
環境・前提
- スタンダードなWeb3層(three-tier)アーキテクチャ
- コンピューティングにはCloud Run、データベースにはCloud SQLを使用
- データベースはインターネットから接続できないようにしたい
- GitHubなどを用いてCI/CDを実現したいが、接続先などの機密情報が漏洩しないようにしたい
結論
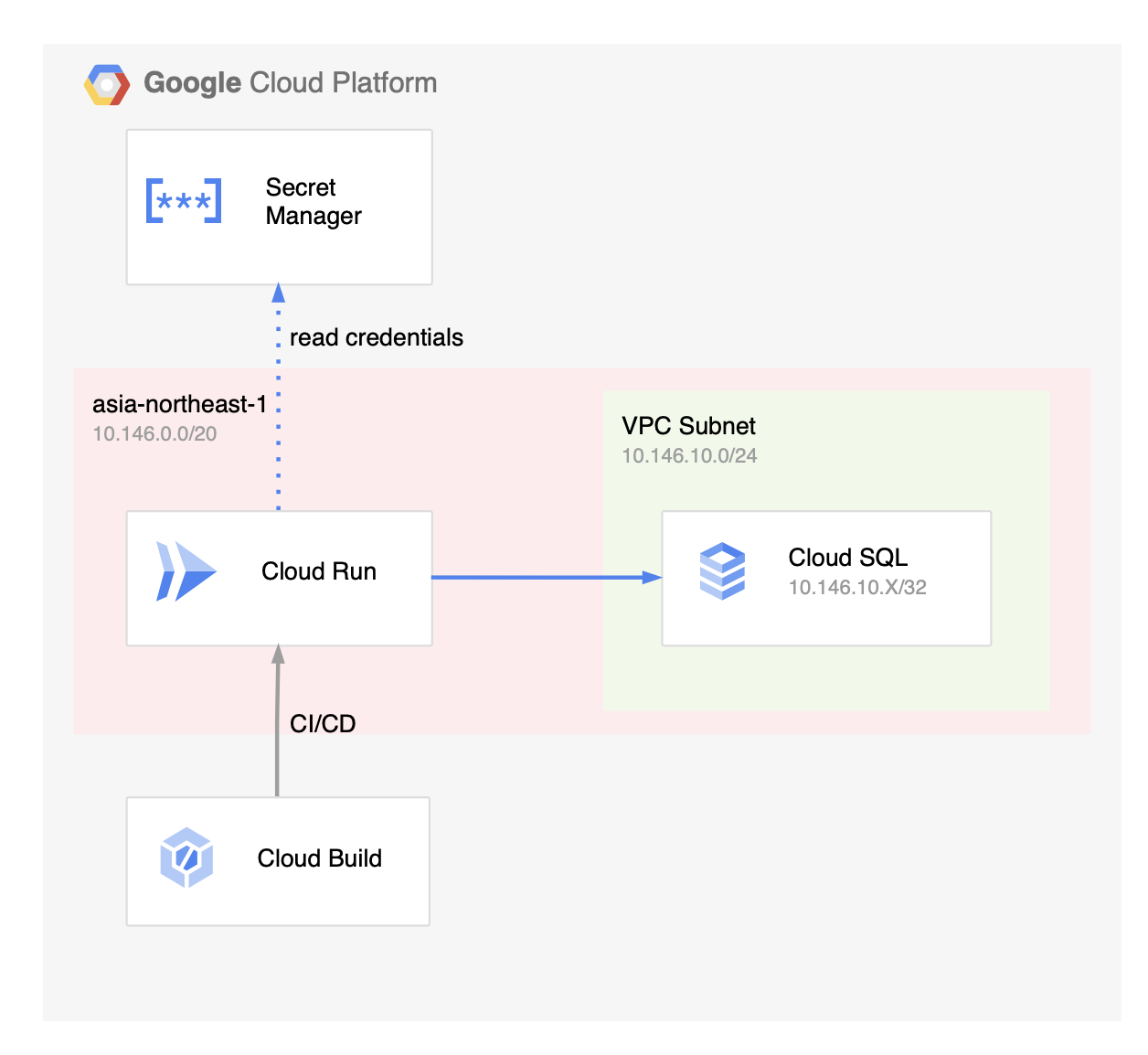
- Cloud SQLにVPCのプライベートIPアドレスをアタッチする
- Cloud Runの設定で、「Cloud SQL接続」を有効化する
- Cloud Runのネットワーク設定で、「VPCに直接トラフィックを送信する」を指定する
- Cloud RunからSQLに接続する際、プライベートIPアドレスを指定する
実際に環境を構築する際は
VPC設定(オプション) → Cloud SQL設定 → Secret管理 → Cloud Run設定
の順番で進めると良い。
Cloud SQLにVPCのプライベートIPアドレスをアタッチする
「インスタンスの作成」-「接続」-「プライベートIP」を有効化する。
「プライベートサービスアクセス(PSA)の設定」で、アタッチするプライベートIPアドレスの範囲を指定することができる。
基本的に下記構成で動く。
| ネットワーク | 割り振られたIP範囲 |
|---|---|
| default | 自動的に割り当てられたIP範囲を使用する |
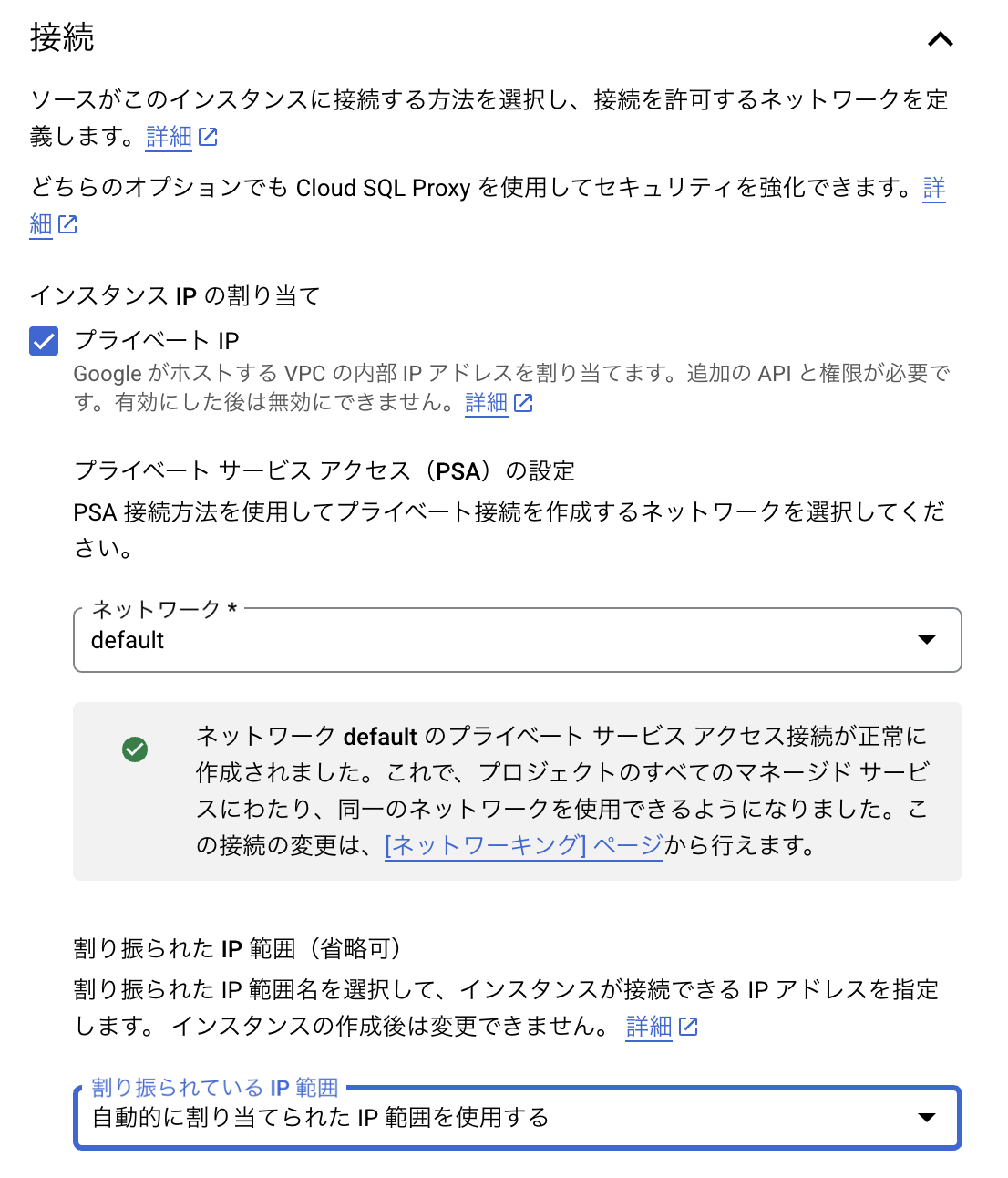
上記の設定でインスタンスを作成すると、割り振られるIPアドレスは「10.50.XXX.XXX」などになっているはず。
詳細なネットワーク設計を行いたい場合は、あらかじめ「VPCネットワーク」-「VPCネットワーク」からネットワークセグメントを作成し、インスタンス作成時に指定する。

インスタンスのIPアドレスは、インスタンス作成後は変更できないので注意。
Cloud Runの設定で、「Cloud SQL接続」を有効化する
「Cloud Run」-「サービス」からCloud Runインスタンスを作成する。
「コンテナをデプロイ」「リポジトリを接続」「関数を作成」の選択肢があるが、ケースに応じて選択すれば良い。

「コンテナ、ボリューム、ネットワーキング、セキュリティ」内「コンテナ」の最後に「Cloud SQL接続」があるので、先ほど作成したSQLインスタンスを指定する。

次にネットワークの設定をするので、まだインスタンスは作成しない。
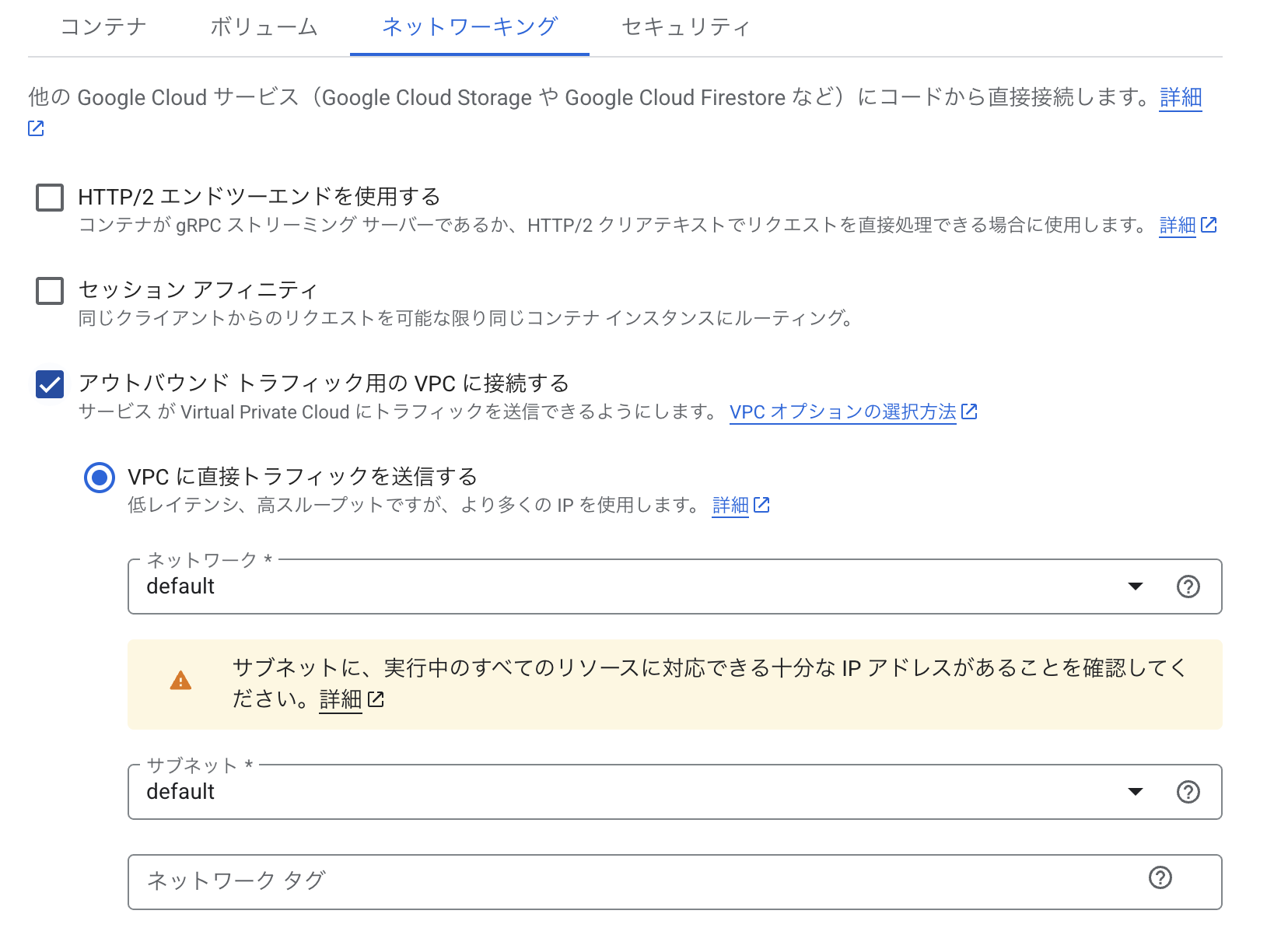
「アウトバウンドトラフィック用のVPCに接続する」を有効化する
先ほどの「コンテナ、ボリューム、ネットワーキング、セキュリティ」内「ネットワーキング」で「アウトバウンドトラフィック用のVPCに接続する」を有効化する。
「VPCに直接トラフィックを送信する」と「サーバーレスVPCアクセスコネクタを使用」の選択肢があるが、一般的に前者を選択すれば良い。
ここまでの設定が終われば、Cloud Runインスタンスを作成する。
サーバーレスVPCアクセスコネクタは費用が若干嵩む点でも採用ハードルが高い。
https://cloud.google.com/vpc/docs/serverless-vpc-access?hl=ja
プライベートIPアドレスを指定してCloud RunからCloud SQLに接続する
Cloud RunからCloud SQLへの接続方法は、ドキュメントに記載がある。
接続ホストにCloud SQLインスタンスのプライベートIPアドレスを指定すればよい。
接続先情報(IPアドレス、ユーザ名・パスワードなど)の管理についてはこの後説明する。
① SQL Alchemyの場合
import sqlalchemy
pool = sqlalchemy.create_engine(
# Equivalent URL:
# postgresql+pg8000://<db_user>:<db_pass>@<db_host>:<db_port>/<db_name>
sqlalchemy.engine.url.URL.create(
drivername="postgresql+pg8000",
username=db_user,
password=db_pass,
host=db_host, # db_host = "10.50.XXX.XXX"
port=db_port,
database=db_name,
),
# ...
)
② Prismaの場合
# schema.prisma
generator client {
provider = "prisma-client-py"
}
datasource db {
provider = "postgresql"
url = env("DATABASE_URL")
}
# .env
DATABASE_URL="postgresql://<db_user>:<db_pass>@<db_host>:<db_port>/<db_name>"
# db_host = "10.50.XXX.XXX"
おまけ:機密情報の扱い
データベースのIPやユーザ名・パスワードなどは、万一漏洩すると不正接続等を招く恐れがあり、GitHubリポジトリにアップロードすべき内容ではない。また、同一のGoogle Cloudプロジェクトに参加しているユーザーであっても、アクセス管理を行うべきケースが多々存在する。
機密情報をローカルからGoogle Cloud環境に配置する方法は下記のように複数存在するが、特段の理由がなければSecret Managerを使うのが良い。
| シークレットの保存先 | 推奨 | 備考(理由) |
|---|---|---|
| Secret Manager | ○ | GCP IAM によるアクセス制御、監査ログ、バージョン管理が可能なため最も安全・推奨される方法 |
| 環境変数(Cloud Run/Cloud Functionsなどに設定) | ○ | シークレット自体はSecret Managerから取得し、環境変数に渡す形が安全。 |
| GitHubの環境変数(Actions用など) | △ | GitHubリポジトリの権限に依存し、外部環境との統合や多環境デプロイにやや不向き。ビルドログに環境変数の値が残る |
| コードに埋め込む | × | 誰でも読める状態でリポジトリに残り、セキュリティ上重大なリスク。絶対に避けるべき |
.envファイル(GitHubにアップする) |
× | ファイルとして分離されていても、リポジトリに上がるため、コードに埋め込むのと同等。 |
| GCS(Cloud Storage)に保存 | × | バケットのアクセス制御が必要で、専用用途ではない。平文で置くことが多く非推奨 |
Secret Managerは「セキュリティ」-「Secret Manager」から利用できる。
Secret Managerで作成したシークレットは、Cloud Runの「コンテナ、ボリューム、ネットワーキング、セキュリティ」から環境変数としてコードに取り込むことができる。
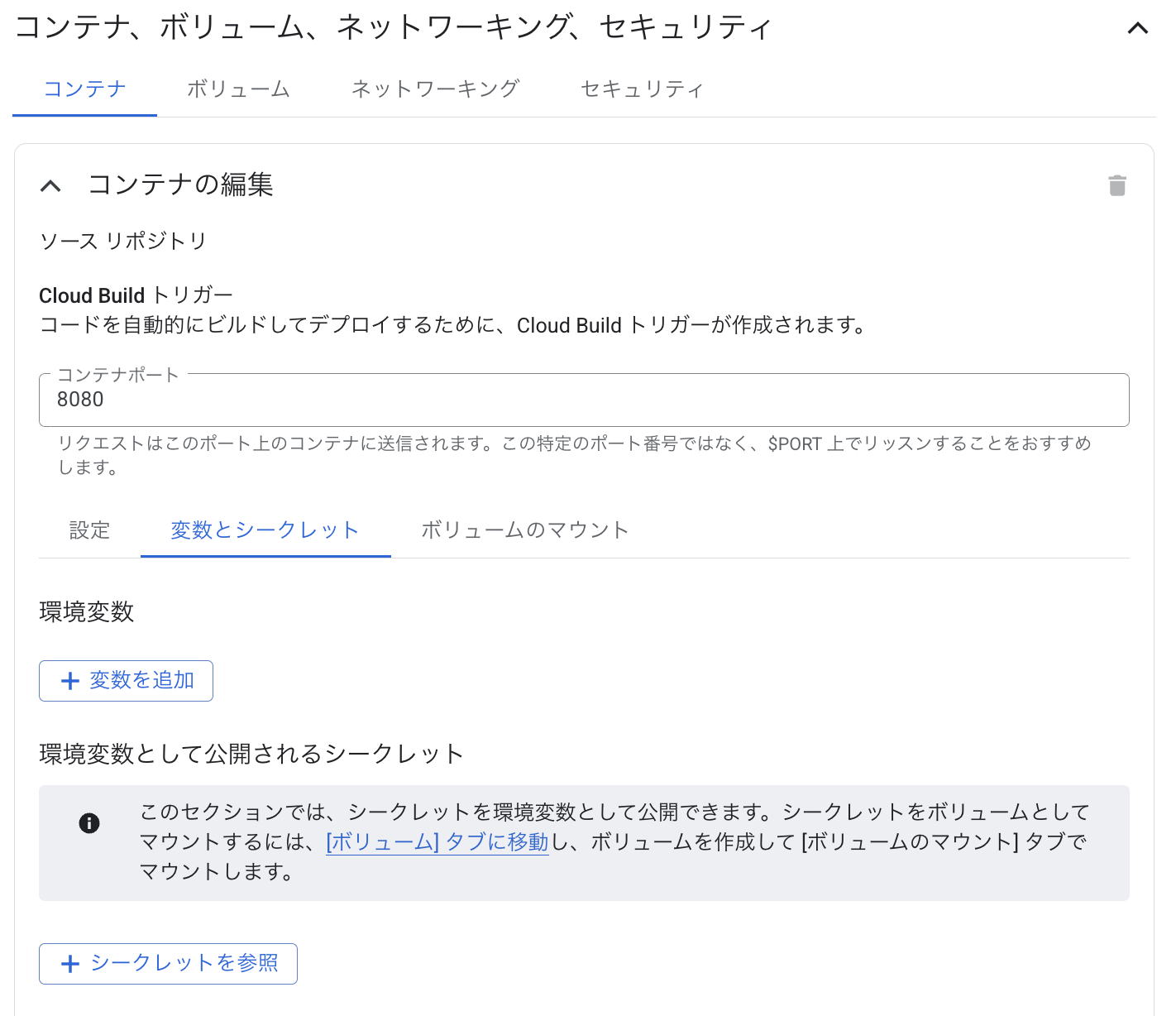
この設定を行えば、コードからは環境変数ファイル.envを利用するのと同様に、シークレットを扱える。
from dotenv import load_dotenv
DATABASE_URL: str = os.getenv("DATABASE_URL", None)
まとめ
Cloud RunとCloud SQLをセキュアに接続するためには、VPCネットワークやSecret Managerを活用した構成が不可欠です。本記事で紹介した設定を押さえておけば、安全かつ柔軟にサービスを展開できます。セキュリティと運用性の両立を意識しながら、ぜひ実践に取り入れてみてください。