※2022/4/1更新
MNISTを使って実際に学習をさせてみましょう.
この記事はとりあえず動かしてみたい人向けの記事です.
本格的にやってみたい方は
ゼロから作るDeep Learning ―Pythonで学ぶディープラーニングの理論と実装 オライリージャパン 2016/9/24
などをやってみることをオススメします.
それでは,今回は「0~9が書かれた画像を入力すると,その番号を予測する」というネットワークを作ります.
学習とテストに使用するデータは,MNISTの0~9の書かれた画像です.
各自の環境で実行するか,もしくは以下のURLのGoogle Colaboratoryのファイルを使ってください.
https://colab.research.google.com/drive/1zVgFq87w1OOU_txP558A-h_kSFz2KTsd
実装
ライブラリをインポートする
import numpy as np
import keras
from keras.datasets import mnist
from keras.models import Sequential
GPUが使えるかを確認する
# device_typeにGPU指定されてるか確認,実行して device_type: "GPU"みたいなのが出力されてたらGPU使えてる(使えなくても大丈夫です)
from tensorflow.python.client import device_lib
device_lib.list_local_devices()
学習パラメータを設定する.
バッチサイズを128,
分類クラス数を10クラス(0~9),
学習のエポック数を20に設定する
# 学習パラメータ
batch_size = 128
classes = 10
epochs = 20
MNISTの画像データを読み込む
# 数値が書かれた画像データの読み込み
# x_ が訓練データ,y_ がテストデータ
(x_train, y_train), (x_test, y_test) = mnist.load_data()
画像を表示して確認する
# 入力する画像の一つ目を表示する
import matplotlib.pyplot as plt
plt.imshow(x_train[0])
一般的に学習に使用する画像は0~255を0~1.0に正規化する.
そのためにint型からfloat型へ変換する.
# 元がint型だからfloat型に変換する
x_train = x_train.astype('float32')
x_test = x_test.astype('float32')
# 学習のために0~255 から 0~1 に変換(正規化)
x_train = x_train / 255
x_test = x_test / 255
今回は分類問題であるため,one-hot表現にする.
# kerasの関数を使って数値表現をone-hot表現に変える
# one hotとは,たとえば数値が0~9の範囲をとる場合に,5を [0 0 0 0 0 1 0 0 0 0]の表現にすること
from keras.utils import np_utils
y_train_one_hot = np_utils.to_categorical(y_train)
y_test_one_hot = np_utils.to_categorical(y_test)
入力として使える形にするために,2次元の画像を1次元に変換する.
# 画像を1次元にする
x_train = x_train.reshape(60000, 784)
x_test = x_test.reshape(10000, 784)
ネットワークはCNNではなく全て全結合層で構成します.
活性化関数は中間層ではrelu,出力層では多クラス分類なのでsoftmaxを用います.
元の画像サイズが28×28であるため,学習できるように784×1に変換して使います.
使用する損失関数,最適化手法,評価関数は以下の通り.
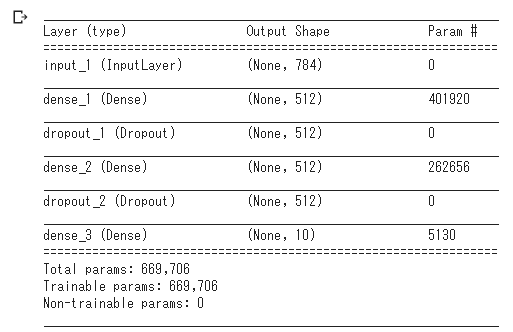
# ネットワークを構築する
from keras.layers import Input, Dense, Dropout
from keras.models import Model
#from keras.optimizers import Adam
from tensorflow.keras.optimizers import Adam
from tensorflow.keras.optimizers import RMSprop
#from keras.optimizers import RMSprop
input_shape = 28 * 28
model = Sequential()
input_array = Input(shape=(input_shape,))
x = Dense(units=512, activation='relu')(input_array)
x = Dropout(0.2)(x)
x = Dense(units=512, activation='relu')(x)
x = Dropout(0.2)(x)
x = Dense(units=classes, activation='softmax')(x) # 多クラス分類
# 引数:入力の変数名, モデル
model = Model(input_array, x)
# ネットワーク構成の表示
model.summary()
# コンパイル(しないとダメ)
# 損失関数:クロスエントロピー
# 最適化手法:RMSprop
# 評価関数:一般的にaccuracyが使われる
model.compile(loss='categorical_crossentropy',
optimizer=RMSprop(),
metrics=['accuracy'])
似たり寄ったりなデータが固まっていると学習に悪い影響を与えてしまうので,その場合はデータのシャッフルをしないといけません.
# データをシャッフルする
data_qty = len(x_train)
shuffled_num = np.arange(data_qty)
np.random.shuffle(shuffled_num)
for i in range(data_qty):
x_train[shuffled_num[i]], x_train[i] = x_train[i], x_train[shuffled_num[i]]
y_train_one_hot[shuffled_num[i]], y_train_one_hot[i] = y_train_one_hot[i], y_train_one_hot[shuffled_num[i]]
model.fitで学習が始まる.
history = model.fit(x_train, y_train_one_hot, # 画像とラベルデータ
batch_size=batch_size, # バッチサイズ
epochs=epochs, # エポック数
validation_split=0.2) # 学習に使うデータセットの中から2割を検証データに

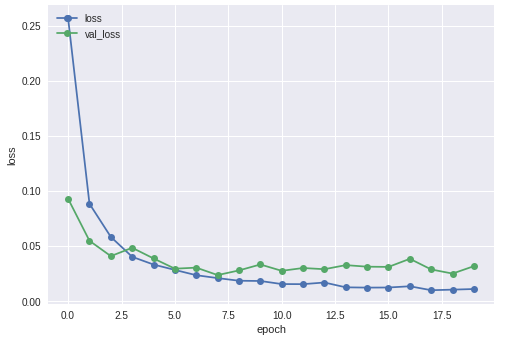
lossを表示する
# historyの表示(loss)
plt.plot(history.history['loss'],"o-",label="loss",)
plt.plot(history.history['val_loss'],"o-",label="val_loss")
plt.title('model loss')
plt.xlabel('epoch')
plt.ylabel('loss')
plt.legend(loc='upper left')
plt.show()
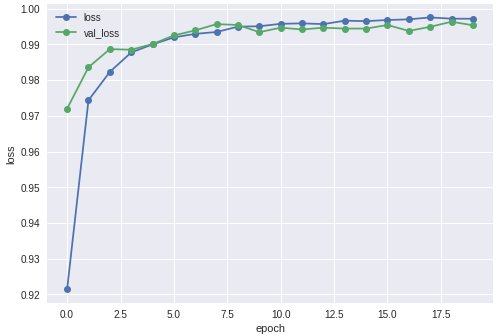
accuracyを表示する
# historyの表示(accuracy)
plt.plot(history.history['accuracy'],"o-",label="accuracy",)
plt.plot(history.history['val_accuracy'],"o-",label="val_accuracy")
plt.title('model accuracy')
plt.xlabel('epoch')
plt.ylabel('accuracy')
plt.legend(loc='upper left')
plt.show()
学習したネットワークを使って,1枚の画像に書かれた数値を予測する.
# 次元を増やして(784)を(1, 784)にする
x_test_image = x_test[0]
x_test_image = x_test_image[np.newaxis, :]
# 予測を行う
predicted = model.predict(x_test_image)
# 入力した画像と,その予測結果を表示する.
plt.imshow(x_test[0].reshape(28, 28)) # 元が1×784なので表示用に28×28にリサイズする
print("Anser -> ", np.argmax(predicted)) # 最も確率の高い答えを出力する
未知の画像に対する全体的な正解率を確認する.
# モデルを評価する
scores = model.evaluate(x_test, y_test_one_hot, verbose=0)
print("正解率: %.2f%%" % (scores[1] * 100))
