※コードなど詳細についてはgithubにまとめました。ご覧ください。
はじめに
以下の記事で
TPC-DS scale factor = 1000(1TB)のデータセットを用意する( DBFS上のInitスクリプトの有効期間終了ver)方法をまとめました。
しかし、今後これらのデータセットを活用するうえで、
パーティションなし・1Parquetファイルあたりのサイズを調整する必要がでてきました。
今回はそれらについてまとめていきます。
①partitionTables = trueにしたときの問題点
各テーブルフォルダ(画像の場合 catalog_returns)の直下にさらにフォルダが作成されている。
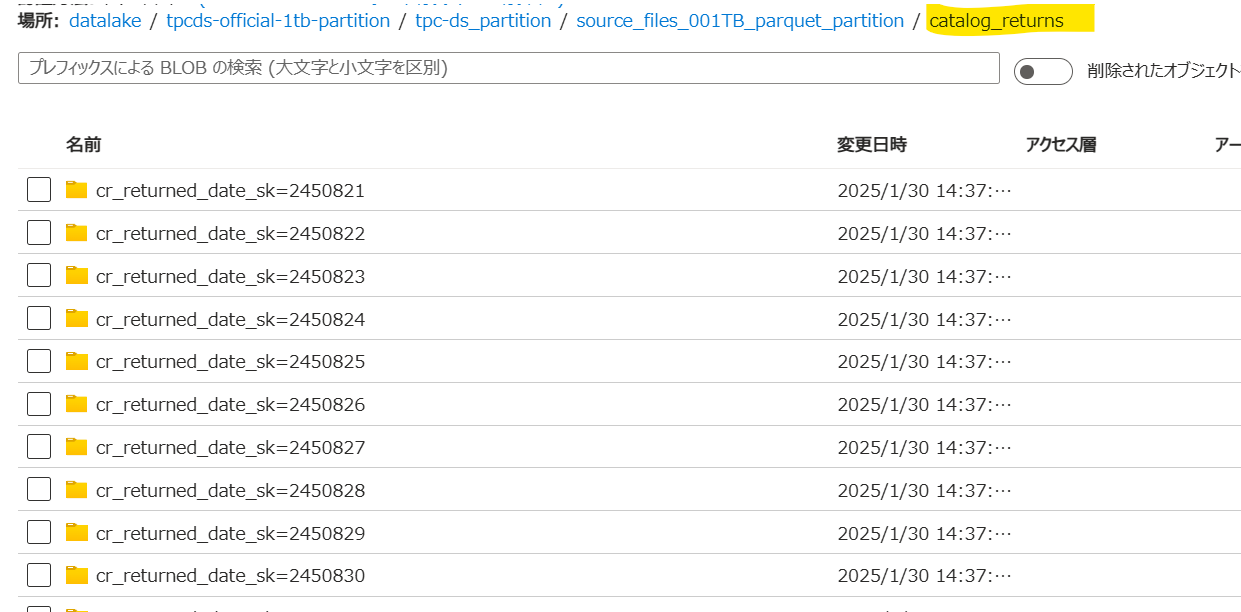
この後ADF等のFor eachアクティビティでループ処理を作りたかったため
各テーブルフォルダ直下にParqetファイルが来るようにしたい。
②partitionTables = false、numPartitions = 1000 の問題点
①を解決するためにTPC-DSのデータセット生成コードを以下に変更し、パーティションなしにしてみた。
%scala
import com.databricks.spark.sql.perf.tpcds.TPCDSTables
// Set:
val scaleFactor = "1000" // scaleFactor defines the size of the dataset to generate (in GB).
val scaleFactoryInt = scaleFactor.toInt
val scaleName = if(scaleFactoryInt < 1000){
f"${scaleFactoryInt}%03d" + "GB"
} else {
f"${scaleFactoryInt / 1000}%03d" + "TB"
}
val fileFormat = "parquet" // valid spark file format like parquet, csv, json.
val rootDir = s"/mnt/datalake/raw/tpc-ds/source_files_${scaleName}_${fileFormat}"
val databaseName = "tpcds" + scaleName // name of database to create.
// Run:
val tables = new TPCDSTables(sqlContext,
dsdgenDir = "/usr/local/bin/tpcds-kit/tools", // location of dsdgen
scaleFactor = scaleFactor,
useDoubleForDecimal = false, // true to replace DecimalType with DoubleType
useStringForDate = false) // true to replace DateType with StringType
tables.genData(
location = rootDir,
format = fileFormat,
overwrite = true, // overwrite the data that is already there
partitionTables = false, // create the partitioned fact tables
clusterByPartitionColumns = false, // shuffle to get partitions coalesced into single files.
filterOutNullPartitionValues = false, // true to filter out the partition with NULL key value
tableFilter = "", // "" means generate all tables
numPartitions = 1000) // how many dsdgen partitions to run - number of input tasks.
// Create the specified database
sql(s"create database IF NOT EXISTS $databaseName")
// Create metastore tables in a specified database for your data.
// Once tables are created, the current database will be switched to the specified database.
tables.createExternalTables(rootDir, fileFormat, databaseName, overwrite = true, discoverPartitions = false)
// Or, if you want to create temporary tables
// tables.createTemporaryTables(location, fileFormat)
// For Cost-based optimizer (CBO) only, gather statistics on all columns:
tables.analyzeTables(databaseName, analyzeColumns = false)
狙い通り各テーブルフォルダ直下にParqetファイルが生成された。

しかし、numPartitions = 1000に設定していたため
Parqetファイルが1000個に分割されていた。そのため、1ファイルあたりのサイズが小さくなっている。
つまり無駄にファイルを分割してしまった。
1Parquetあたり500MiBにするのが理想的だ。
テーブルごとに numPartitions の値を変え、1Parqetファイルあたり500MiBにする。
②の問題を解決するためにテーブルごとに numPartitions の値を変更した
各テーブルのnumnumPartitionsの値を算出したのでテーブルにまとめた。
| テーブル名 | numPartitions | 結果(1ParquetファイルあたりのMiB) |
|---|---|---|
| call_center | いくつでも1ファイルしか作れれない | |
| catalog_page | いくつでも1ファイルしか作れれない | |
| catalog_returns | 20 | 約470 |
| catalog_sales | 200 | 約490 |
| customer | 1 | 604.25 |
| customer_address | 1 | 111.34 |
| customer_demographics | 1 | 7.4 |
| date_dim | いくつでも1ファイルしか作れれない | |
| household_demographics | いくつでも1ファイルしか作れれない | |
| income_band | いくつでも1ファイルしか作れれない | |
| inventory | 6 | 約660 |
| item | いくつでも1ファイルしか作れれない | |
| promotion | いくつでも1ファイルしか作れれない | |
| reason | いくつでも1ファイルしか作れれない | |
| ship_mode | いくつでも1ファイルしか作れれない | |
| store | いくつでも1ファイルしか作れれない | |
| store_returns | 32 | 約440 |
| store_sales | 250 | 約490 |
| time_dim | いくつでも1ファイルしか作れれない | |
| warehouse | いくつでも1ファイルしか作れれない | |
| web_page | いくつでも1ファイルしか作れれない | |
| web_returns | 12 | 約390 |
| web_sales | 90 | 約500 |
| web_site | いくつでも1ファイルしか作れれない |
また、例としてstore_salesのnumPartitions = 250のコードを以下に記載する
%scala
import com.databricks.spark.sql.perf.tpcds.TPCDSTables
// Set:
val scaleFactor = "1000" // scaleFactor defines the size of the dataset to generate (in GB).
val scaleFactoryInt = scaleFactor.toInt
val scaleName = if(scaleFactoryInt < 1000){
f"${scaleFactoryInt}%03d" + "GB"
} else {
f"${scaleFactoryInt / 1000}%03d" + "TB"
}
val fileFormat = "parquet" // valid spark file format like parquet, csv, json.
val tableName = "store_sales"
val rootDir = s"/mnt/datalake/raw/tpc-ds/source_files_${scaleName}_${fileFormat}/${tableName}"
val databaseName = "tpcds" + scaleName // name of database to create.
// Run:
val tables = new TPCDSTables(sqlContext,
dsdgenDir = "/usr/local/bin/tpcds-kit/tools", // location of dsdgen
scaleFactor = scaleFactor,
useDoubleForDecimal = false, // true to replace DecimalType with DoubleType
useStringForDate = false) // true to replace DateType with StringType
// Generate data
tables.genData(
location = rootDir,
format = fileFormat,
overwrite = true, // overwrite the data that is already there
partitionTables = false, // create the partitioned fact tables
clusterByPartitionColumns = false, // shuffle to get partitions coalesced into single files.
filterOutNullPartitionValues = false, // true to filter out the partition with NULL key value
tableFilter = tableName, // "" means generate all tables
numPartitions = 250) // how many dsdgen partitions to run - number of input tasks.
先ほどの表を参考に
tableName とnumPartitionsの値を変えれば好きなテーブルを好きな分割数で生成することができる。
おわりに
以上です。
何か不明点や間違っている点がありましたらコメントいただけますと幸いです。