はじめに
はじめまして。リンクアンドモチベーションの石井です。
新卒1年目、現在データサイエンスの領域を担当しています。
弊社ではプロダクトやCRMなどのデータを蓄積して統合分析するデータ分析基盤をAWS上に構築しており、データの取得・加工・集計をAmazon Athenaで行っています。
私のSQLの経験は研修でPostgreSQLを3日間触ったことのある程度で、Athenaを触った経験もありませんでした。
SQLを練習したいと思っていたとき、データサイエンス100本ノック(構造化データ加工編)の存在を上司に教えていただきました。
PostogreSQL前提のノックでしたが、せっかくなのでAthenaで解いてみよう!となったのがことの発端です。
Athena版の回答が検索しても出てこなかったので、同じようにAthenaやPrestoで100本ノックを実施してみたい人の参考になれば幸いです。
この記事はなに?
PostgreSQL環境で作られた「データサイエンス100本ノック(構造化データ加工編)」をAthenaで解いてみたものです。
この記事では問題文、回答、私が解く際に調べた内容のメモを記載しています。
【AthenaでSQLを練習したい方】の参考になれば嬉しいです。
(また、新卒エンジニアのオンボーディングに悩んでいる方のお役にも立てれば幸いです)
データサイエンス100本ノックとは
そもそも公式で出されている「データサイエンス100本ノック」とは、データサイエンス初学者に向けて一般社団法人データサイエンティスト協会がGitHubに公開したものです。(以下リンクのREADMEにインストール手順が記載されています。)
データサイエンス100本ノック(構造化データ加工編)
学習の進め方について
- まず自分で解いてみる
- わからない問題はpostgreSQL版の回答を見て、presto版に翻訳
- それでも分からないものは先輩に質問する
環境
今回はAmazon Athenaで実行しました。(Treasure Data等、Presto互換のものであれば代替できそうです)
リポジトリからDB作成用のcsvファイルを抽出してS3に格納し、Glue Crawlerを用いてデータベース・テーブルを作成しました。
(データベース名:sql_knocks)
注意点
crawlerを使用した際に、一部カラムのデータ型がER図の通りのデータ型にならないため修正が必要です。
| テーブル名 | カラム名 | 修正前 | 修正後 |
|---|---|---|---|
| customer | birth_day | string | date |
| category、product | category_major_cd | bigint | string |
| category、product | category_medium_cd | bigint | string |
| category、product | category_small_cd | bigint | string |
| store | prefecture_cd | bigint | string |
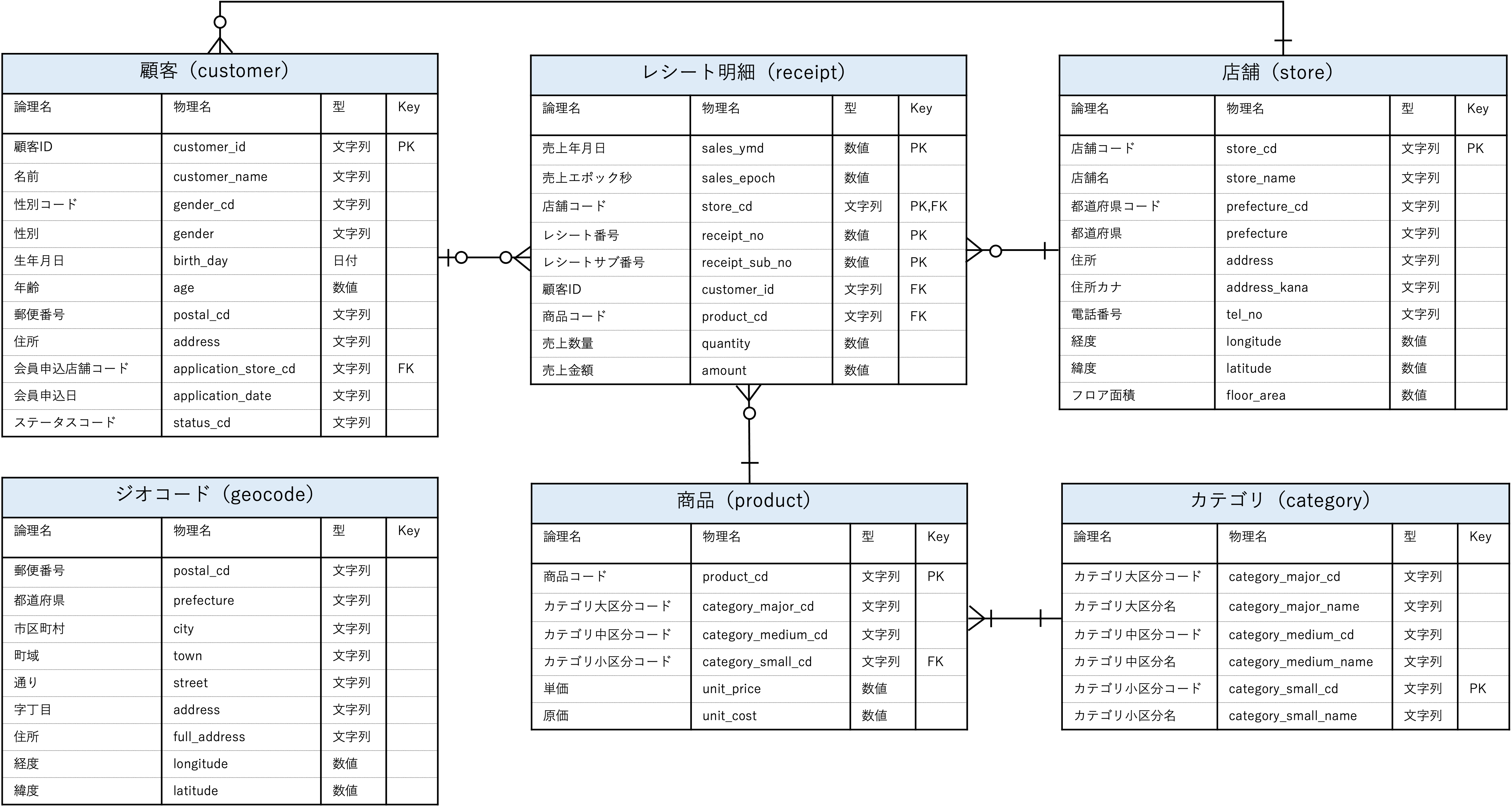
ER図
github内の100knocks-preprocessを参照。
問題と回答
※今回はテーブル操作やファイル入出力操作に関する設問は対象外とさせていただいております。
S-001〜S-010
S-001: レシート明細データ(receipt)から全項目の先頭10件を表示し、どのようなデータを保有しているか目視で確認せよ。
回答
SELECT
*
FROM "sql_knocks"."receipt"
LIMIT 10
;
メモ
- presto SQLでは、テーブル指定を”<データベース名>”.”<テーブル名>”で指定する。
- ダブルクオートであることに注意
- 囲まなくても処理は通るが、シングルクオートはX(値を意味するため)
- “ SELECT * ”は全カラム指定
- 先頭10件: LIMIT 10
S-002: レシート明細データ(receipt)から売上年月日(sales_ymd)、顧客ID(customer_id)、商品コード(product_cd)、売上金額(amount)の順に列を指定し、10件表示せよ。
回答
SELECT
sales_ymd
, customer_id
, product_cd
, amount
FROM "sql_knocks"."receipt"
LIMIT 10
;
メモ
- カラム指定はカンマ区切り
- 人それぞれだが、カンマは先頭につけるとコメントアウトしやすい
S-003: レシート明細データ(receipt)から売上年月日(sales_ymd)、顧客ID(customer_id)、商品コード(product_cd)、売上金額(amount)の順に列を指定し、10件表示せよ。ただし、sales_ymdをsales_dateに項目名を変更しながら抽出すること。
回答
SELECT
sales_ymd AS "sales_date"
, customer_id
, product_cd
, amount
FROM "sql_knocks"."receipt"
LIMIT 10
;
メモ
- カラムの別名は”AS”を利用
- ダブルクオートであることに注意(英字であれば付けなくても処理は通る)
- ASは省略可能
S-004: レシート明細データ(receipt)から売上日(sales_ymd)、顧客ID(customer_id)、商品コード(product_cd)、売上金額(amount)の順に列を指定し、以下の条件を満たすデータを抽出せよ。
回答
SELECT
sales_ymd
, customer_id
, product_cd
, amount
FROM
"sql_knocks"."receipt"
WHERE customer_id = 'CS018205000001'
;
メモ
- 条件によるレコードの絞り込みはWHERE句
- prestoでは、(テーブルやカラムでなく)”値”を表現する際にはシングルクオート括り
- ダブルクオートでは無いことに注意
- prestoでは、(テーブルやカラムでなく)”値”を表現する際にはシングルクオート括り
S-005: レシート明細データ(receipt)から売上日(sales_ymd)、顧客ID(customer_id)、商品コード(product_cd)、売上金額(amount)の順に列を指定し、以下の全ての条件を満たすデータを抽出せよ。
回答
SELECT
sales_ymd
, customer_id
, product_cd
, amount
FROM
"sql_knocks"."receipt"
WHERE customer_id = 'CS018205000001'
AND amount >= 1000
;
メモ
- WHERE句の複数条件はANDで結合(ORもある)
- 数値型のカラムの値はシングルクオート括りは不要
S-006: レシート明細データ(receipt)から売上日(sales_ymd)、顧客ID(customer_id)、商品コード(product_cd)、売上数量(quantity)、売上金額(amount)の順に列を指定し、以下の全ての条件を満たすデータを抽出せよ。
- 顧客ID(customer_id)が"CS018205000001"
- 売上金額(amount)が1,000以上または売上数量(quantity)が5以上
回答
SELECT
sales_ymd
, customer_id
, product_cd
, quantity
, amount
FROM
"sql_knocks"."receipt" receipt
WHERE
customer_id = 'CS018205000001'
AND
(
amount >= 1000
OR quantity >= 5
)
;
メモ
- AND と OR ではANDが先に評価される
- ANDよりもORを先に評価したい場合は、OR条件を括弧でくくる
- 上記を括弧でくくらないと、
customer_id = 'CS018205000001' AND amount >= 1000で先にフィルタされてしまう
- 上記を括弧でくくらないと、
S-007: レシート明細データ(receipt)から売上日(sales_ymd)、顧客ID(customer_id)、商品コード(product_cd)、売上金額(amount)の順に列を指定し、以下の全ての条件を満たすデータを抽出せよ。
- 顧客ID(customer_id)が"CS018205000001"
- 売上金額(amount)が1,000以上2,000以下
回答
SELECT
sales_ymd
, customer_id
, product_cd
, amount
FROM "sql_knocks"."receipt"
WHERE customer_id = 'CS018205000001'
AND amount BETWEEN 1000 AND 2000
;
メモ
- BETWEN A AND Bで「A ≤ 評価対象 ≤ B」と同じ処理
S-008: レシート明細データ(receipt)から売上日(sales_ymd)、顧客ID(customer_id)、商品コード(product_cd)、売上金額(amount)の順に列を指定し、以下の全ての条件を満たすデータを抽出せよ。
- 顧客ID(customer_id)が"CS018205000001"
- 商品コード(product_cd)が"P071401019"以外
回答
SELECT
sales_ymd
, customer_id
, quantity
, product_cd
, amount
FROM "sql_knocks"."receipt"
WHERE customer_id = 'CS018205000001'
AND product_cd != 'P071401019'
;
メモ
- 「以外」は ”!=”
S-009: 以下の処理において、出力結果を変えずにORをANDに書き換えよ。
SELECT * FROM store WHERE NOT (prefecture_cd = '13' OR floor_area > 900)
回答
SELECT
*
FROM "sql_knocks"."store"
WHERE prefecture_cd != 13
AND floor_area <= 900
;
メモ
- 問題文:(
prefecture_cdが13であるもしくはfloor_areaが900よりも大きい)の、どちらでもない - 回答:
prefecture_cdが13でない、かつ、floor_areaが900以下である
S-010: 店舗データ(store)から、店舗コード(store_cd)が"S14"で始まるものだけ全項目抽出し、10件表示せよ。
回答
SELECT *
FROM "sql_knocks"."store"
WHERE
"store_cd" LIKE 'S14%'
LIMIT 10
;
メモ
- LIKEは部分一致(⇄完全一致)でのマッチングを実現する
- %は”ワイルドカード”(全ての文字を許容)を意味する
- たとえばLIKE ‘S14%’は、「先頭3文字は’S14’で始まり、4文字目以降はどんなものでもマッチ」を意味する
- これを前方一致という
S-011〜S-020
S-011: 顧客データ(customer)から顧客ID(customer_id)の末尾が1のものだけ全項目抽出し、10件表示せよ。
回答
SELECT *
FROM "sql_knocks"."store"
WHERE "store_cd" LIKE '%1'
LIMIT 10
;
メモ
- LIKEは部分一致(⇄完全一致)でのマッチングを実現する
- 今回LIKEの後方一致版
S-012: 店舗データ(store)から、住所 (address) に"横浜市"が含まれるものだけ全項目表示せよ。
回答
SELECT *
FROM "sql_knocks"."store"
WHERE "address" LIKE '%横浜市%'
;
メモ
- LIKEは部分一致(⇄完全一致)でのマッチングを実現する
- 今回LIKEの部分一致版
S-013: 顧客データ(customer)から、ステータスコード(status_cd)の先頭がアルファベットのA〜Fで始まるデータを全項目抽出し、10件表示せよ。
回答
SELECT *
FROM "sql_knocks"."customer"
WHERE regexp_like(status_cd, '^[A-F]')
LIMIT 10
;
メモ
- regexp_likeは、正規表現による文字列のマッチング
- Athena(Presto)は、Java正規表現の構文に従う
- 本問題で利用した正規表現
- ^: 文字列の先頭(^の次に来るパターンは、先頭文字列に掛かる)
- ここでは先頭だけロックしており、末尾は任意(LIKE構文の末尾%と同じ)
- []: []内のいずれか1文字
- A-F: AからFまで(アルファベットや数字などの順番がある場合に利用)
- ^: 文字列の先頭(^の次に来るパターンは、先頭文字列に掛かる)
S-014: 顧客データ(customer)から、ステータスコード(status_cd)の末尾が数字の1〜9で終わるデータを全項目抽出し、10件表示せよ。
回答
SELECT *
FROM "sql_knocks"."customer"
WHERE regexp_like(status_cd, '[1-9]$')
LIMIT 10;
メモ
- S-013と同様
- 本問題で利用した正規表現
-
$: 文字列の末尾($の前に来るパターンは、末尾文字列に掛かる)
-
S-015: 顧客データ(customer)から、ステータスコード(status_cd)の先頭がアルファベットのA〜Fで始まり、末尾が数字の1〜9で終わるデータを全項目抽出し、10件表示せよ。
回答
SELECT *
FROM "sql_knocks"."customer"
WHERE regexp_like(status_cd, '^[A-F].*[1-9]$')
LIMIT 10
;
メモ
-
問題13と同様
-
本問題で利用した正規表現
-
.: 任意の1文字 -
*: 直前の文字を0回以上繰り返し
つまり.*は、LIKE構文の%と同じ
-
S-016: 店舗データ(store)から、電話番号(tel_no)が3桁-3桁-4桁のデータを全項目表示せよ。
回答
SELECT *
FROM "sql_knocks"."customer"
WHERE regexp_like(status_cd, '^[0-9]{3}-[0-9]{3}-[0-9]{4}$')
;
メモ
- S-013と同様
- 本問題で利用した正規表現
- {数字}: 直前の文字が<数字>回連続
-
[0-9]{3}は、0~9いずれかの文字が3文字連続する
-
- {数字}: 直前の文字が<数字>回連続
S-017: 顧客データ(customer)を生年月日(birth_day)で高齢順にソートし、先頭から全項目を10件表示せよ。
回答
SELECT *
FROM "sql_knocks"."customer"
ORDER BY birth_day
Limit 10
;
メモ
- ORDER BY <カラム> [ASC|DESC]: <カラム>の順に並び替え
- ASC(デフォルト): 昇順
- DESC: 降順
S-018: 顧客データ(customer)を生年月日(birth_day)で若い順にソートし、先頭から全項目を10件表示せよ。
回答
SELECT *
FROM "sql_knocks"."customer"
ORDER BY birth_day DESC
Limit 10
;
メモ
- S-013とS-017と同様
S-019: レシート明細データ(receipt)に対し、1件あたりの売上金額(amount)が高い順にランクを付与し、先頭から10件表示せよ。項目は顧客ID(customer_id)、売上金額(amount)、付与したランクを表示させること。なお、売上金額(amount)が等しい場合は同一順位を付与するものとする。
回答
SELECT
customer_id
, amount
, RANK() OVER(ORDER BY amount DESC)
AS ranking
FROM "sql_knocks"."receipt"
Limit 10
;
メモ
- RANK関数
- RANK()
- WINDOW関数の一種。WINDOW関数とは、集計を行いつつ、レコードをGROUPに集約せずに集計結果を各レコードに付与できる(つまりテーブルの形を変えずに集計できる)関数
- RANKは、レコードの並び順に応じて順位を1から付与する関数。
- OVER()を付与する事で、WINDOW関数のオプション(並び順や集計単位など)を操作する事が出来る
- RANK()
- RANKは、レコードの並び順に応じて順位を1から付与する関数。順位を扱う類似の関数として、DENSE_RANKとROW_NUMBERがある(それぞれ仕様が異なる)
S-020: レシート明細データ(receipt)に対し、1件あたりの売上金額(amount)が高い順にランクを付与し、先頭から10件表示せよ。項目は顧客ID(customer_id)、売上金額(amount)、付与したランクを表示させること。なお、売上金額(amount)が等しい場合でも別順位を付与すること。
回答
SELECT
customer_id
, amount
, ROW_NUMBER() OVER(ORDER BY amount DESC) "ranking"
FROM "sql_knocks"."receipt"
Limit 10
;
メモ
- ROW_NUMBER()
- WINDOW関数の一種
- 同率があっても同じ順位にはならず、順位をカウントする
※同率があった場合、実行によって順位が変わったりする(正確に順位を振りたい場合、同率が発生しないよう並び替えカラムを複数設けたりする)
S-021〜S-030
S-021: レシート明細データ(receipt)に対し、件数をカウントせよ。
回答
SELECT
count(*)
FROM "sql_knocks"."receipt"
;
メモ
- count()
- 集計関数の一種。集計関数とは、レコード全体の値を用いて集計を行い、集計結果を返す関数
- count()は、レコード数を集計する
S-022: レシート明細データ(receipt)の顧客ID(customer_id)に対し、ユニーク件数をカウントせよ。
回答
SELECT
count(DISTINCT customer_id)
FROM "sql_knocks"."receipt"
;
メモ
- S-021と同様
- ユニーク数(重複を排除したレコード件数)を求める場合は、
DISTINCTを引数として入力する
S-023: レシート明細データ(receipt)に対し、店舗コード(store_cd)ごとに売上金額(amount)と売上数量(quantity)を合計せよ。
回答
SELECT
store_cd
,sum(amount) "sum_amount"
,sum(quantity) "sum_quantity"
FROM "sql_knocks"."receipt"
GROUP BY store_cd
;
メモ
- sum()
- 集計関数の一種。
- sumは、数値型カラムの合計を集計する
- GROUP BY
- 集計関数の集計単位を示す
- GROUP BYで指定したカラムごとに集計が行われる
- 今回でいうとstore_cdごと
- GROUP BYで指定しないカラムを”集計せずに”SELECT対象に含てもいけない
S-024: レシート明細データ(receipt)に対し、顧客ID(customer_id)ごとに最も新しい売上年月日(sales_ymd)を求め、10件表示せよ。
回答
SELECT
customer_id
, max(sales_ymd) "newistday"
FROM "sql_knocks"."receipt"
GROUP BY customer_id
LIMIT 10
;
メモ
- max()
- 集計関数の一種。
- maxは、最大値を集計する
S-025: レシート明細データ(receipt)に対し、顧客ID(customer_id)ごとに最も古い売上年月日(sales_ymd)を求め、10件表示せよ。
回答
SELECT
customer_id
, min(sales_ymd) "oldestday"
FROM "sql_knocks"."receipt"
GROUP BY customer_id
LIMIT 10
;
メモ
- min()
- 集計関数の一種
- minは、最大値を集計する
S-026: レシート明細データ(receipt)に対し、顧客ID(customer_id)ごとに最も新しい売上年月日(sales_ymd)と古い売上年月日を求め、両者が異なるデータを10件表示せよ。
回答
SELECT
customer_id
, max(sales_ymd) "max"
, min(sales_ymd) "min"
FROM "sql_knocks"."receipt"
GROUP BY customer_id
HAVING
max(sales_ymd) != min(sales_ymd)
LIMIT 10
;
メモ
- HAVING
- 集計関数(maxやminなど)の結果を用いた絞り込みを行う
- WHEREは、「集計関数の結果」の絞り込みに対応しない
- HAVINGは「GROUP BYの後」に記述する
- 集計関数(maxやminなど)の結果を用いた絞り込みを行う
S-027: レシート明細データ(receipt)に対し、店舗コード(store_cd)ごとに売上金額(amount)の平均を計算し、降順でTOP5を表示せよ。
回答
SELECT
store_cd
, avg(amount) "ave"
FROM "sql_knocks"."receipt"
GROUP BY store_cd
ORDER BY ave DESC
LIMIT 5
;
メモ
- avg
- 集計関数の一種
- avgは、平均値を集計する
S-028: レシート明細データ(receipt)に対し、店舗コード(store_cd)ごとに売上金額(amount)の中央値を計算し、降順でTOP5を表示せよ。
回答
SELECT
store_cd
, APPROX_PERCENTILE(amount, 0.5) "med"
FROM "sql_knocks"."receipt"
GROUP BY store_cd
ORDER BY med DESC
LIMIT 5
;
メモ
- prestoにはMEDIAN(中央値を計算する)関数が無いので、
APPROX_PERCENTILE(0.5)を用いる-
APPROX_PERCENTILE- 集計関数の一種
- パーセンタイル(データを大きさ順でならべて100個に区切り、小さいほうからのどの位置にあるか)を示す
- (0.5)は中央値を示す
-
S-029: レシート明細データ(receipt)に対し、店舗コード(store_cd)ごとに商品コード(product_cd)の最頻値を求め、10件表示させよ。
回答
-- 店舗コードかつ商品コードごとの明細の出現数を算出
WITH product_cnt AS (
SELECT
store_cd
, product_cd
, COUNT(1) AS mode_cnt
FROM "sql_knocks"."receipt"
GROUP BY
store_cd,
product_cd
),
-- 店舗コードかつ商品コードごとの明細の出現数ランキングをrnkカラムに表示
product_mode AS (
SELECT
store_cd,
product_cd,
mode_cnt,
RANK() OVER(PARTITION BY store_cd ORDER BY mode_cnt DESC) AS rnk
FROM product_cnt
)
-- 出現数ランキング1位(つまり最頻値)を店舗コードかつ商品コードごとに表示
SELECT
store_cd,
product_cd,
mode_cnt
FROM product_mode
WHERE
rnk = 1
ORDER BY
store_cd,
product_cd
LIMIT 10
;
メモ
-
WITH
- サブクエリの結果にテーブル名を付けられる構文。
- WITH <テーブル名> AS (<サブクエリ>)
- コンマ区切りで複数定義が可能。2つめ以降はWITHを付けない
- テーブル名は、他のクエリのFROMとして利用できる
- サブクエリよりもに使い回しが出来る為、WITHを用いる方が良いとされているらしい
- サブクエリの結果にテーブル名を付けられる構文。
-
最頻値
- prestoにはMODE(最頻値を計算する)関数が無さそうなので、地道に計算
- →個数を計算して、最も多いものが最頻値(最もよく出現する≒最頻)
- COUNT(1)は、「1カラム目の個数」を意味する。1である必要は特にない
- prestoにはMODE(最頻値を計算する)関数が無さそうなので、地道に計算
-
RANK()
- S-019にも記載
S-030: レシート明細データ(receipt)に対し、店舗コード(store_cd)ごとに売上金額(amount)の分散を計算し、降順で5件表示せよ。
回答
SELECT
store_cd
,var_pop(amount) "var"
FROM "sql_knocks"."receipt"
GROUP BY store_cd
ORDER BY var DESC
LIMIT 5
;
メモ
- var_samp
- 集計関数の一種
- var_popは母分散を集計する。問題文は標本でなく全データを対象とする為、こちらを用いている。
- 類似の関数として、標本分散を集計するvar_sampがある
S-031〜S-040
S-031: レシート明細データ(receipt)に対し、店舗コード(store_cd)ごとに売上金額(amount)の標準偏差を計算し、降順で5件表示せよ。
回答
SELECT
store_cd
, stddev_pop(amount) "stds_amount"
FROM "sql_knocks"."receipt"
GROUP BY store_cd
ORDER BY stds_amount DESC
LIMIT 5
;
メモ
- stddev_pop
- 集計関数の一種
- stddev_popは母標準偏差を集計する。問題文は標本でなく全データを対象とする為、こちらを用いている。
- 類似の関数として、標本分散を集計するstddev_sampがある
S-032: レシート明細データ(receipt)の売上金額(amount)について、25%刻みでパーセンタイル値を求めよ。
回答
SELECT
APPROX_PERCENTILE(amount, 0.0) "pt0_min"
, APPROX_PERCENTILE(amount, 0.25) "pt25"
, APPROX_PERCENTILE(amount, 0.5) "pt50_median"
, APPROX_PERCENTILE(amount, 0.75) "pt75"
, APPROX_PERCENTILE(amount, 1.0) "pt100_max"
FROM "sql_knocks"."receipt"
LIMIT 10
;
メモ
- パーセンタイル(四分位)計算はAPPROX_PERCENTILEで行う
- 四分位数とは、データを小さい順に並べたときに、そのデータの数で4等分した区切り値(25%、50%、75%)を指す
S-033: レシート明細データ(receipt)に対し、店舗コード(store_cd)ごとに売上金額(amount)の平均を計算し、330以上のものを抽出せよ。
回答
SELECT
store_cd,
avg(amount) "avg_amount"
FROM "sql_knocks"."receipt"
GROUP BY store_cd
HAVING
avg(amount) >= 330
;
メモ
-
HAVING
- 集計関数(maxやminなど)の結果を用いた絞り込みを行う
- WHEREは、「集計関数の結果」の絞り込みに対応しない
- HAVINGは「GROUP BYの後」に記述する
- 集計関数(maxやminなど)の結果を用いた絞り込みを行う
-
avg
- 集計関数の一種
- avgは、平均値を集計する
S-034: レシート明細データ(receipt)に対し、顧客ID(customer_id)ごとに売上金額(amount)を合計して全顧客の平均を求めよ。ただし、顧客IDが"Z"から始まるものは非会員を表すため、除外して計算すること。
回答
WITH customer_amount AS (
SELECT
customer_id
, sum(amount) "sum_amount"
FROM "sql_knocks"."receipt"
WHERE
customer_id NOT LIKE 'Z%'
GROUP BY customer_id
)
SELECT
avg(sum_amount)
FROM customer_amount
;
メモ
- 集計値(合計)の集計(平均)を算出するにあたり、サブクエリで分割
- サブクエリはWITHが便利
S-035: レシート明細データ(receipt)に対し、顧客ID(customer_id)ごとに売上金額(amount)を合計して全顧客の平均を求め、平均以上に買い物をしている顧客を抽出し、10件表示せよ。ただし、顧客IDが"Z"から始まるものは非会員を表すため、除外して計算すること。
回答
WITH customer_amount AS (
SELECT
customer_id
, sum(amount) "sum_amount"
FROM "sql_knocks"."receipt"
WHERE
customer_id NOT LIKE 'Z%'
GROUP BY customer_id
)
SELECT
customer_id
, sum_amount
FROM customer_amount
WHERE
sum_amount >= (
SELECT
AVG(sum_amount)
FROM customer_amount
)
LIMIT 10
;
メモ
- 2段階に分けて考える
- 顧客毎の売上金額合計を算出
- 1で算出した合計金額に対して「全顧客の売上金額合計の平均以上である」で絞り込み
S-036: レシート明細データ(receipt)と店舗データ(store)を内部結合し、レシート明細データの全項目と店舗データの店舗名(store_name)を10件表示せよ。
回答
SELECT
r.*,
s.store_name
FROM "sql_knocks"."receipt" r
INNER JOIN "sql_knocks"."store" s
ON r.store_cd = s.store_cd
LIMIT 10
;
メモ
- 内部結合:INNER JOIN
- 左右どちらにも結合キー(ONで指定)の値が存在するレコードのみ取得
S-037: 商品データ(product)とカテゴリデータ(category)を内部結合し、商品データの全項目とカテゴリデータのカテゴリ小区分名(category_small_name)を10件表示せよ。
回答
SELECT
p.*,
c.category_small_name
FROM "sql_knocks"."product" p
INNER JOIN "sql_knocks"."category" c
ON p.category_small_cd = c.category_small_cd
LIMIT 10
;
メモ
- 特になし
S-038: 顧客データ(customer)とレシート明細データ(receipt)から、顧客ごとの売上金額合計を求め、10件表示せよ。ただし、売上実績がない顧客については売上金額を0として表示させること。また、顧客は性別コード(gender_cd)が女性(1)であるものを対象とし、非会員(顧客IDが"Z"から始まるもの)は除外すること。
回答
WITH customer_amount AS (
SELECT
customer_id
, sum(amount) "sum_amount"
FROM "sql_knocks"."receipt"
GROUP BY
customer_id
),
customer_data AS (
SELECT
customer_id
FROM "sql_knocks"."customer"
WHERE
gender_cd = '1'
AND customer_id NOT LIKE 'Z%'
)
SELECT
c.customer_id
, coalesce(a.sum_amount, 0)
FROM customer_data c
LEFT JOIN customer_amount a
ON
c.customer_id = a.customer_id
LIMIT 10
;
メモ
- 左外部結合:LEFT (OUTER) JOIN
- 左テーブルの結合キー値が右テーブルに存在しない場合、レコードは取得し、右テーブルの値をnullで返す
- 今回の場合、売り上げ実績のない顧客の売り上げレコードも取得対象としたい為、customerテーブルとの結合をINNER でなくLEFT JOINで行った
- coalesce
- 条件式の一種
- 第1引数のカラムに対して、nullの場合は第2引数の値を返却する
- 条件式の一種
S-039: レシート明細データ(receipt)から、売上日数の多い顧客の上位20件を抽出したデータと、売上金額合計の多い顧客の上位20件を抽出したデータをそれぞれ作成し、さらにその2つを完全外部結合せよ。ただし、非会員(顧客IDが"Z"から始まるもの)は除外すること。
回答
WITH customer_data AS (
select
customer_id
, sales_ymd
, amount
FROM "sql_knocks"."receipt"
WHERE customer_id NOT LIKE 'Z%'
),
customer_days AS (
select
customer_id
, count(distinct sales_ymd) "come_days"
FROM customer_data
GROUP BY customer_id
ORDER BY come_days DESC
LIMIT 20
),
customer_amount AS (
SELECT
customer_id
, sum(amount) "buy_amount"
FROM customer_data
GROUP BY customer_id
ORDER BY buy_amount DESC
LIMIT 20
)
SELECT
coalesce(d.customer_id, a.customer_id) customer_id
, d.come_days
, a.buy_amount
FROM customer_days d
FULL JOIN customer_amount a
ON d.customer_id = a.customer_id
;
メモ
-
WITH customer_data
-
FROM "sql_knocks"."receipt" WHERE customer_id NOT LIKE 'Z%'をcustomer_daysでもcustomer_amountでも利用する為、customer_dataとして別出ししている- これにより、処理が1回に縮減される
-
-
FULL JOIN:完全外部結合
- 左右どちらかのテーブルに結合キーがあるレコードを全て取得する
- 結合キーが無い側のデータはnullを返す
- 左右どちらかのテーブルに結合キーがあるレコードを全て取得する
S-040: 全ての店舗と全ての商品を組み合わせたデータを作成したい。店舗データ(store)と商品データ(product)を直積し、件数を計算せよ。
回答
SELECT
COUNT(1)
FROM "sql_knocks"."store"
CROSS JOIN "sql_knocks"."product"
;
メモ
- 直積:CROSS JOIN
- 左右のテーブルを総当たりで結合する
- 結果として左テーブル件数 × 右テーブル件数のレコードを返却する
S-041〜S-050
S-041: レシート明細データ(receipt)の売上金額(amount)を日付(sales_ymd)ごとに集計し、前回売上があった日からの売上金額増減を計算せよ。そして結果を10件表示せよ。
回答
WITH sales_amount_by_date AS (
SELECT
sales_ymd
, sum(amount) AS amount
FROM "sql_knocks"."receipt"
GROUP BY sales_ymd
),
sales_amount_by_date_with_lag as (
SELECT
sales_ymd
, lag(sales_ymd, 1) OVER(ORDER BY sales_ymd) "lag_ymd"
, amount
, lag(amount, 1) OVER(ORDER BY sales_ymd) "lag_amount"
FROM sales_amount_by_date
)
SELECT
sales_ymd
, amount
, lag_ymd
, lag_amount
, amount - lag_amount "diff_amount"
FROM sales_amount_by_date_with_lag
ORDER BY sales_ymd
LIMIT 10
;
メモ
- LAG関数
- 指定したカラム前の行のデータが得られる
- OVER(ORDER BY col)でどのカラムごとのデータを取得するか指定できる
- 似た関数にLEAD関数がある
- 指定したカラム後の行のデータが得られる
S-042: レシート明細データ(receipt)の売上金額(amount)を日付(sales_ymd)ごとに集計し、各日付のデータに対し、前回、前々回、3回前に売上があった日のデータを結合せよ。そして結果を10件表示せよ。
回答
-- コード例1:縦持ちケース
WITH sales_amount_by_date AS (
SELECT
sales_ymd
, sum(amount) "amount"
FROM "sql_knocks"."receipt"
GROUP BY sales_ymd
),
sales_amount_lag_date AS (
SELECT
sales_ymd
, lag(sales_ymd, 3) OVER (ORDER BY sales_ymd) "lag_date_3"
, amount
FROM sales_amount_by_date
)
SELECT
a.sales_ymd
, a.amount
, b.sales_ymd "lag_ymd"
, b.amount "lag_amount"
FROM sales_amount_lag_date a
JOIN sales_amount_lag_date b
ON (
a.lag_date_3 IS NULL
OR a.lag_date_3 <= b.sales_ymd
)
AND b.sales_ymd < a.sales_ymd
ORDER BY
sales_ymd
, lag_ymd
LIMIT 10
;
-- コード例2:横持ちケース
WITH sales_amount_by_date AS (
SELECT
sales_ymd
, sum(amount) AS amount
FROM "sql_knocks"."receipt"
GROUP BY sales_ymd
),
sales_amount_with_lag AS (
SELECT
sales_ymd
, amount
, lag(sales_ymd, 1) OVER (ORDER BY sales_ymd) AS lag_ymd_1
, lag(amount, 1) OVER (ORDER BY sales_ymd) AS lag_amount_1
, lag(sales_ymd, 2) OVER (ORDER BY sales_ymd) AS lag_ymd_2
, lag(amount, 2) OVER (ORDER BY sales_ymd) AS lag_amount_2
, lag(sales_ymd, 3) OVER (ORDER BY sales_ymd) AS lag_ymd_3
, lag(amount, 3) OVER (ORDER BY sales_ymd) AS lag_amount_3
FROM sales_amount_by_date
)
SELECT
sales_ymd
, amount
, lag_ymd_1
, lag_amount_1
, lag_ymd_2
, lag_amount_2
, lag_ymd_3
, lag_amount_3
FROM sales_amount_with_lag
WHERE lag_ymd_3 IS NOT NULL
ORDER BY sales_ymd
LIMIT 10
;
メモ
- S-041を参照
S-043: レシート明細データ(receipt)と顧客データ(customer)を結合し、性別コード(gender_cd)と年代(ageから計算)ごとに売上金額(amount)を合計した売上サマリデータを作成せよ。性別コードは0が男性、1が女性、9が不明を表すものとする。
ただし、項目構成は年代、女性の売上金額、男性の売上金額、性別不明の売上金額の4項目とすること(縦に年代、横に性別のクロス集計)。また、年代は10歳ごとの階級とすること。
※テーブル操作につき今回は取り扱わない
S-044: 043で作成した売上サマリデータ(sales_summary)は性別の売上を横持ちさせたものであった。このデータから性別を縦持ちさせ、年代、性別コード、売上金額の3項目に変換せよ。ただし、性別コードは男性を"00"、女性を"01"、不明を"99"とする。
※テーブル操作につき今回は取り扱わない
S-045: 顧客データ(customer)の生年月日(birth_day)は日付型でデータを保有している。これをYYYYMMDD形式の文字列に変換し、顧客ID(customer_id)とともに10件表示せよ。
回答
SELECT
customer_id
, date_format(birth_day, '%Y%m%d') "birth_day"
FROM "sql_knocks"."customer"
LIMIT 10
;
メモ
- date_format
- 日付関数の一種
- 引数に指定した日付を表す値を指定のフォーマットで整形した文字列を取得することができる
- prestoの時間識別子はmysqlと同じらしい
S-046: 顧客データ(customer)の申し込み日(application_date)はYYYYMMDD形式の文字列型でデータを保有している。これを日付型に変換し、顧客ID(customer_id)とともに10件表示せよ。
回答
SELECT
customer_id
, date(date_parse(application_date,'%Y%m%d')) "application_date"
FROM "sql_knocks"."customer"
LIMIT 10
;
メモ
- date
- 文字列をdate型に変換する
- date_parse
- 日付文字列をタイムスタンプ型日時に変換する。
- 日付文字列のフォーマットを第2引数に記述する。
S-047: レシート明細データ(receipt)の売上日(sales_ymd)はYYYYDD形式の数値型でデータを保有している。これを日付型に変換し、レシート番号(receipt_no)、レシートサブ番号(receipt_sub_no)とともに10件表示せよ。
回答
SELECT
receipt_no
, receipt_sub_no
, date(date_parse(CAST(sales_ymd AS VARCHAR), '%Y%m%d')) "sales_ymd"
FROM "sql_knocks"."receipt"
LIMIT 10
;
メモ
- CAST
- 引数で指定したデータ型に変換する
S-048: レシート明細データ(receipt)の売上エポック秒(sales_epoch)は数値型のUNIX秒でデータを保有している。これを日付型に変換し、レシート番号(receipt_no)、レシートサブ番号(receipt_sub_no)とともに10件表示せよ。
回答
SELECT
receipt_no
, receipt_sub_no
, date(from_unixtime(sales_epoch, 'Asia/Tokyo')) "sales_ymd"
FROM "sql_knocks"."receipt"
LIMIT 10
;
メモ
- UNIX時間
- UTC時刻における1970年1月1日午前0時0分0秒(UNIXエポック)からの経過秒数を計算したもの
-from_unixtimeとAsia/Tokyoはpostgreには無い関数なので注意する
- UTC時刻における1970年1月1日午前0時0分0秒(UNIXエポック)からの経過秒数を計算したもの
S-049: レシート明細データ(receipt)の売上エポック秒(sales_epoch)を日付型に変換し、「年」だけ取り出してレシート番号(receipt_no)、レシートサブ番号(receipt_sub_no)とともに10件表示せよ。
回答
SELECT
receipt_no
, receipt_sub_no
, date_format(from_unixtime(sales_epoch, 'Asia/Tokyo'), '%Y') AS sales_year
FROM "sql_knocks"."receipt"
LIMIT 10
;
メモ
- date_format
- 日付関数の一種
- 引数に指定した日付を表す値を指定のフォーマットで整形した文字列を取得することができる
- prestoの時間識別子はmysqlと同じらしい
S-050: レシート明細データ(receipt)の売上エポック秒(sales_epoch)を日付型に変換し、「月」だけ取り出してレシート番号(receipt_no)、レシートサブ番号(receipt_sub_no)とともに10件表示せよ。なお、「月」は0埋め2桁で取り出すこと。
回答
SELECT
receipt_no
, receipt_sub_no
, lpad(date_format(from_unixtime(sales_epoch, 'Asia/Tokyo'), '%m'), 2, '0') "sales_month"
FROM "sql_knocks"."receipt"
LIMIT 10
;
メモ
- lpad
- 指定した桁数になるまで文字列の左側に文字列を埋め込む。
S-051〜S-060
S-051: レシート明細データ(receipt)の売上エポック秒を日付型に変換し、「日」だけ取り出してレシート番号(receipt_no)、レシートサブ番号(receipt_sub_no)とともに10件表示せよ。なお、「日」は0埋め2桁で取り出すこと。
回答
SELECT
receipt_no
, receipt_sub_no
, lpad(date_format(from_unixtime(sales_epoch, 'Asia/Tokyo'), '%d'), 2, '0') "sales_day"
FROM "sql_knocks"."receipt" LIMIT 10
;
メモ
- 特になし
S-052: レシート明細データ(receipt)の売上金額(amount)を顧客ID(customer_id)ごとに合計の上、売上金額合計に対して2,000円以下を0、2,000円より大きい金額を1に二値化し、顧客ID、売上金額合計とともに10件表示せよ。ただし、顧客IDが"Z"から始まるのものは非会員を表すため、除外して計算すること。
回答
SELECT
customer_id
, SUM(amount) "sum_amount"
, CASE
WHEN SUM(amount) > 2000 THEN 1
ELSE 0
END AS sales_flg
FROM "sql_knocks"."receipt"
WHERE customer_id NOT LIKE 'Z%'
GROUP BY customer_id
LIMIT 10
;
メモ
- CASE
- 条件分岐
- WHEN:〜なら(条件を指定)
- THEN:〜とする
S-053: 顧客データ(customer)の郵便番号(postal_cd)に対し、東京(先頭3桁が100〜209のもの)を1、それ以外のものを0に二値化せよ。さらにレシート明細データ(receipt)と結合し、全期間において売上実績のある顧客数を、作成した二値ごとにカウントせよ。
回答
WITH cust AS (
SELECT
customer_id
, postal_cd
, CASE
WHEN CAST(SUBSTR(postal_cd, 1, 3) AS INTEGER) BETWEEN 100 AND 209 THEN 1
ELSE 0
END "postal_flg"
FROM
"sql_knocks"."customer"
),
rect AS(
SELECT DISTINCT
customer_id
FROM
"sql_knocks"."receipt"
)
SELECT
c.postal_flg
, COUNT(DISTINCT customer_id) "customer_cnt"
FROM cust c
INNER JOIN rect r
USING (customer_id)
GROUP BY c.postal_flg
メモ
- USING(本家の回答で使ってるので踏襲)
- 結合列を明示的に指定してSQL文をわかりやすくしたい場合に使用
- リファレンスの一つとして本家の回答を翻訳した
S-054: 顧客データ(customer)の住所(address)は、埼玉県、千葉県、東京都、神奈川県のいずれかとなっている。都道府県毎にコード値を作成し、顧客ID、住所とともに10件表示せよ。値は埼玉県を11、千葉県を12、東京都を13、神奈川県を14とすること。
回答
-- 正規表現を用いるケース
SELECT
customer_id
, address
, CASE regexp_extract(address, '^.*?[都道府県]')
WHEN '埼玉県' THEN '11'
WHEN '千葉県' THEN '12'
WHEN '東京都' THEN '13'
WHEN '神奈川県' THEN '14'
END "prefecture_cd"
FROM
"sql_knocks"."customer"
LIMIT 10
;
-- LIKE用いるケース
SELECT
customer_id,
address,
CASE
WHEN address LIKE '埼玉県%' THEN '11'
WHEN address LIKE '千葉県%' THEN '12'
WHEN address LIKE '東京都%' THEN '13'
WHEN address LIKE '神奈川県%' THEN '14'
END AS prefecture_cd
FROM
"sql_knocks"."customer"
LIMIT 10
;
メモ
- regexp_extract
- 正規表現関数
- 正規表現のパターンと一致する文字列の一部を返すことができる
S-055: レシート明細(receipt)データの売上金額(amount)を顧客ID(customer_id)ごとに合計し、その合計金額の四分位点を求めよ。その上で、顧客ごとの売上金額合計に対して以下の基準でカテゴリ値を作成し、顧客ID、売上金額合計とともに10件表示せよ。カテゴリ値は順に1〜4とする。
- 最小値以上第1四分位未満 ・・・ 1を付与
- 第1四分位以上第2四分位未満 ・・・ 2を付与
- 第2四分位以上第3四分位未満 ・・・ 3を付与
- 第3四分位以上 ・・・ 4を付与
回答
WITH sales_amount AS(
SELECT
customer_id
, SUM(amount) AS sum_amount
FROM
"sql_knocks"."receipt"
GROUP BY
customer_id
),
sales_pct AS (
SELECT
APPROX_PERCENTILE(sum_amount, 0.25) "pct25"
, APPROX_PERCENTILE(sum_amount, 0.50) "pct50"
, APPROX_PERCENTILE(sum_amount, 0.75) "pct75"
FROM
sales_amount
)
SELECT
a.customer_id
, a.sum_amount
, CASE
WHEN a.sum_amount < pct25 THEN 1
WHEN pct25 <= a.sum_amount AND a.sum_amount < pct50 THEN 2
WHEN pct50 <= a.sum_amount AND a.sum_amount < pct75 THEN 3
WHEN pct75 <= a.sum_amount THEN 4
END AS pct_group
FROM sales_amount a
CROSS JOIN sales_pct p
LIMIT 10
;
メモ
- パーセンタイル(四分位)計算はAPPROX_PERCENTILEで行う
- 四分位数とは、データを小さい順に並べたときに、そのデータの数で4等分した区切り値(25%、50%、75%)を指す
S-056: 顧客データ(customer)の年齢(age)をもとに10歳刻みで年代を算出し、顧客ID(customer_id)、生年月日(birth_day)とともに10件表示せよ。ただし、60歳以上は全て60歳代とすること。年代を表すカテゴリ名は任意とする。
回答
SELECT
customer_id
, birth_day
, age
, LEAST(age / 10 * 10, 60) "era"
FROM
"sql_knocks"."customer"
LIMIT 10
;
メモ
- prestoはint型同士の計算結果はint型になるので、その仕組みを利用
- 逆に少数にしたい場合は、* 1.0等で小数点型に暗黙的にCASTしてから計算する
- LEAST(A, B, [C, D, …])
- A, B, [C, D , …]の中で、もっと小さい値を表示
- 60より小さければそちらを、第一引数が60より大きければ60を返す
- A, B, [C, D , …]の中で、もっと小さい値を表示
S-057: 056の抽出結果と性別コード(gender_cd)により、新たに性別×年代の組み合わせを表すカテゴリデータを作成し、10件表示せよ。組み合わせを表すカテゴリの値は任意とする。
回答
-- 性別コード1桁と年代コード2桁を連結した性年代コードを生成する
SELECT
customer_id
, birth_day
, gender_cd || LPAD(CAST(LEAST(age / 10 * 10, 60) AS VARCHAR), 2, '0') "gender_era"
, age
FROM
"sql_knocks"."customer"
メモ
-
||- 連結関数
- 2つの文字列を連結させる
- concat関数でも文字列を連結させることができる
S-058: 顧客データ(customer)の性別コード(gender_cd)をダミー変数化し、顧客ID(customer_id)とともに10件表示せよ。
回答
-- カテゴリ数が多いときはとても長いSQLとなってしまう点に注意
-- カテゴリを一つ減らしたい場合はCASE文をどれか一つ削ればOK
SELECT
customer_id
, CASE WHEN gender_cd = '0' THEN '1' ELSE '0' END AS gender_cd_0
, CASE WHEN gender_cd = '1' THEN '1' ELSE '0' END AS gender_cd_1
, CASE WHEN gender_cd = '9' THEN '1' ELSE '0' END AS gender_cd_9
FROM
"sql_knocks"."customer"
LIMIT 10
;
メモ
- ダミー変数化の関数は見つからなかった。カスタム関数等で存在する可能性はある。
S-059: レシート明細データ(receipt)の売上金額(amount)を顧客ID(customer_id)ごとに合計し、売上金額合計を平均0、標準偏差1に"標準化して顧客ID、売上金額合計とともに10件表示せよ。標準化に使用する標準偏差は、分散の平方根、もしくは不偏分散の平方根のどちらでも良いものとする。ただし、顧客IDが"Z"から始まるのものは非会員を表すため、除外して計算すること。
回答
WITH sales_amount AS(
SELECT
customer_id
, SUM(amount) "sum_amount"
FROM "sql_knocks"."receipt"
WHERE customer_id NOT LIKE 'Z%'
GROUP BY customer_id
),
stats_amount AS (
SELECT
AVG(sum_amount) "avg_amount"
, STDDEV_POP(sum_amount) "stddev_amount"
FROM sales_amount
)
SELECT
customer_id
, sum_amount
, (sum_amount - avg_amount) / stddev_amount "std_amount"
FROM sales_amount
CROSS JOIN stats_amount
LIMIT 10
;
メモ
- 標準化
- 「平均を0,分散を1とするスケーリング手法」
-
(sum_amount - avg_amount) / stddev_amount←この部分
- stddev_pop
- 標準偏差を求める関数
S-060: レシート明細データ(receipt)の売上金額(amount)を顧客ID(customer_id)ごとに合計し、売上金額合計を最小値0、最大値1に正規化して顧客ID、売上金額合計とともに10件表示せよ。ただし、顧客IDが"Z"から始まるのものは非会員を表すため、除外して計算すること。
回答
WITH sales_amount AS(
SELECT
customer_id
, SUM(amount) "sum_amount"
FROM "sql_knocks"."receipt"
WHERE customer_id NOT LIKE 'Z%'
GROUP BY
customer_id
),
stats_amount AS (
SELECT
MAX(sum_amount) "max_amount"
, MIN(sum_amount) "min_amount"
FROM
sales_amount
)
SELECT
customer_id
, sum_amount
, 1.0 * (sum_amount - min_amount)
/ (max_amount - min_amount) "scale_amount"
FROM sales_amount
CROSS JOIN stats_amount
LIMIT 10
;
メモ
- 正規化
- 「最小値を0,最大値を1とする0-1スケーリング手法」
-
1.0 * (sum_amount - min_amount)/ (max_amount - min_amount)←この部分
S-061〜S-070
S-061: レシート明細データ(receipt)の売上金額(amount)を顧客ID(customer_id)ごとに合計し、売上金額合計を常用対数化(底10)して顧客ID、売上金額合計とともに10件表示せよ。ただし、顧客IDが"Z"から始まるのものは非会員を表すため、除外して計算すること。
回答
SELECT
customer_id
, sum_amount
, LOG10(sum_amount + 0.5) AS log_amount
FROM
(
SELECT
customer_id
, SUM(amount) AS sum_amount
FROM "sql_knocks"."receipt"
WHERE
customer_id NOT LIKE 'Z%'
GROUP BY
customer_id
) AS sum_amount_tbl
LIMIT 10
;
メモ
- prestoで常用対数を算出する関数はLOG10である
- 常用対数
- 10を底とする対数として定義されている。
S-062: レシート明細データ(receipt)の売上金額(amount)を顧客ID(customer_id)ごとに合計し、売上金額合計を自然対数化(底e)して顧客ID、売上金額合計とともに10件表示せよ。ただし、顧客IDが"Z"から始まるのものは非会員を表すため、除外して計算すること。
回答
WITH sum_amount_tbl AS (
SELECT
customer_id
, SUM(amount) AS sum_amount
FROM
"sql_knocks"."receipt"
WHERE
customer_id NOT LIKE 'Z%'
GROUP BY
customer_id
)
SELECT
customer_id
, sum_amount
, LN(sum_amount + 0.5) AS log_amount
FROM sum_amount_tbl
LIMIT 10
;
メモ
- prestoで常用対数を算出する関数はLNである
- 自然対数(LN)
- 超越数であるネイピア数 e (≈ 2.718281828459) を底とする対数を言う。
S-063: 商品データ(product)の単価(unit_price)と原価(unit_cost)から各商品の利益額を算出し、結果を10件表示せよ。
回答
SELECT
product_cd
, unit_price
, unit_cost
, unit_price - unit_cost "unit_profit"
FROM
"sql_knocks"."product"
LIMIT 10
;
メモ
利益額=単価ー原価
S-064: 商品データ(product)の単価(unit_price)と原価(unit_cost)から、各商品の利益率の全体平均を算出せよ。ただし、単価と原価には欠損が生じていることに注意せよ。
回答
SELECT
AVG((unit_price * 1.0 - unit_cost) / unit_price) "unit_profit_rate"
FROM
"sql_knocks"."product"
LIMIT 10
;
メモ
- Prestoは整数型 / 整数型 = 整数型となる
- なので、小数点型である1.0を事前に掛ける事で小数点型に暗黙的にcastする
S-065: 商品データ(product)の各商品について、利益率が30%となる新たな単価を求めよ。ただし、1円未満は切り捨てること。そして結果を10件表示させ、利益率がおよそ30%付近であることを確認せよ。ただし、単価(unit_price)と原価(unit_cost)には欠損が生じていることに注意せよ。
回答
WITH new_price_tbl AS (
SELECT
product_cd
, unit_price
, unit_cost
, CAST(FLOOR(unit_cost / 0.7)AS INTEGER) "new_price"
FROM
"sql_knocks"."product"
)
SELECT
*
, (1.0 * new_price - unit_cost) / new_price "new_profit_rate"
FROM
new_price_tbl
LIMIT 10
;
メモ
- FLOOR(col)
- 小数点以下の数値を最も近い整数に切り捨てて返す。
S-066: 商品データ(product)の各商品について、利益率が30%となる新たな単価を求めよ。今回は、1円未満を丸めること(四捨五入または偶数への丸めで良い)。そして結果を10件表示させ、利益率がおよそ30%付近であることを確認せよ。ただし、単価(unit_price)と原価(unit_cost)には欠損が生じていることに注意せよ。
回答
WITH new_price_tbl AS (
SELECT
product_cd
, unit_price
, unit_cost
, CAST(ROUND(unit_cost / 0.7) AS INTEGER) "new_price"
FROM
"sql_knocks"."product"
)
SELECT
*
, (1.0 * new_price - unit_cost) / new_price "new_profit_rate"
FROM
new_price_tbl
LIMIT 10
;
メモ
- ROUND
- 指定した桁数まで表示するように四捨五入する関数
S-067: 商品データ(product)の各商品について、利益率が30%となる新たな単価を求めよ。今回は、1円未満を切り上げること。そして結果を10件表示させ、利益率がおよそ30%付近であることを確認せよ。ただし、単価(unit_price)と原価(unit_cost)には欠損が生じていることに注意せよ。
回答
WITH new_price_tbl AS (
SELECT
product_cd
, unit_price
, unit_cost
, CAST(CEIL(unit_cost / 0.7) AS INTEGER) "new_price"
FROM
"sql_knocks"."product"
)
SELECT
*
, (1.0 * new_price - unit_cost) / new_price "new_profit_rate"
FROM
new_price_tbl
LIMIT 10
;
メモ
- CEIL
- 小数点以下の数値を最も近い整数に切り上げて返す。
S-068: 商品データ(product)の各商品について、消費税率10%の税込み金額を求めよ。1円未満の端数は切り捨てとし、結果を10件表示せよ。ただし、単価(unit_price)には欠損が生じていることに注意せよ。
回答
SELECT
product_cd
, unit_price
, CAST(FLOOR(unit_price * 1.1) AS INTEGER) "tax_price"
FROM
"sql_knocks"."product"
LIMIT 10
;
メモ
S-069: レシート明細データ(receipt)と商品データ(product)を結合し、顧客毎に全商品の売上金額合計と、カテゴリ大区分コード(category_major_cd)が"07"(瓶詰缶詰)の売上金額合計を計算の上、両者の比率を求めよ。抽出対象はカテゴリ大区分コード"07"(瓶詰缶詰)の売上実績がある顧客のみとし、結果を10件表示せよ。
回答
-- 顧客ごとの売り上げ合計
WITH amount_all AS(
SELECT
customer_id
, sum(amount) "sum_all"
FROM "sql_knocks"."receipt"
GROUP BY
customer_id
),
-- 顧客ごとの、category_major_cd='07'の商品の売り上げ合計
amount_category_07 AS (
SELECT
r.customer_id
, sum(r.amount) "sum_07"
FROM "sql_knocks"."receipt" r
INNER JOIN "sql_knocks"."product" p
ON r.product_cd = p.product_cd
WHERE p.category_major_cd = 07
GROUP BY
customer_id
)
-- 顧客ごとの、(全商品の)売り上げ合計とcategory_major_cd='07'の商品の売り上げ合計の比率
SELECT
a_all.customer_id
, a_all.sum_all
, a_07.sum_07
-- * 1.0は小数点化の為
, a_07.sum_07 * 1.0 / a_all.sum_all AS sales_rate
FROM amount_all a_all
JOIN amount_category_07 a_07
ON a_all.customer_id = a_07.customer_id
LIMIT 10;
メモ
- 「顧客ごとの売上合計」と「顧客ごとの”商品カテゴリ07”の売上合計」は集計対象の母数が変わるので、別々のサブクエリで集計する
- 一見、sum(条件)で絞り込めそうだが出来ない
- sum対象のカラムと絞り込み対象のカラムが異なる為
- 一見、sum(条件)で絞り込めそうだが出来ない
- Prestoは整数型 / 整数型 = 整数型となる
- なので、小数点型である1.0を事前に掛ける事で小数点型に暗黙的にcastする
S-070: レシート明細データ(receipt)の売上日(sales_ymd)に対し、顧客データ(customer)の会員申込日(application_date)からの経過日数を計算し、顧客ID(customer_id)、売上日、会員申込日とともに10件表示せよ(sales_ymdは数値、application_dateは文字列でデータを保持している点に注意)。
回答
WITH receipt_distinct AS (
SELECT DISTINCT
customer_id
, sales_ymd
FROM "sql_knocks"."receipt"
)
SELECT
c.customer_id
, r.sales_ymd
, c.application_date
, date_diff('day', date_parse(c.application_date, '%Y%m%d'), date_parse(CAST(r.sales_ymd AS VARCHAR), '%Y%m%d')) "elapsed_days"
FROM receipt_distinct r
INNER JOIN "sql_knocks"."customer" c
ON r.customer_id = c.customer_id
LIMIT 10
;
メモ
- date_diff
- 第一引数に
dayを指定することで2つの日付の間の日数を計算する。
- 第一引数に
S-071〜S-079
S-071: レシート明細データ(receipt)の売上日(sales_ymd)に対し、顧客データ(customer)の会員申込日(application_date)からの経過月数を計算し、顧客ID(customer_id)、売上日、会員申込日とともに10件表示せよ(sales_ymdは数値、application_dateは文字列でデータを保持している点に注意)。1ヶ月未満は切り捨てること。
回答
WITH receipt_distinct AS (
SELECT DISTINCT
customer_id
, sales_ymd
FROM "sql_knocks"."receipt"
)
SELECT
c.customer_id
, r.sales_ymd
, c.application_date
, date_diff('month'
, date_parse(c.application_date, '%Y%m%d')
, date_parse(CAST(r.sales_ymd AS VARCHAR), '%Y%m%d')
) AS elapsed_months
FROM receipt_distinct r
INNER JOIN "sql_knocks"."customer" c
ON r.customer_id = c.customer_id
LIMIT 10
;
メモ
- date_diff
- 第一引数に
monthを指定することで2つの日付の間の月数を計算する。
- 第一引数に
S-072: レシート明細データ(receipt)の売上日(sales_ymd)に対し、顧客データ(customer)の会員申込日(application_date)からの経過年数を計算し、顧客ID(customer_id)、売上日、会員申込日とともに10件表示せよ(sales_ymdは数値、application_dateは文字列でデータを保持している点に注意)。1年未満は切り捨てること。
回答
WITH receipt_distinct AS (
SELECT distinct
customer_id
, sales_ymd
FROM "sql_knocks"."receipt"
)
SELECT
c.customer_id
, r.sales_ymd
, c.application_date
, date_diff('year'
, date_parse(c.application_date, '%Y%m%d')
, date_parse(CAST(r.sales_ymd AS VARCHAR), '%Y%m%d')
) AS elapsed_years
FROM receipt_distinct r
JOIN "sql_knocks"."customer" c
ON r.customer_id = c.customer_id
LIMIT 10
;
メモ
-
- date_diff
- 第一引数に
yearを指定することで2つの日付の間の年数を計算する。
- 第一引数に
- date_diff
S-073: レシート明細データ(receipt)の売上日(sales_ymd)に対し、顧客データ(customer)の会員申込日(application_date)からのエポック秒による経過時間を計算し、顧客ID(customer_id)、売上日、会員申込日とともに10件表示せよ(なお、sales_ymdは数値、application_dateは文字列でデータを保持している点に注意)。なお、時間情報は保有していないため各日付は0時0分0秒を表すものとする。
回答
WITH receipt_distinct AS (
SELECT distinct
customer_id
, sales_ymd
FROM "sql_knocks"."receipt"
)
SELECT
c.customer_id
, r.sales_ymd
, c.application_date
, date_diff('second'
, date_parse(c.application_date, '%Y%m%d')
, date_parse(CAST(r.sales_ymd AS VARCHAR), '%Y%m%d')
) elapsed_second
FROM receipt_distinct r
INNER JOIN "sql_knocks"."customer" c
ON r.customer_id = c.customer_id
LIMIT 10
;
メモ
- date_diff
- 第一引数に
secondを指定することで2つの日付の間の秒数を計算する。
- 第一引数に
S-074: レシート明細データ(receipt)の売上日(sales_ymd)に対し、当該週の月曜日からの経過日数を計算し、売上日、直前の月曜日付とともに10件表示せよ(sales_ymdは数値でデータを保持している点に注意)。
回答
-- 当日日付
WITH sales_date AS (
select
date_parse(cast(sales_ymd as varchar), '%Y%m%d') "sales_date"
from
"sql_knocks"."receipt"
),
-- 曜日の数値と、月曜日からの経過日数を取得
day_of_week AS (
select
sales_date
, day_of_week(sales_date) "day_of_week"
-- 月曜日(day_of_week: 1)から何日経っているか
, day_of_week(sales_date) - 1 "days_from_monday"
from sales_date
)
-- 当日日付から「月曜日からの経過日数」を引き算する事で、直近月曜日の日付を算出
select
sales_date
, days_from_monday
, date_add('day', -1 * days_from_monday, sales_date) "last_monday"
from day_of_week
limit 10;
メモ
- day_of_week
- 月曜日は1、火曜日は2、水曜日は3….と返す
- date_add
- 第一引数に
dayを指定することで、第三引数に、第二引数の日数分足すことができる - postogreSQLに出てこないため注意する
- 第一引数に
S-075: 顧客データ(customer)からランダムに1%のデータを抽出し、先頭から10件表示せよ。
回答
SELECT *
FROM "sql_knocks"."customer"
TABLESAMPLE BERNOULLI(1)
LIMIT 10
;
-- コード例2(丁寧にやるなら。カウントを作って出力件数を固定)
WITH customer_tmp AS(
SELECT
*
, ROW_NUMBER() OVER(ORDER BY RANDOM()) "row"
, COUNT(*) OVER() AS cnt
FROM "sql_knocks"."customer"
)
SELECT
customer_id
, customer_name
, gender_cd
, gender
, birth_day
, age
, postal_cd
, address
, application_store_cd
, application_date
, status_cd
FROM customer_tmp
WHERE "row" <= cnt * 0.01
LIMIT 10
;
メモ
- TABLESAMPLE BERNOULLI()
- 抽出割合に若干の誤差は出る
- ROW_NUMBER()
- WINDOW関数の一種
- 同率があっても同じ順位にはならず、順位をカウントする
※同率があった場合、実行によって順位が変わったりする(正確に順位を振りたい場合、同率が発生しないよう並び替えカラムを複数設けたりする)
- RANDOM()
- データをランダムに抽出する
- 何も引数を入れない場合、0.0 <= x <1.0の範囲で疑似乱数を返す
S-076: 顧客データ(customer)から性別コード(gender_cd)の割合に基づきランダムに10%のデータを層化抽出し、性別コードごとに件数を集計せよ。
回答
WITH sample AS (
SELECT
gender_cd
, COUNT(1) AS cnt
, ARRAY_AGG(customer_id ORDER BY RANDOM()) AS customer_r
FROM "sql_knocks"."customer"
GROUP BY gender_cd
),
cusotmer_random AS (
SELECT
t.customer_id
, gender_cd
, cnt
FROM sample
CROSS JOIN UNNEST(customer_r) AS t(customer_id)
),
cusotmer_rownum AS(
SELECT
*
, ROW_NUMBER() OVER(PARTITION BY gender_cd) AS rn
FROM cusotmer_random
)
SELECT
gender_cd
, COUNT(1) AS customer_num
FROM cusotmer_rownum
WHERE rn <= cnt * 0.1
GROUP BY gender_cd
;
-- コード例2
WITH cusotmer_random AS (
SELECT
*
, ROW_NUMBER() OVER(PARTITION BY gender_cd ORDER BY RANDOM()) AS rn
, COUNT(1) OVER(PARTITION BY gender_cd) cnt
FROM "sql_knocks"."customer"
)
SELECT
gender_cd
, COUNT(1) AS customer_num
FROM cusotmer_random
WHERE rn <= cnt * 0.1
GROUP BY gender_cd
;
メモ
- ARRAY_AGG
- 指定した行を集約して配列にする
- CROSS JOIN UNNEST
- 配列として入っているデータを行に展開する
S-077: レシート明細データ(receipt)の売上金額を顧客単位に合計し、合計した売上金額の外れ値を抽出せよ。なお、外れ値は売上金額合計を対数化したうえで平均と標準偏差を計算し、その平均から3σを超えて離れたものとする(自然対数と常用対数のどちらでも可)。結果は10件表示せよ。
回答
WITH sales_amount AS(
SELECT
customer_id
, SUM(amount) AS sum_amount
, LN(SUM(amount) + 0.5) "log_sum_amount"
FROM "sql_knocks"."receipt"
GROUP BY customer_id
)
SELECT
customer_id
, sum_amount
, log_sum_amount
FROM sales_amount
CROSS JOIN (
SELECT
AVG(log_sum_amount) "avg_amount"
, STDDEV_POP(log_sum_amount) "std_amount"
FROM sales_amount
) stats_amount
WHERE
ABS(log_sum_amount - avg_amount) / std_amount > 3
LIMIT 10
;
メモ
- なぜ対数を使うのか
- 正しく外れ値を検出するため
S-078: レシート明細データ(receipt)の売上金額(amount)を顧客単位に合計し、合計した売上金額の外れ値を抽出せよ。ただし、顧客IDが"Z"から始まるのものは非会員を表すため、除外して計算すること。なお、ここでは外れ値を第1四分位と第3四分位の差であるIQRを用いて、「第1四分位数-1.5×IQR」を下回るもの、または「第3四分位数+1.5×IQR」を超えるものとする。結果は10件表示せよ。
回答
WITH sales_amount AS (
SELECT
customer_id
, SUM(amount) "sum_amount"
FROM "sql_knocks"."receipt"
WHERE customer_id NOT LIKE 'Z%'
GROUP BY customer_id
)
SELECT
customer_id
, sum_amount
FROM sales_amount
CROSS JOIN (
SELECT
APPROX_PERCENTILE(sum_amount, 0.25) AS amount_25per
, APPROX_PERCENTILE(sum_amount, 0.75) AS amount_75per
FROM sales_amount
) stats_amount
WHERE
sum_amount < amount_25per - (amount_75per - amount_25per) * 1.5
OR amount_75per + (amount_75per - amount_25per) * 1.5 < sum_amount
LIMIT 10
;
メモ
- 特になし
S-079: 商品データ(product)の各項目に対し、欠損数を確認せよ。
回答
SELECT
SUM(IF(product_cd IS NULL, 1, 0)) "product_cd"
, SUM(IF(category_major_cd IS NULL, 1, 0)) "category_major_cd"
, SUM(IF(category_medium_cd IS NULL, 1, 0)) "category_medium_cd"
, SUM(IF(category_small_cd IS NULL, 1, 0)) "category_small_cd"
, SUM(IF(unit_price IS NULL, 1, 0)) "unit_price"
, SUM(IF(unit_cost IS NULL, 1, 0)) "unit_cost"
FROM "sql_knocks"."product"
;
メモ
- IF
- IF(col1 = value1,true_result,false_result)
- 第一引数の条件を満たすとき、第二引数とする。満たさないとき、第三引数とする。
- 2択なのでcaseだと冗長
- coalesceは、そもそもの値が1だった時に誤集計するので避けた
*80-100 テーブル操作につき対象外
さいごに
100本ノックやってみての課題
処理の意味が分からないままpostgreSQL版や先輩の回答をそのまま採用してしまったところがありました。
1回で満足せず、何度も繰り返し説き、その中で、不明点をなくしていくことが大事だなと感じています。
回答やメモの中で、ここはおかしい、こっちのほうがいい、こうしたほうがいいなどアドバイスありましたら、いただけると幸いです!
今後もアップデートしながら運用を続けていこうと思います。
最後までお読みいただきありがとうございました!