はじめに
スクレイピングでSeleniumを使用した際に記述したコードのレシピをまとめました。Selenium4に対応しています。不備があるかもしれませんが、順次追記していきます。
パッケージのインストール
chromedriver_binaryはChromeの「設定」→「Chromeについて」でバージョンが確認できます。
pip install selenium
pip install chromedriver_binary==xx.x.xxxx.xx
import
from selenium import webdriver
import chromedriver_binary
URLを開く
driver=webdriver.Chrome()
driver.get('URL')
要素の検索
以下のコードをimportに足す必要がある。
from selenium.webdriver.common.by import By
クラス属性で検索
sampleというクラス名の場合以下のようになる。
element = driver.find_elements(By.CLASS_NAME,"sample")
ID属性の場合は、By.ID、タグ名の場合は、By.TAG_NAME、name属性の場合はBy.NAMEに変更する。
どうしても取得できない時はXPathを使う
XPathの取得手順
- サイトの適当な場所で右クリック
- 検証を押す
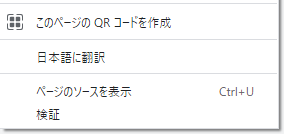
- 左上のボタンをクリック
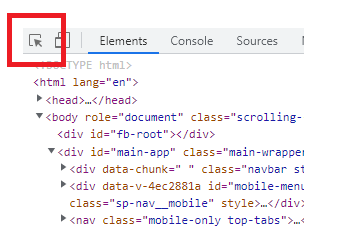
- 目的の要素部分にカーソルを合わせてクリック
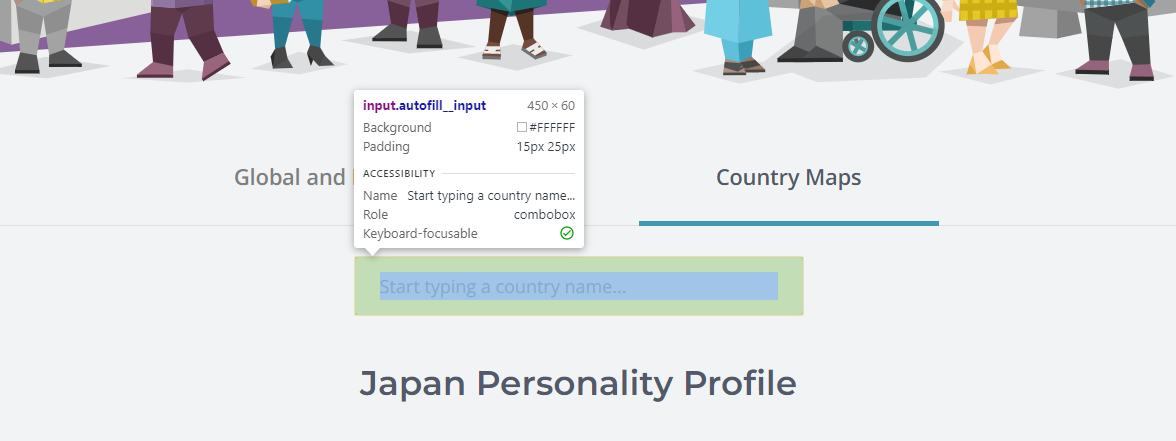
- 水色で塗られた部分を右クリック
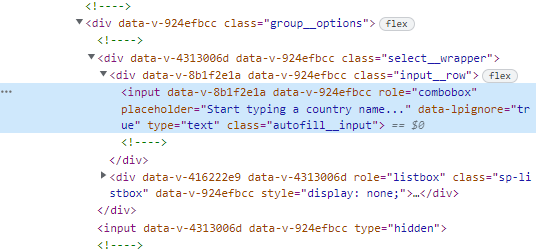
- Copy→Copy XPathまたはCopy full XPathをクリックし、パスをコピー
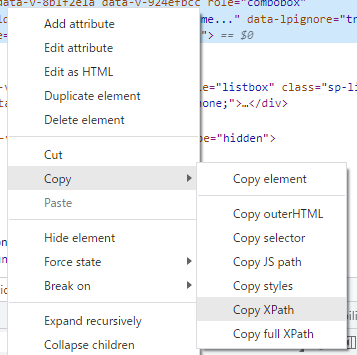
これでパスのコピーは完了したので、あとはこれを貼り付けるだけです。
element = driver.find_element(By.XPATH,"パス")
ある要素の中に限定して要素を取得
element1=driver.find_element(By.XPATH,"パス")
element2=element1.find_element(By.CLASS_NAME,"sample")
条件を満たすすべての要素をリストで取得
find_elementをfind_elementsというように複数形に変更すればよい。単数形の場合は、条件を満たす一番最初の要素だけ取得される。リスト型なので、一つ一つの要素を取得する場合にはfor e in elements: といったようにfor文で記述します。
elements=driver.find_elements(By.CLASS_NAME,"sample")
要素の操作
テキストボックスに入力
element.send_keys('入力したい文字')
クリックする
element.click()
要素内のテキストを取得
element.text
上記方法で空の文字列が返ってくる場合は以下の方法で取得。
element.get_attribute("textContent")
参考URL:https://qiita.com/riikunn_ryo/items/68c7621baaa54cf27230
その他使えるレシピ
ヘッドレスモード
ヘッドレスモードはざっくりいうと、ウェブページを表示しないモードです。
まず、importの部分で以下を追記します。
from selenium.webdriver.chrome.options import Options
そして、webdriver.Chrome 付近で以下のように追記します。
options = Options()
options.headless = True
driver = webdriver.Chrome(options=options)
別のウィンドウに移動する
ボタンをクリックした際に、別のウィンドウへ切り替えたい場合は以下のように記述します。
driver.switch_to.window(driver.window_handles[1])
1の数字の部分を変えることで、どのウィンドウかを指定することができます。
フレームに移動する
以下の例のように記述すると、フレームに移動することができます。
例)
driver.switch_to.frame(driver.find_element(By.NAME,"sample"))
エラー処理
for文を使って、スクレイピングを実行している途中でエラーが起きることがよくあるので、以下のように記述するといいと思います。
try:
エラーが起きそうな処理
except:
continue