PCに不慣れな人でも機械学習がとりあえず試せるようなアプリを作ることになった。
ユーザーに学習用データや予測したい未知データをどうやって整理してもらうかいろいろと考えた結果、
ひな形を1つのExcelファイルにして、それを埋めてもらう形が最も理解されやすかった。
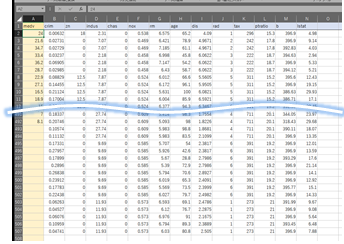
ひな形はこんな感じに。
・A列に目的変数
・B列以降に特徴量
・1行目は変数名,2行目以降にデータ
・シートの上のほうに学習用データをまとめて配置
・未知データはその下にまとめて配置し、A列は空白
アプリ側でデータの加工はせず、エラー値の除去や特徴量の正規化、交互作用などの追加はユーザーに任せることに。
これをpandasのExcelFileメソッドで読み込み、学習用X,Yと未知Xに分割する。
test.py
def xlsx_read():
xl_path = "C:\test.xlsx"
xl= pd.ExcelFile(xl_path)
df = xl.parse("data") #シート名を指定してDataFrameにする
df_measured_X = df.dropna().iloc[:,1:len(df.dropna().columns)] #学習用X:dropna()でNaNがある行を除いて、ilocで左端以外の列を抽出
df_measured_Y = df.dropna().iloc[:,0] #学習用Y:dropna()でNaNがある行を除いて、ilocで左端の列のみ抽出
df_unknown_X = df[df.isnull().any(1)].iloc[:,1:len(df[df.isnull().any(1)].columns)] #未知X:isnull()でNaNがない行を除いて、ilocで左端以外を抽出
return df_measured_X, df_measured_Y, df_unknown_X #タプルで返す 学習用X,学習用Y,未知X の順