LLM in a flash: Efficient Large Language Model Inference with Limited Memoryという論文についてGPT-4を使ってまとめました。
要約
LLM in a flashは、限られたメモリを持つデバイス上で効率的に大規模言語モデル(LLM)の推論を実行するための手法です。この手法では、モデルのパラメータをフラッシュメモリに格納し、推論時に必要なパラメータをDRAMにオンデマンドで読み込むことで、DRAMの容量を超えるLLMを効率的に実行できるようにします(Hybrid手法)。具体的には、フラッシュメモリの動作に適合した推論コストモデルを構築し、フラッシュメモリからのデータ転送量を削減し、データの読み込みをより大きく連続したチャンクで行うことを最適化します。
このフレームワークの中で、2つの主要な技術が導入されています。
- ウィンドウ化:以前に活性化されたニューロンを再利用することでデータ転送量を削減
- 行列バンドル化:フラッシュメモリの連続データアクセスの強みを活かして、フラッシュメモリから読み込むデータチャンクのサイズを増やす。
これらの方法を組み合わせることで、利用可能なDRAMの2倍のサイズのモデルを実行できるようになり、CPUでの推論速度が4-5倍、GPUでの推論速度が20-25倍に向上します。
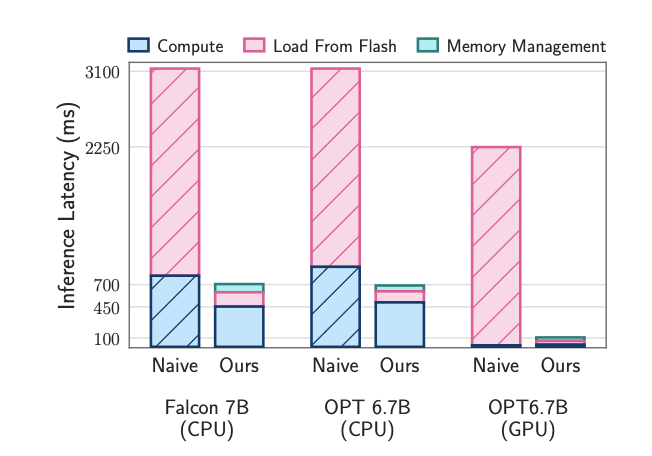
LLM in a flashは、スパース性認識、コンテキスト適応型ローディング、ハードウェア指向デザインを統合することで、限られたメモリを持つデバイス上での効果的なLLM推論を実現します。
ウィンドウ化(windowing)
ウィンドウ化は、大規模言語モデル(LLM)の推論を効率的に行うために、フラッシュメモリからDRAMへのデータ転送量を削減する方法です。
ウィンドウ化の主なアイデアは、以前にアクティブ化されたニューロンを再利用することで、フラッシュメモリからDRAMへのデータ転送量を削減することです。具体的には、LLMの推論時に、一度アクティブ化されたニューロンの値をウィンドウ内に保持し、次の推論ステップで再利用します。これにより、フラッシュメモリからのデータ読み込みが必要な部分が減り、全体の推論速度が向上します。
ウィンドウ化は、フラッシュメモリのシーケンシャルなアクセス特性を利用して、効率的にデータを読み込むことができるように設計されています。これにより、LLMの推論を限られたメモリ容量のデバイスで効果的に実行することが可能になります。
行列バンドル化(Bundling)
フラッシュメモリから効率的にデータを読み込むための方法です。フラッシュメモリは、連続したデータの読み込みが得意であるため、この手法が適用されます。
行列バンドル化は、大規模言語モデル(LLM)の推論時にフラッシュメモリから必要なパラメータを効率的に読み込むために、行と列の両方をバンドル化(束ねる)というアイデアに基づいています。これにより、フラッシュメモリからのデータ転送量を削減し、より大きな連続したチャンクでデータを読み込むことができます。
具体的には、行列バンドル化では、アクティブなニューロン(つまり、推論時に必要なニューロン)の行と列を同時にバンドル化します。これにより、フラッシュメモリからのデータ読み込みが効率化され、推論速度が向上します。
イメージとしては、行列のデータを小さなブロックに分割し、それらのブロックを連続したデータチャンクとしてフラッシュメモリに格納することを考えてください。推論時には、必要なパラメータが含まれるブロックだけを効率的にフラッシュメモリから読み込むことができます。
さらなる工夫:スパース性予測(Predictor)
LLM in a flashの論文では、スパース性予測という手法が提案されています。これは、大規模言語モデル(LLM)の推論時に、メモリ使用量と計算コストを削減するために、モデルのスパース性(つまり、多くのゼロ値を持つこと)を利用する方法です。
具体的には、LLMのFeedForward Network(FFN)層において、活性化されるニューロンが非常にスパースであることが観察されています。つまり、多くのニューロンがゼロ値を持ち、計算に寄与しないことがわかっています。このスパース性を利用することで、必要なパラメータだけを効率的にロードし、不要なデータの転送や計算を削減することができます。
スパース性予測では、モデルの各層で活性化されるニューロンのインデックスを予測し、そのインデックスに対応するパラメータだけをフラッシュメモリからDRAMにロードします。これにより、メモリ使用量が削減され、推論速度が向上します。
実験結果
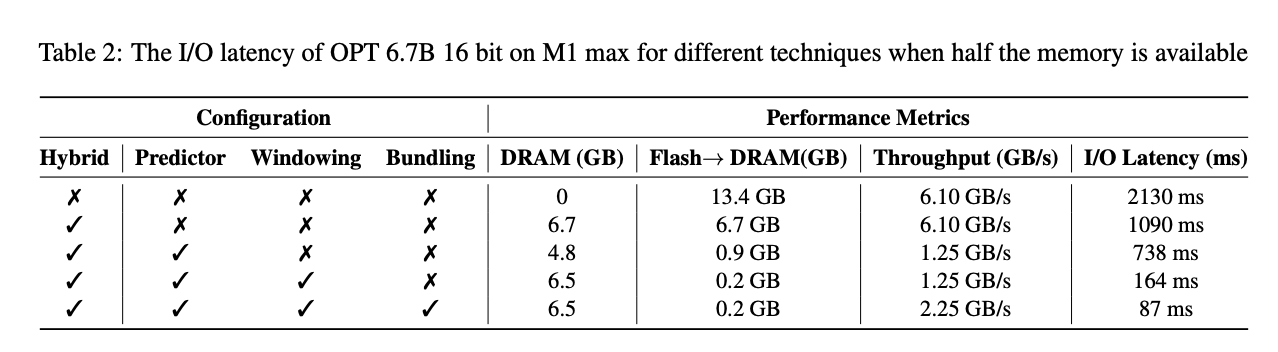
LLM in a flashの手法がOPT 6.7Bモデルに対してどのような効果があるかを評価しています。この実験では、DRAMの容量がモデルサイズの半分しか利用できない状況を想定しています。
実験結果は以下の通りです。
- Hybridを使用することで、フラッシュからDRAMへのデータ転送量が13.4GBから6.7GBに削減され、I/Oレイテンシが2130msから1090msに短縮されました。
- Predictorを適用することで、データ転送量がさらに0.9GBに削減され、I/Oレイテンシが738msに短縮されました。
- Windowingを適用することで、データ転送量が0.2GBに削減され、I/Oレイテンシが164msに短縮されました。
- Bundlingを適用することで、データ転送速度が1.25GB/sから2.25GB/sに向上し、I/Oレイテンシがさらに87msに短縮されました。
これらの結果から、LLM in a flashの手法がフラッシュメモリからのデータ転送量を大幅に削減し、I/Oレイテンシを短縮することが示されています。これにより、限られたメモリ容量のデバイスでも大規模な言語モデルを効率的に実行できるようになります。
展望
この論文では、限られたメモリを持つデバイス上で大規模言語モデル(LLM)を効率的に実行する方法について取り組んでいます。この研究の展望として、以下の点が挙げられます。
-
他の技術との組み合わせ: この論文で提案された方法は、他の技術と組み合わせることでさらなる改善が期待できます。例えば、推測デコーディングやMixture of Experts(MoE)などの技術と組み合わせることで、より大規模なモデルを効率的に実行できる可能性があります。
-
ハードウェア特性の考慮: この研究は、ハードウェア特性を考慮したアルゴリズム開発の重要性を示しています。今後の研究では、さらにハードウェアに適した最適化手法を開発することで、LLMの効率的な実行が可能になるでしょう。
-
LLMのサイズと複雑さの増加: LLMが今後もサイズや複雑さが増加することが予想されるため、この研究のようなアプローチが、幅広いデバイスやアプリケーションでLLMの潜在能力を引き出すために重要になるでしょう。
総じて、この論文は、限られたメモリを持つデバイスでのLLMの効率的な実行に向けた重要なステップを提供しており、今後の研究の方向性を示唆しています。