はじめに
これは、2021年の Ruby アドベントカレンダー2の21日目の記事です。
(日が空いていたので、後から飛び込みました)
そして以下、2021年の Ruby アドベントカレンダー2の3日目の記事『勝手に「点字メーカープログラム」を作ってみる』の続編になります。
元記事は、「挑戦者求む!Rubyで点字メーカープログラムを作ってみよう 〜Qiita Advent Calendar 2021〜」に、勝手に参加したものでしたが、先日、主催者の伊藤淳一さんから追加で以下のような出題がありました。
「こんな問題、余裕で解けるわ!」という上級者には、辛口バージョンも用意しています。
辛口バージョンは何かというと、「がぎぐげご」や「きゃきゅきょ」といった濁音や拗音の点字にもフル対応するバージョンです。
(略)
設計がしっかりしていないと甘口バージョンを辛口バージョンにぱっと対応させるのは難しいんじゃないかなー、と思います。
すぐに解けちゃった、という人はこちらの辛口バージョンにもチャレンジしてみてください!
という訳で、こちらの辛口バージョンもやってみました。
新規実装ではなく、元のコードに対する修正とし、ゴールは以下のテストが通ること、としました。
その他のレギュレーションについては、元の出題と同じで、異常系への対応などは行っていません。
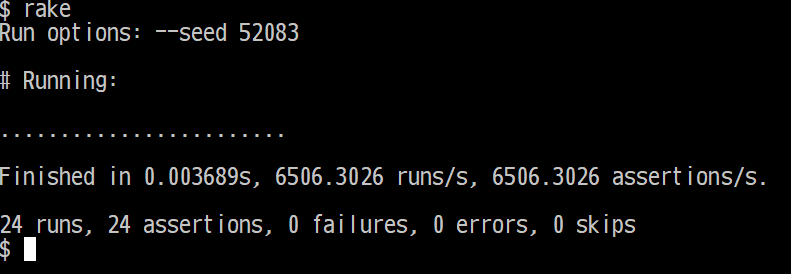
なお、修正後のコードとテストの実行結果は、この記事の末尾に掲載しています。
修正の方針
今回、新たに追加された仕様では、新たに以下の入力が変換対象に加わります。
- を
- 促音(「らっこ」のような、小さな「っ」)
- 長音(「こーもり(こうもり)」のような、伸びる音)
- 濁音(がぎぐげご、など)
- 半濁音(ぱぴぷぺぽ)
- 拗音・拗半濁音(きゃきゅきょ、ぎゃぎゅぎょ、ぴゃぴゅぴょ、など)
このうち、「を」は既に元コードで対応が入っています。また長音についても、単純に点字の追加だけで対応できます。
これ以外は、ローマ字の1語が点字2個に対応しており、いずれも元の点字の前に種類を指定する点字が付く形となっています。
この、種類を指定する点字は、促音・拗音・濁音・半濁音、の4種類です。
なお拗濁音は、拗音と濁音のドットパターンの合成で、また拗半濁音は、拗音と半濁音のドットパターンの合成で、それぞれ実現しています。
元の実装では、ローマ字の1語を点字1個に対応付けて変換していました。このため、新たに促音や濁音など追加対象となるのローマ字に対しては、元の1語から、種類を指定する点字を付与した2語に変換する処理を新規追加することで、以後は元々の処理を用いて1対1で点字へ変換できます。
この修正方針は、元記事の「拡張性」で書いた内容と同じです。
今後、例えば対応するローマ字の種類を増やす場合、「を」や促音、長音については、
TenjiString::DotPatternにて文字数1個への追加で容易に対応可能です。
濁音や拗音への追加対応の場合、点字が2マス使用するので、まずTenjiString側でローマ字での文字列変換処理を新規追加した後、ドットパターンを追加したTenjiString::DotPatternへ渡す流れを考えています
ロジックと実装
新規実装範囲
新たに、TenjiString::Parser クラスを作成して、入力されたローマ字1語に対して、促音や濁音など種類を指定する点字を付与した2語に変換する処理を行います。
ここでは、入力文字列を空白で分割後、促音・拗音・濁音と半濁音、の順で変換処理を行います。変換をこの順序にしているのは理由があります(後述)
促音の変換
促音の変換処理は、TenjiString::Parser::GeminateConsonant クラスで行います。
1語が以下のパターンに合致している場合、促音と見なします。
- 1文字目と2文字目が同じ
- 1文字目が母音ではない
促音を表すプレフィックスとして @ を追加し、元の語からは1文字目を削除しておきます。
拗音の変換
拗音の変換処理は、TenjiString::Parser::ContractedSound クラスで行います。
1語が以下のパターンに合致している場合、拗音と見なします。
- 2文字目が
y - 1文字目が母音ではない
- 3文字目が母音
拗音を表すプレフィックスとして # を追加し、元の語からは2文字目を削除しておきます。
濁音と半濁音の変換
濁音と半濁音の変換処理は、TenjiString::Parser::VoicedSound クラスで行います。
1語が以下のパターンに合致している場合、濁音や半濁音と見なします。
- 1文字目が
qzdbのいずれか(濁音) - 1文字目が
p(半濁音)
濁音の場合はプレフィックスとして * を追加し、元の語の1文字目を対応する子音ksth に書き換えます。
半濁音の場合はプレフィックスとして + を追加し、元の語の1文字目をh に書き換えます。
拗濁音と拗半濁音の変換
ここまでの変換によって、拗濁音と拗半濁音については、プレフィックスが2個並んだ形になっています。
最後に、TenjiString::Parser#concat_double_prefix メソッドでこれらを連結し、2文字のプレフィックス #*(拗濁音) や #+(拗半濁音) に変換します。
各変換の順序から、必ず先に拗音のプレフィックスが来て、後に濁音や半濁音のプレフィックスが続きます。
このため、いったん文字列に戻して、正規表現を使って変換後に、ふたたび配列に直す方法が採れました。
コードの可読性
こうした新規の実装箇所については、上記のロジックをほぼそのまま実装しています。
プレフィックスには、入力文字列に登場しない文字として、記号を使っていますが、可読性は良くありません。これについては、入力をStringクラスではなく、点字の1個に対応した値オブジェクトにする方が良いかもしれません。
また、個々の変換クラスは、よく似た実装になっていますが、共通部分を Module や親クラスに切り出すことは、考えていません。それは DRY の間違った適用だと思います。
個々の変換クラスの内容を見るだけで、必要な情報が全て揃っている方が、理解が容易くなります。
既存コードの修正
ドットパターンに変換する TenjiString::DotPattern クラスでは、新たに増えたプレフィックスを、1文字の対応として追加しています。
併せて、拗濁音と拗半濁音の2文字プレフィックスの場合は、既存の子音と母音のドットパターン合成と同じ仕組みで、新たに合成しています。
修正差分
元のコードを実装する際に、フルセットの点字への修正対応を見越していたため、既存のコードに対する修正箇所は、(新規の追加部分を除くと)とても少なくなっています。
また、今回の修正に際して不要となって削除したコードは、ありません。
参考まで、以下の折り畳みに、修正範囲のみの差分を掲載しておきます。
修正範囲のみを抜粋した差分
diff --git a/lib/tenji_maker.rb b/lib/tenji_maker.rb
index 2239342..3fd1aac 100644
--- a/lib/tenji_maker.rb
+++ b/lib/tenji_maker.rb
@@ -27,7 +27,7 @@ class TenjiString
attr_reader :words, :tenji_string
def parse
- words.downcase.split(' ')
+ Parser.new(words).convert
end
def build
@@ -78,8 +78,19 @@ class TenjiString::DotPattern
]
end
+ def one_letter_word_group
+ [
+ vowel, # 母音
+ repellency, # 撥音
+ long_vowel, # 長音
+ geminate_consonant, # 促音
+ contracted_sound, # 拗音
+ voiced_sound, # 濁音, 半濁音
+ ]
+ end
+
def one_letter_word
- vowel.merge(repellency).fetch(first_char)
+ Hash.new.merge(*one_letter_word_group).fetch(first_char)
end
def two_letter_word
@@ -90,6 +101,7 @@ class TenjiString::DotPattern
{
y: :composition_with_shift,
w: :composition_wa,
+ '#': :composition_contracted_voiced
}.fetch(first_char, :standard_composition)
end
@@ -105,6 +117,10 @@ class TenjiString::DotPattern
consonant_with_shift.fetch(first_char) | shifted_vowel_wa.fetch(second_char)
end
+ def composition_contracted_voiced
+ contracted_sound.fetch(first_char) | voiced_sound.fetch(second_char)
+ end
+
def first_char
word[0].to_sym
end
@@ -168,4 +184,245 @@ class TenjiString::DotPattern
n: 0b0_00_01_11,
}
end
+
+ # 長音
+ def long_vowel
+ {
+ '-': 0b0_00_11_00,
+ }
+ end
+
+ # 促音("っ")
+ def geminate_consonant
+ {
+ '@': 0b0_00_10_00,
+ }
+ end
+
+ # 拗音("ゃ", "ゅ", "ょ")
+ def contracted_sound
+ {
+ '#': 0b0_01_00_00,
+ }
+ end
+
+ # 濁音("゛")と半濁音("゜")
+ def voiced_sound
+ {
+ '*': 0b0_00_01_00, # 濁音
+ '+': 0b0_00_00_01, # 半濁音
+ }
+ end
+end
結果
修正後のコード
class TenjiMaker
def to_tenji(text)
TenjiString.create(text).print_in_dots
end
end
class TenjiString
def self.create(words)
new(words).create
end
def initialize(words, tenji_string = nil)
@words = words
@tenji_string = tenji_string
end
def create
self.class.new(words, build)
end
def print_in_dots
(0..2).map {|line| row_dots(line) }
.join("\n").tr('10', 'o-')
end
private
attr_reader :words, :tenji_string
def parse
Parser.new(words).convert
end
def build
parse.map {|word| DotPattern.create(word) }
end
def row_dots(line)
formatter = ->(dots) { ('%06b' % dots).scan(/../)[line] }
dot_pattern.map(&formatter).join(' ')
end
def dot_pattern
tenji_string.map(&:dot_pattern)
end
end
class TenjiString::DotPattern
def self.create(word)
new(word).create
end
def initialize(word, dot_pattern = nil)
@word = word
@dot_pattern = dot_pattern
end
def create
self.class.new(word, construct_pattern)
end
attr_reader :dot_pattern
private
attr_reader :word
def construct_pattern
method(construct_method).call
end
def construct_method
construct_method_table.prepend(nil).fetch(word.length)
end
def construct_method_table
[
:one_letter_word,
:two_letter_word,
]
end
def one_letter_word_group
[
vowel, # 母音
repellency, # 撥音
long_vowel, # 長音
geminate_consonant, # 促音
contracted_sound, # 拗音
voiced_sound, # 濁音, 半濁音
]
end
def one_letter_word
Hash.new.merge(*one_letter_word_group).fetch(first_char)
end
def two_letter_word
method(two_letter_word_table).call
end
def two_letter_word_table
{
y: :composition_with_shift,
w: :composition_wa,
'#': :composition_contracted_voiced
}.fetch(first_char, :standard_composition)
end
def standard_composition
consonant.fetch(first_char) | vowel.fetch(second_char)
end
def composition_with_shift
consonant_with_shift.fetch(first_char) | shifted_vowel.fetch(second_char)
end
def composition_wa
consonant_with_shift.fetch(first_char) | shifted_vowel_wa.fetch(second_char)
end
def composition_contracted_voiced
contracted_sound.fetch(first_char) | voiced_sound.fetch(second_char)
end
def first_char
word[0].to_sym
end
def second_char
word[1].to_sym
end
# 母音
def vowel
{
a: 0b0_10_00_00,
i: 0b0_10_10_00,
u: 0b0_11_00_00,
e: 0b0_11_10_00,
o: 0b0_01_10_00,
}
end
# 子音
def consonant
{
k: 0b0_00_00_01,
s: 0b0_00_01_01,
t: 0b0_00_01_10,
n: 0b0_00_00_10,
h: 0b0_00_00_11,
m: 0b0_00_01_11,
r: 0b0_00_01_00,
}
end
# 子音(母音が一番下へ移動する)
def consonant_with_shift
{
y: 0b0_01_00_00,
w: 0b0_00_00_00,
}
end
# 母音(一番下へ移動した)
def shifted_vowel
{
a: 0b0_00_00_10,
u: 0b0_00_00_11,
o: 0b0_00_01_10,
}
end
# 母音(わ行専用)
def shifted_vowel_wa
{
a: 0b0_00_00_10,
o: 0b0_00_01_10,
}
end
# 撥音("ん")
def repellency
{
n: 0b0_00_01_11,
}
end
# 長音
def long_vowel
{
'-': 0b0_00_11_00,
}
end
# 促音("っ")
def geminate_consonant
{
'@': 0b0_00_10_00,
}
end
# 拗音("ゃ", "ゅ", "ょ")
def contracted_sound
{
'#': 0b0_01_00_00,
}
end
# 濁音("゛")と半濁音("゜")
def voiced_sound
{
'*': 0b0_00_01_00, # 濁音
'+': 0b0_00_00_01, # 半濁音
}
end
end
class TenjiString::Parser
def initialize(words)
@words = words
end
def convert
concat_double_prefix
end
private
attr_reader :words
def split_by_space
words.downcase.split(' ')
end
def prefix_of_geminate_consonant
split_by_space
.map {|word| GeminateConsonant.new(word).add_prefix }.flatten
end
def prefix_of_contracted_sound
prefix_of_geminate_consonant
.map {|word| ContractedSound.new(word).add_prefix }.flatten
end
def prefix_of_voiced_sound
prefix_of_contracted_sound
.map {|word| VoicedSound.new(word).add_prefix }.flatten
end
def concat_double_prefix
prefix_of_voiced_sound
.join(' ').gsub(/\# ([\*\+])/,'#\1').split(' ')
end
end
class TenjiString::Parser::GeminateConsonant
def initialize(word)
@word = word
end
def add_prefix
geminate_consonant? ? geminate_consonant_pair : word
end
private
attr_reader :word
def first_char
word[0]
end
def second_char
word[1]
end
def word_without_first_char
word.slice(1..-1)
end
def vowel_chars
'aiueo'
end
def geminate_consonant?
first_and_second_char_equal? && !first_char_vowel?
end
def first_and_second_char_equal?
first_char.eql?(second_char)
end
def first_char_vowel?
vowel_chars.include?(first_char)
end
def geminate_consonant_prefix
'@'
end
def geminate_consonant_pair
[geminate_consonant_prefix, word_without_first_char]
end
end
class TenjiString::Parser::ContractedSound
def initialize(word)
@word = word
end
def add_prefix
contracted_sound? ? contracted_sound_pair : word
end
private
attr_reader :word
def first_char
word[0]
end
def second_char
word[1]
end
def third_char
word[2]
end
def vowel_chars
'aiueo'
end
def contracted_sound_char
'y'
end
def contracted_sound_prefix
'#'
end
def word_without_second_char
first_char + third_char
end
def contracted_sound_pair
[contracted_sound_prefix, word_without_second_char]
end
def contracted_sound?
second_char_contracted_sound? && !first_char_vowel? && third_char_vowel?
end
def first_char_vowel?
vowel_chars.include?(first_char)
end
def second_char_contracted_sound?
second_char.eql?(contracted_sound_char)
end
def third_char_vowel?
vowel_chars.include?(third_char)
end
end
class TenjiString::Parser::VoicedSound
def initialize(word)
@word = word
end
def add_prefix
voiced_sound? ? voiced_sound_pair : word
end
private
attr_reader :word
def first_char
word[0].to_sym
end
def second_char
word[1]
end
def voiced_sound_prefix
'*'
end
def semivoiced_sound_prefix
'+'
end
def voiced_sound_prefix_table
{
g: voiced_sound_prefix,
z: voiced_sound_prefix,
d: voiced_sound_prefix,
b: voiced_sound_prefix,
p: semivoiced_sound_prefix,
}
end
def voiced_sound_base_char_table
{
g: 'k',
z: 's',
d: 't',
b: 'h',
p: 'h',
}
end
def voiced_sound_first_chars
voiced_sound_prefix_table.keys
end
def voiced_sound?
voiced_sound_first_chars.include?(first_char)
end
def original_word
voiced_sound_base_char_table.fetch(first_char) + second_char
end
def voiced_sound_pair
[voiced_sound_prefix_table.fetch(first_char), original_word]
end
end
テストの実行結果