※一部生成AIを使用して記事を作成しているため、必ずしも情報が正しい保証はできかねます。ご了承ください。間違っている点ございましたら、コメントお願いします!
はじめに
最近Microsoft FabricのSQLDBがリリースされ、上司や先輩方が盛り上がっていました。
でも、入社したときにはすでにレイクハウスが当たり前の存在だった “レイクハウスネイティブ世代” の私にとっては、正直ピンとこなくて…。
「SQLデータベースって昔の技術じゃないの? 今はレイクハウスが主流なんだから、それだけあればよくない?」
なんて思っていたんですが、話はどうやらそんなに単純じゃないようで。
実際にいろいろと調べてみたところ、私の考えは間違いでした。
レイクハウス時代でも従来型のSQLデータベースが活躍する場面があります。
ようやくそれぞれの違いや役割が見えてきたので、この記事にまとめてみました。
結論:それぞれの特徴まとめ
| 領域 | 主な用途 | 特徴 | 得意な処理 |
|---|---|---|---|
| SQLDB | OLTP(業務処理・状態管理) | 行ストア、ACID対応、トランザクション処理可 | 登録、更新、状態管理 |
| Warehouse | OLAP(分析) | 列ストア、高速集計、構造化前提 | 大量集計、JOIN、BI向けSQL分析 |
| Lakehouse | データレイク+分析 | Parquetファイル保存、スキーマあり、柔軟 | 半構造化データ、ML、柔軟な保存 |
| KQL(Eventhouse) | リアルタイム分析 | イベント駆動、KQLクエリ、時系列に強い | ログ、IoT、直近の傾向検知 |
Chapter1:SQLDB、ウェアハウス、KQL、レイクハウスが生まれた順番
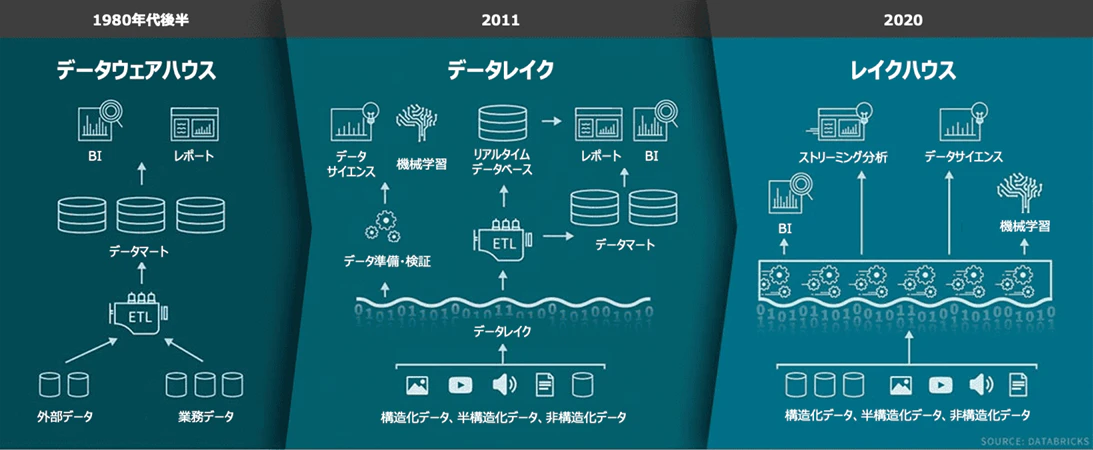
SQL Database(SQLDB)
➡️ 1970年代~1980年代
リレーショナルデータベース(RDBMS)の概念は1970年にIBMのエドガー・F・コッドが提唱し、1980年代にはOracleやSQL Serverなどが登場しました。
Data Warehouse(ウェアハウス)
➡️ 1990年代~2000年代に商用化が進む
構造化データを分析するためにデータを集約・最適化するアーキテクチャ。
初期にはTeradataやSnowflakeなど、クラウド時代にはRedshift、BigQuery、Synapseなどがあります。
※概念としてはSQLより後だけど、KQLよりは前に登場したと言えます。
Kusto Query Language(KQL)
➡️ 2016年ごろ(MicrosoftのAzure Data Explorerとともに登場)
ログ分析向けに特化したクエリ言語で、SQLとは異なる文法を持ちます。
Azure MonitorやLog Analyticsなどで使われています。
Lakehouse(レイクハウス)
➡️ 2019年ごろ(Databricksによる提唱)
Lakehouseは、データレイクの柔軟性とデータウェアハウスの性能・一貫性を両立させることを目的に登場した新しいアーキテクチャです。
その実現を支えているのが、Delta LakeやApache Icebergといったオープンテーブルフォーマットです。これらの技術により、データレイク上でもスキーマ管理やACIDトランザクションが可能になり、分析・AI開発にも耐えうるプラットフォームが構築できるようになりました。
4つの中では最も新しい概念です。
Chapter2:なぜSQLDBだけでは完結しないのか?
SQLDBは一見万能に見えます。
複数テーブルも持てるし、T-SQLでクエリも書ける。
でも、OLTPとOLAPでは最適化の方向が真逆なんです。
- SQLDBは"1件など少数のデータを即時に読み書き"に最適化(= OLTP)
- WarehouseやLakehouseは"大量の履歴を一括集計"に最適化(= OLAP)
たとえば、行ストア vs 列ストアの違いがパフォーマンスに大きく影響します。
さらに、SQLDBは更新処理やトランザクション処理を重視しており、これをPB級のデータでやろうとするとコストも非効率になってしまいます。
よって、SQLDBは業務アプリのトランザクションデータをリアルタイムに処理する用途に適しており、
大量データの分析にはデータウェアハウスが適します。
Chapter3:レイクハウスとウェアハウス、何が違う?
| 比較軸 | Lakehouse | Warehouse |
|---|---|---|
| 保存形式 | Parquetファイル | 列ストアDB |
| 更新処理 | 一部制限あり | 完全対応(DML可) |
| 柔軟性 | 高い(非構造化も可) | 構造化前提 |
| 分析性能 | 中〜高 | 高(高速クエリ、BI向け) |
| 運用コスト | 低め | 高め(そのぶん高性能) |
Lakehouseは柔軟性・コスト重視、Warehouseは構造化・パフォーマンス重視。
どちらが優れているというより、用途に応じての使い分けが重要です。
またデータブリックス社は以下のように述べています。
データレイクハウスはデータウェアハウスと異なり、データサイエンス、機械学習、リアルタイムストリーミングのネイティブなサポートを提供します。また、SQL や BI にもネイティブに対応しています。私たちが目指したのは、データレイクハウスがクラス最高の価格性能を実現できない、という神話を覆すことでした。
~省略~
古典的なデータウェアハウスのワークロード(TPC-DS)においても、データレイクハウスのパラダイムが、データウェアハウスよりも優れた価格性能を実現したことを嬉しく思います。
つまり、レイクハウスがウェアハウスに置き換わってきている。
レイクハウスの方がいい!ってのがDatabricks社の主張とも捉えられますね。
といいつつも
リアルタイム集計や厳密な性能が求められる定型レポートでは、従来型DWHが依然優位なケースもあると思います。
非構造化も格納できるレイクハウスだからこそ、AI開発ができる
AI開発においては、構造化データ(表形式)だけでなく、非構造化データ(画像、音声、自然言語テキスト、センサーデータなど)を扱うケースが非常に増えています。
たとえば以下のようなユースケースです。
- 商品レビューやSNSのテキストを使った自然言語処理(NLP)
- 医療画像や監視カメラ映像の画像解析
- 売上や天候データをもとにした需要予測・時系列分析
AI/機械学習ではテキストや画像などの非構造化データを扱うケースが多く、レイクハウスならこれら多様なデータを一元的に活用できます。
Databricksでは、Delta Lakeをベースに、構造化・半構造化・非構造化を問わずデータを取り込んで、MLflowやSpark MLlibなどと組み合わせて機械学習パイプラインを構築できます。
Fabricでも同様に、OneLakeを通じてLakehouseに保存されたファイルから、Power BIやPythonノートブック、さらにはAzure Machine Learningとの連携も視野に入れたAI開発が可能です。
一方で、従来型のWarehouse(例:Snowflakeなど)は構造化データの高速分析に特化しており、非構造化データへの対応やMLとの連携は限定的です。
もちろん、Snowflakeも近年では「Snowpark」などを通じてML対応を進めていますが、根本的な思想は"構造化データ向け"です。
つまり、
「AI開発を行いたい」と思ったとき、最初から柔軟性と統合性を兼ね備えたLakehouseアーキテクチャを選ぶ方が自然で合理的だと言えるでしょう。
Databricksのような"AIネイティブ"な設計思想を持つLakehouseや、Microsoft Fabricのように複数エンジンと連携できるLakehouse環境をうまく使うことで、AI開発はより身近で現実的なものになります。
▽Fabric,Databricks,Snowflakeの違いについてもまとめています。
Chapter4:KQL(Eventhouse)はなぜリアルタイム最強?
KQL(Kusto Query Language)は、Fabricのリアルタイム分析機能の核。
主にEventhouseやReal-Time Intelligenceで使われます。
- イベントログやIoTデータを秒単位で可視化可能
- 書き込み後すぐにクエリできる
- スキーマはあるが柔軟(dynamic型など)
- UPDATE/DELETEはできず、追記専用
つまりKQLは "いま起きていることを知るための分析基盤" であり、
過去の履歴を管理したり、状態を更新したりするのには向いていません。
長期データはどこに保存する?
KQLは高性能なリアルタイム分析エンジンですが、保持期間には限界があります(通常数日〜数ヶ月)。
そこで登場するのが LakehouseやWarehouse。
- KQLで直近のデータを分析 → 定期的にLakehouseにアーカイブ
- そこからPower BIでレポート、MLで予測分析
という使い分けが現実的かつ最適です。
私の素朴な疑問:「全部入り最強DBを作ればよくないですか?」
ここまで勉強してきて、以下のような疑問が私の中で生まれました。
"SQLDBのようにトランザクションできて、KQLみたいにリアルタイムで、Warehouseみたいに分析特化"なDBを作れば最強じゃない?
でも、ChatGPTと議論して見えてきた現実はこうでした。
「全部入り万能DB」が存在しない理由
でも現実には:
- 💸 すべての機能をフルで持つとコストが高すぎる
- ⚙️ 処理系の最適化がバッティングする(トランザクション vs バルク集計)
- 🧑💻 UI/UXが複雑化し、非エンジニアには扱いづらくなる
つまり「全部入りにしたら理論上は便利だけど、実用性・コスト・使いやすさが崩壊する」ということ。
だからこそ、Fabricではあえて 役割を分離 して、
「必要な処理に最適なエンジンを選ぶ」アーキテクチャが採用されています。
まとめ:適材適所の活用を
| 使いたい処理 | 最適なエンジン |
|---|---|
| 状態管理・更新・業務処理 | SQLDB |
| 構造化データの分析・BI | Warehouse |
| 柔軟な保存・ML・半構造化 | Lakehouse |
| ログ・イベント・リアルタイム分析 | KQL(Eventhouse) |
「全部KQL!」「SQLDBで全部やりたい!」という気持ちはめちゃくちゃ分かります。
でもコスト・性能・使い勝手を考えれば、分かれていた方が合理的なんです。
Microsoft Fabricはその合理性の上で、「すべての基盤をひとつのUIで扱える」という世界観を目指しています。
みなさんのプロジェクトでも、“いま必要な処理”と“今後の運用”を見据えて、最適な選択” をしてみてください!
Youtubeもやっているので見ていただけると嬉しいです!
FabricやDatabricksについて学べる勉強会を毎月開催しています!
次回イベント欄から直近のMicrosoft Data Analytics Day(Online) 勉強会ページ移動後、申し込み可能です!